 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Audio-Visual Conversational Graph: From an Egocentric-Exocentric Perspective
Paper and Code
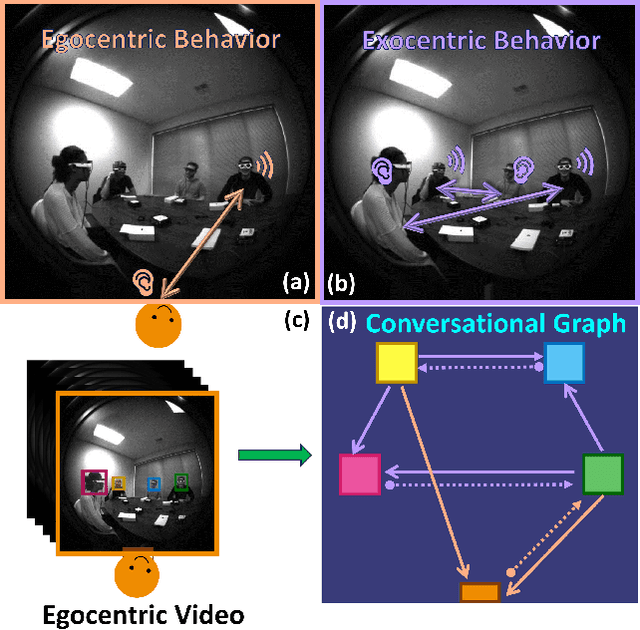
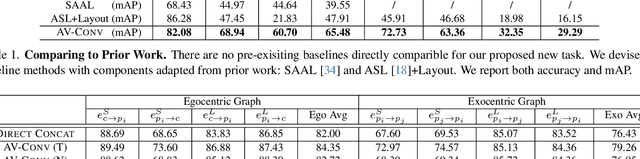
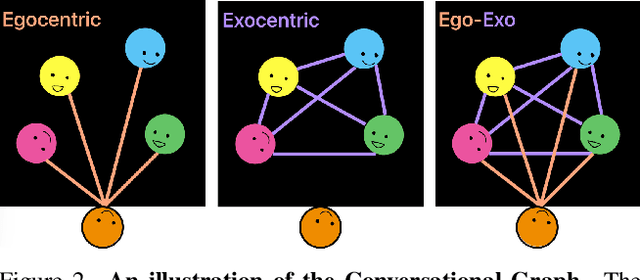
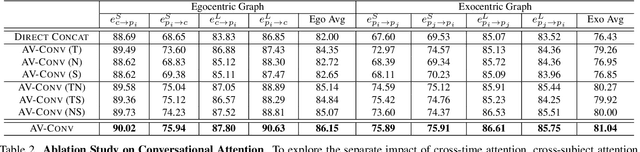
In recent years, the thriving development of research related to egocentric videos has provided a unique perspective for the study of conversational interactions, where both visual and audio signals play a crucial role. While most prior work focus on learning about behaviors that directly involve the camera wearer, we introduce the Ego-Exocentric Conversational Graph Prediction problem, marking the first attempt to infer exocentric conversational interactions from egocentric videos. We propose a unified multi-modal, multi-task framework -- Audio-Visual Conversational Attention (Av-CONV), for the joint prediction of conversation behaviors -- speaking and listening -- for both the camera wearer as well as all other social partners present in the egocentric video. Specifically, we customize the self-attention mechanism to model the representations across-time, across-subjects, and across-modalities. To validate our method, we conduct experiments on a challenging egocentric video dataset that includes first-person perspective, multi-speaker, and multi-conversation scenarios. Our results demonstrate the superior performance of our method compared to a series of baselines. We also present detailed ablation studies to assess the contribution of each component in our model. Project page: https://vjwq.github.io/AV-CONV/.