 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIAM: Identity-Aware Human Motion and Shape Joint Generation
Apr 28, 2026Recent advances in text-driven human motion generation enable models to synthesize realistic motion sequences from natural language descriptions. However, most existing approaches assume identity-neutral motion and generate movements using a canonical body representation, ignoring the strong influence of body morphology on motion dynamics. In practice, attributes such as body proportions, mass distribution, and age significantly affect how actions are performed, and neglecting this coupling often leads to physically inconsistent motions. We propose an identity-aware motion generation framework that explicitly models the relationship between body morphology and motion dynamics. Instead of relying on explicit geometric measurements, identity is represented using multimodal signals, including natural language descriptions and visual cues. We further introduce a joint motion-shape generation paradigm that simultaneously synthesizes motion sequences and body shape parameters, allowing identity cues to directly modulate motion dynamics. Extensive experiments on motion capture datasets and large-scale in-the-wild videos demonstrate improved motion realism and motion-identity consistency while maintaining high motion quality. Project page: https://vjwq.github.io/IAM
EgoForge: Goal-Directed Egocentric World Simulator
Mar 20, 2026Generative world models have shown promise for simulating dynamic environments, yet egocentric video remains challenging due to rapid viewpoint changes, frequent hand-object interactions, and goal-directed procedures whose evolution depends on latent human intent. Existing approaches either focus on hand-centric instructional synthesis with limited scene evolution, perform static view translation without modeling action dynamics, or rely on dense supervision, such as camera trajectories, long video prefixes, synchronized multicamera capture, etc. In this work, we introduce EgoForge, an egocentric goal-directed world simulator that generates coherent, first-person video rollouts from minimal static inputs: a single egocentric image, a high-level instruction, and an optional auxiliary exocentric view. To improve intent alignment and temporal consistency, we propose VideoDiffusionNFT, a trajectory-level reward-guided refinement that optimizes goal completion, temporal causality, scene consistency, and perceptual fidelity during diffusion sampling. Extensive experiments show EgoForge achieves consistent gains in semantic alignment, geometric stability, and motion fidelity over strong baselines, and robust performance in real-world smart-glasses experiments.
SocialGesture: Delving into Multi-person Gesture Understanding
Apr 03, 2025Previous research in human gesture recognition has largely overlooked multi-person interactions, which are crucial for understanding the social context of naturally occurring gestures. This limitation in existing datasets presents a significant challenge in aligning human gestures with other modalities like language and speech. To address this issue, we introduce SocialGesture, the first large-scale dataset specifically designed for multi-person gesture analysis. SocialGesture features a diverse range of natural scenarios and supports multiple gesture analysis tasks, including video-based recognition and temporal localization, providing a valuable resource for advancing the study of gesture during complex social interactions. Furthermore, we propose a novel visual question answering (VQA) task to benchmark vision language models'(VLMs) performance on social gesture understanding. Our findings highlight several limitations of current gesture recognition models, offering insights into future directions for improvement in this field. SocialGesture is available at huggingface.co/datasets/IrohXu/SocialGesture.
Learning Predictive Visuomotor Coordination
Mar 30, 2025Understanding and predicting human visuomotor coordination is crucial for applications in robotics, human-computer interaction, and assistive technologies. This work introduces a forecasting-based task for visuomotor modeling, where the goal is to predict head pose, gaze, and upper-body motion from egocentric visual and kinematic observations. We propose a \textit{Visuomotor Coordination Representation} (VCR) that learns structured temporal dependencies across these multimodal signals. We extend a diffusion-based motion modeling framework that integrates egocentric vision and kinematic sequences, enabling temporally coherent and accurate visuomotor predictions. Our approach is evaluated on the large-scale EgoExo4D dataset, demonstrating strong generalization across diverse real-world activities. Our results highlight the importance of multimodal integration in understanding visuomotor coordination, contributing to research in visuomotor learning and human behavior modeling.
GaussianSpa: An "Optimizing-Sparsifying" Simplification Framework for Compact and High-Quality 3D Gaussian Splatting
Nov 09, 2024



3D Gaussian Splatting (3DGS) has emerged as a mainstream for novel view synthesis, leveraging continuous aggregations of Gaussian functions to model scene geometry. However, 3DGS suffers from substantial memory requirements to store the multitude of Gaussians, hindering its practicality. To address this challenge, we introduce GaussianSpa, an optimization-based simplification framework for compact and high-quality 3DGS. Specifically, we formulate the simplification as an optimization problem associated with the 3DGS training. Correspondingly, we propose an efficient "optimizing-sparsifying" solution that alternately solves two independent sub-problems, gradually imposing strong sparsity onto the Gaussians in the training process. Our comprehensive evaluations on various datasets show the superiority of GaussianSpa over existing state-of-the-art approaches. Notably, GaussianSpa achieves an average PSNR improvement of 0.9 dB on the real-world Deep Blending dataset with 10$\times$ fewer Gaussians compared to the vanilla 3DGS. Our project page is available at https://gaussianspa.github.io/.
MoE-I$^2$: Compressing Mixture of Experts Models through Inter-Expert Pruning and Intra-Expert Low-Rank Decomposition
Nov 01, 2024

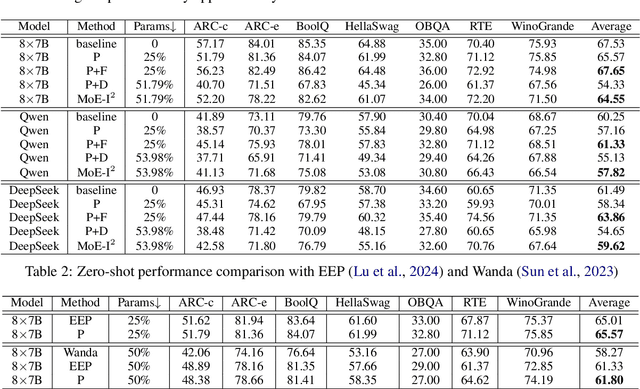
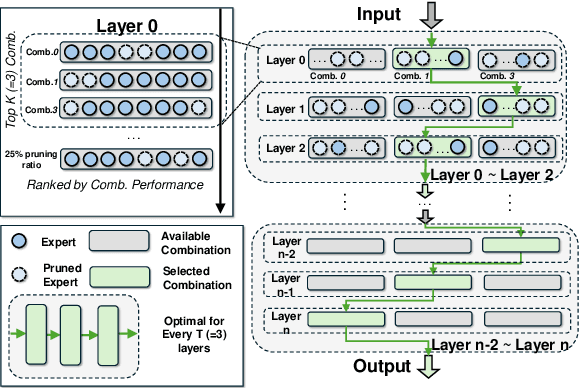
The emergence of Mixture of Experts (MoE) LLMs has significantly advanced the development of language models. Compared to traditional LLMs, MoE LLMs outperform traditional LLMs by achieving higher performance with considerably fewer activated parameters. Despite this efficiency, their enormous parameter size still leads to high deployment costs. In this paper, we introduce a two-stage compression method tailored for MoE to reduce the model size and decrease the computational cost. First, in the inter-expert pruning stage, we analyze the importance of each layer and propose the Layer-wise Genetic Search and Block-wise KT-Reception Field with the non-uniform pruning ratio to prune the individual expert. Second, in the intra-expert decomposition stage, we apply the low-rank decomposition to further compress the parameters within the remaining experts. Extensive experiments on Qwen1.5-MoE-A2.7B, DeepSeek-V2-Lite, and Mixtral-8$\times$7B demonstrate that our proposed methods can both reduce the model size and enhance inference efficiency while maintaining performance in various zero-shot tasks. The code will be available at \url{https://github.com/xiaochengsky/MoEI-2.git}
Enhancing Lossy Compression Through Cross-Field Information for Scientific Applications
Sep 26, 2024



Lossy compression is one of the most effective methods for reducing the size of scientific data containing multiple data fields. It reduces information density through prediction or transformation techniques to compress the data. Previous approaches use local information from a single target field when predicting target data points, limiting their potential to achieve higher compression ratios. In this paper, we identified significant cross-field correlations within scientific datasets. We propose a novel hybrid prediction model that utilizes CNN to extract cross-field information and combine it with existing local field information. Our solution enhances the prediction accuracy of lossy compressors, leading to improved compression ratios without compromising data quality. We evaluate our solution on three scientific datasets, demonstrating its ability to improve compression ratios by up to 25% under specific error bounds. Additionally, our solution preserves more data details and reduces artifacts compared to baseline approaches.
NeurLZ: On Enhancing Lossy Compression Performance based on Error-Controlled Neural Learning for Scientific Data
Sep 10, 2024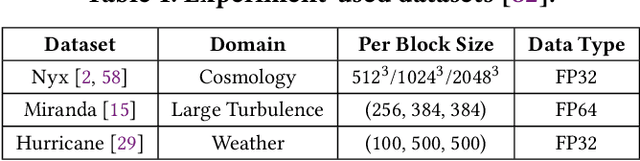



Large-scale scientific simulations generate massive datasets that pose significant challenges for storage and I/O. While traditional lossy compression techniques can improve performance, balancing compression ratio, data quality, and throughput remains difficult. To address this, we propose NeurLZ, a novel cross-field learning-based and error-controlled compression framework for scientific data. By integrating skipping DNN models, cross-field learning, and error control, our framework aims to substantially enhance lossy compression performance. Our contributions are three-fold: (1) We design a lightweight skipping model to provide high-fidelity detail retention, further improving prediction accuracy. (2) We adopt a cross-field learning approach to significantly improve data prediction accuracy, resulting in a substantially improved compression ratio. (3) We develop an error control approach to provide strict error bounds according to user requirements. We evaluated NeurLZ on several real-world HPC application datasets, including Nyx (cosmological simulation), Miranda (large turbulence simulation), and Hurricane (weather simulation). Experiments demonstrate that our framework achieves up to a 90% relative reduction in bit rate under the same data distortion, compared to the best existing approach.
Leveraging Object Priors for Point Tracking
Sep 09, 2024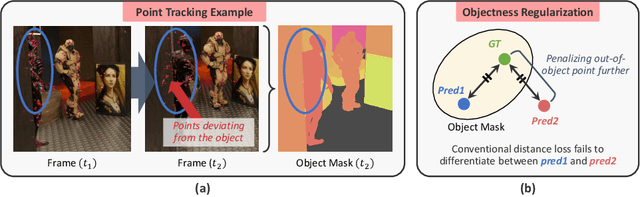
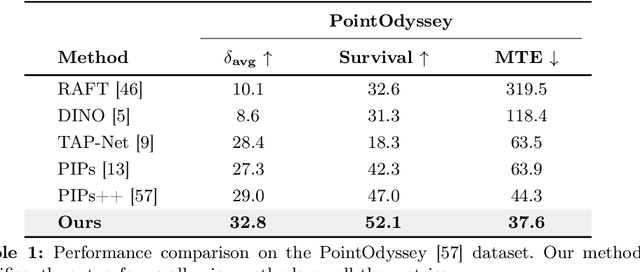
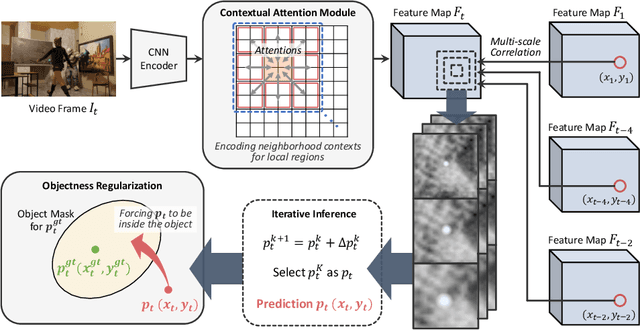

Point tracking is a fundamental problem in computer vision with numerous applications in AR and robotics. A common failure mode in long-term point tracking occurs when the predicted point leaves the object it belongs to and lands on the background or another object. We identify this as the failure to correctly capture objectness properties in learning to track. To address this limitation of prior work, we propose a novel objectness regularization approach that guides points to be aware of object priors by forcing them to stay inside the the boundaries of object instances. By capturing objectness cues at training time, we avoid the need to compute object masks during testing. In addition, we leverage contextual attention to enhance the feature representation for capturing objectness at the feature level more effectively. As a result, our approach achieves state-of-the-art performance on three point tracking benchmarks, and we further validate the effectiveness of our components via ablation studies. The source code is available at: https://github.com/RehgLab/tracking_objectness
GWLZ: A Group-wise Learning-based Lossy Compression Framework for Scientific Data
Apr 20, 2024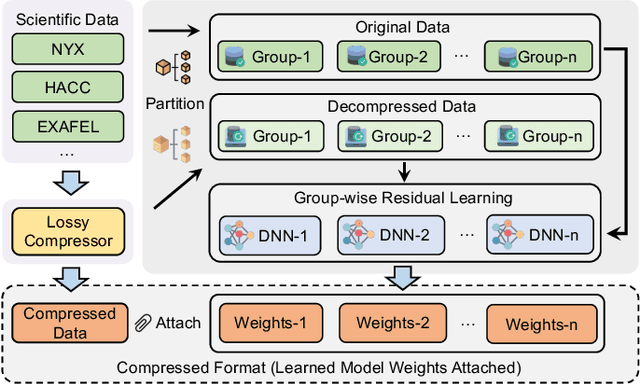

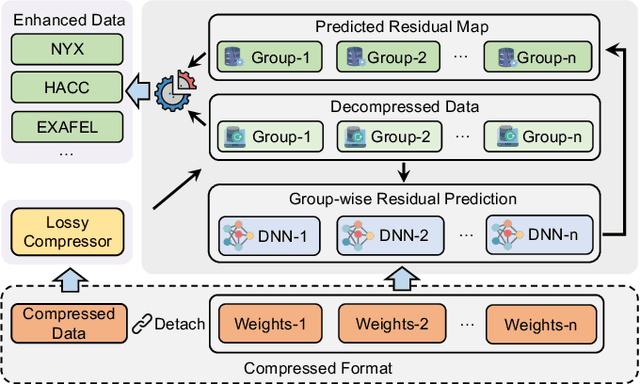
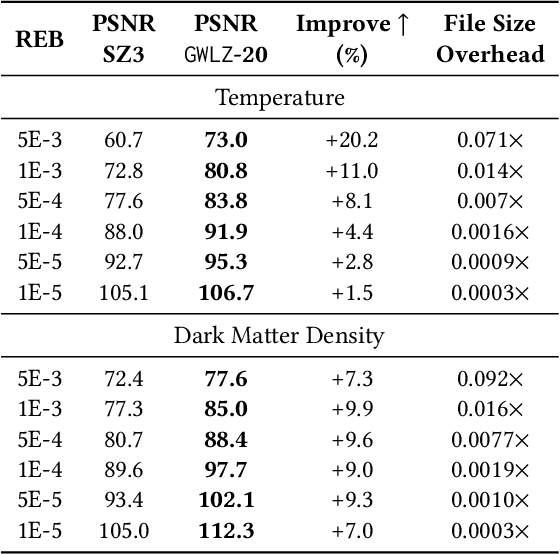
The rapid expansion of computational capabilities and the ever-growing scale of modern HPC systems present formidable challenges in managing exascale scientific data. Faced with such vast datasets, traditional lossless compression techniques prove insufficient in reducing data size to a manageable level while preserving all information intact. In response, researchers have turned to error-bounded lossy compression methods, which offer a balance between data size reduction and information retention. However, despite their utility, these compressors employing conventional techniques struggle with limited reconstruction quality. To address this issue, we draw inspiration from recent advancements in deep learning and propose GWLZ, a novel group-wise learning-based lossy compression framework with multiple lightweight learnable enhancer models. Leveraging a group of neural networks, GWLZ significantly enhances the decompressed data reconstruction quality with negligible impact on the compression efficiency. Experimental results on different fields from the Nyx dataset demonstrate remarkable improvements by GWLZ, achieving up to 20% quality enhancements with negligible overhead as low as 0.0003x.