 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-to-Stage: Spatial Layouts from Long-form Narratives
Mar 18, 2026In this work, we probe the ability of a language model to demonstrate spatial reasoning from unstructured text, mimicking human capabilities and automating a process that benefits many downstream media applications. Concretely, we study the narrative-to-play task: inferring stage-play layouts (scenes, speaker positions, movements, and room types) from text that lacks explicit spatial, positional, or relational cues. We then introduce a dramaturgy-inspired deterministic evaluation suite and, finally, a training and inference recipe that combines rejection SFT using Best-of-N sampling with RL from verifiable rewards via GRPO. Experiments on a text-only corpus of classical English literature demonstrate improvements over vanilla models across multiple metrics (character attribution, spatial plausibility, and movement economy), as well as alignment with an LLM-as-a-judge and subjective human preferences.
Towards Perception-Informed Latent HRTF Representations
Jul 03, 2025Personalized head-related transfer functions (HRTFs) are essential for ensuring a realistic auditory experience over headphones, because they take into account individual anatomical differences that affect listening. Most machine learning approaches to HRTF personalization rely on a learned low-dimensional latent space to generate or select custom HRTFs for a listener. However, these latent representations are typically learned in a manner that optimizes for spectral reconstruction but not for perceptual compatibility, meaning they may not necessarily align with perceptual distance. In this work, we first study whether traditionally learned HRTF representations are well correlated with perceptual relations using auditory-based objective perceptual metrics; we then propose a method for explicitly embedding HRTFs into a perception-informed latent space, leveraging a metric-based loss function and supervision via Metric Multidimensional Scaling (MMDS). Finally, we demonstrate the applicability of these learned representations to the task of HRTF personalization. We suggest that our method has the potential to render personalized spatial audio, leading to an improved listening experience.
Hearing Anywhere in Any Environment
Apr 14, 2025In mixed reality applications, a realistic acoustic experience in spatial environments is as crucial as the visual experience for achieving true immersion. Despite recent advances in neural approaches for Room Impulse Response (RIR) estimation, most existing methods are limited to the single environment on which they are trained, lacking the ability to generalize to new rooms with different geometries and surface materials. We aim to develop a unified model capable of reconstructing the spatial acoustic experience of any environment with minimum additional measurements. To this end, we present xRIR, a framework for cross-room RIR prediction. The core of our generalizable approach lies in combining a geometric feature extractor, which captures spatial context from panorama depth images, with a RIR encoder that extracts detailed acoustic features from only a few reference RIR samples. To evaluate our method, we introduce ACOUSTICROOMS, a new dataset featuring high-fidelity simulation of over 300,000 RIRs from 260 rooms. Experiments show that our method strongly outperforms a series of baselines. Furthermore, we successfully perform sim-to-real transfer by evaluating our model on four real-world environments, demonstrating the generalizability of our approach and the realism of our dataset.
SoundVista: Novel-View Ambient Sound Synthesis via Visual-Acoustic Binding
Apr 08, 2025



We introduce SoundVista, a method to generate the ambient sound of an arbitrary scene at novel viewpoints. Given a pre-acquired recording of the scene from sparsely distributed microphones, SoundVista can synthesize the sound of that scene from an unseen target viewpoint. The method learns the underlying acoustic transfer function that relates the signals acquired at the distributed microphones to the signal at the target viewpoint, using a limited number of known recordings. Unlike existing works, our method does not require constraints or prior knowledge of sound source details. Moreover, our method efficiently adapts to diverse room layouts, reference microphone configurations and unseen environments. To enable this, we introduce a visual-acoustic binding module that learns visual embeddings linked with local acoustic properties from panoramic RGB and depth data. We first leverage these embeddings to optimize the placement of reference microphones in any given scene. During synthesis, we leverage multiple embeddings extracted from reference locations to get adaptive weights for their contribution, conditioned on target viewpoint. We benchmark the task on both publicly available data and real-world settings. We demonstrate significant improvements over existing methods.
Novel View Acoustic Parameter Estimation
Oct 31, 2024

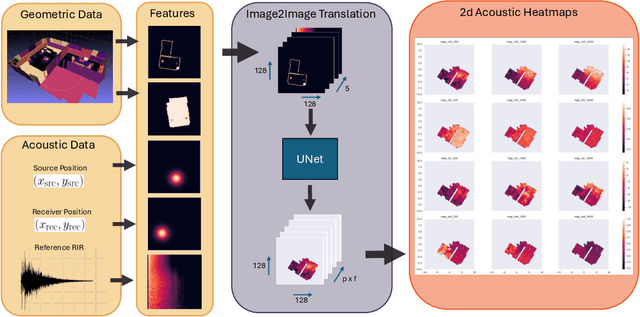
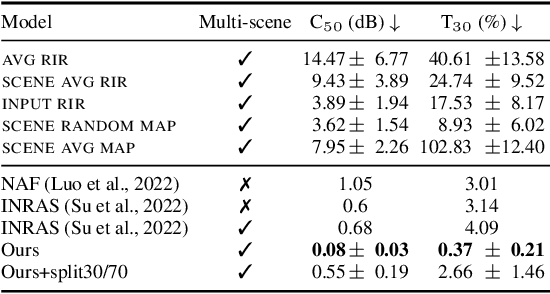
The task of Novel View Acoustic Synthesis (NVAS) - generating Room Impulse Responses (RIRs) for unseen source and receiver positions in a scene - has recently gained traction, especially given its relevance to Augmented Reality (AR) and Virtual Reality (VR) development. However, many of these efforts suffer from similar limitations: they infer RIRs in the time domain, which prove challenging to optimize; they focus on scenes with simple, single-room geometries; they infer only single-channel, directionally-independent acoustic characteristics; and they require inputs, such as 3D geometry meshes with material properties, that may be impractical to obtain for on-device applications. On the other hand, research suggests that sample-wise accuracy of RIRs is not required for perceptual plausibility in AR and VR. Standard acoustic parameters like Clarity Index (C50) or Reverberation Time (T60) have been shown to capably describe pertinent characteristics of the RIRs, especially late reverberation. To address these gaps, this paper introduces a new task centered on estimating spatially distributed acoustic parameters that can be then used to condition a simple reverberator for arbitrary source and receiver positions. The approach is modelled as an image-to-image translation task, which translates 2D floormaps of a scene into 2D heatmaps of acoustic parameters. We introduce a new, large-scale dataset of 1000 scenes consisting of complex, multi-room apartment conditions, and show that our method outperforms statistical baselines significantly. Moreover, we show that the method also works for directionally-dependent (i.e. beamformed) parameter prediction. Finally, the proposed method operates on very limited information, requiring only a broad outline of the scene and a single RIR at inference time.
Spherical World-Locking for Audio-Visual Localization in Egocentric Videos
Aug 09, 2024
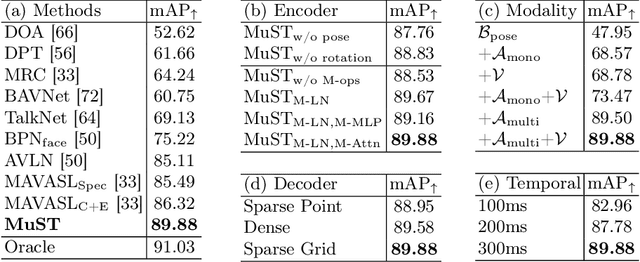


Egocentric videos provide comprehensive contexts for user and scene understanding, spanning multisensory perception to behavioral interaction. We propose Spherical World-Locking (SWL) as a general framework for egocentric scene representation, which implicitly transforms multisensory streams with respect to measurements of head orientation. Compared to conventional head-locked egocentric representations with a 2D planar field-of-view, SWL effectively offsets challenges posed by self-motion, allowing for improved spatial synchronization between input modalities. Using a set of multisensory embeddings on a worldlocked sphere, we design a unified encoder-decoder transformer architecture that preserves the spherical structure of the scene representation, without requiring expensive projections between image and world coordinate systems. We evaluate the effectiveness of the proposed framework on multiple benchmark tasks for egocentric video understanding, including audio-visual active speaker localization, auditory spherical source localization, and behavior anticipation in everyday activities.
On HRTF Notch Frequency Prediction Using Anthropometric Features and Neural Networks
Mar 12, 2024
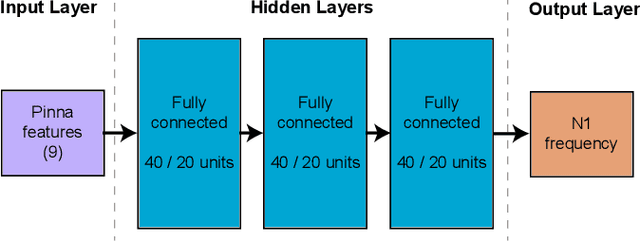

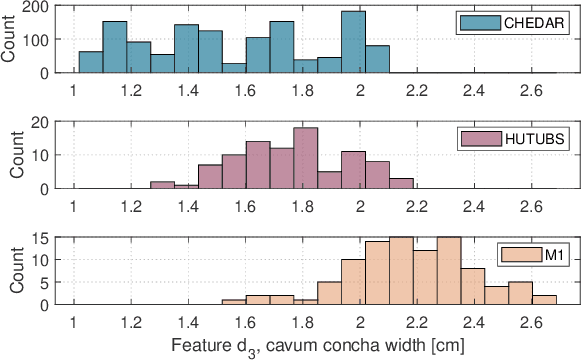
High fidelity spatial audio often performs better when produced using a personalized head-related transfer function (HRTF). However, the direct acquisition of HRTFs is cumbersome and requires specialized equipment. Thus, many personalization methods estimate HRTF features from easily obtained anthropometric features of the pinna, head, and torso. The first HRTF notch frequency (N1) is known to be a dominant feature in elevation localization, and thus a useful feature for HRTF personalization. This paper describes the prediction of N1 frequency from pinna anthropometry using a neural model. Prediction is performed separately on three databases, both simulated and measured, and then by domain mixing in-between the databases. The model successfully predicts N1 frequency for individual databases and by domain mixing between some databases. Prediction errors are better or comparable to those previously reported, showing significant improvement when acquired over a large database and with a larger output range.
Hearing Loss Detection from Facial Expressions in One-on-one Conversations
Jan 17, 2024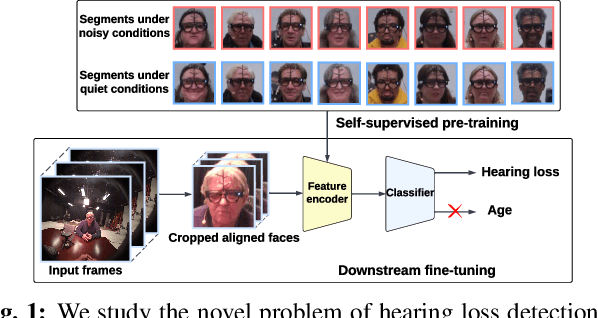
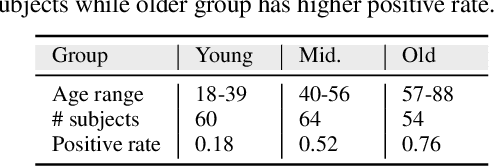
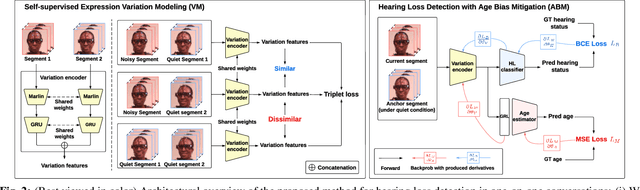
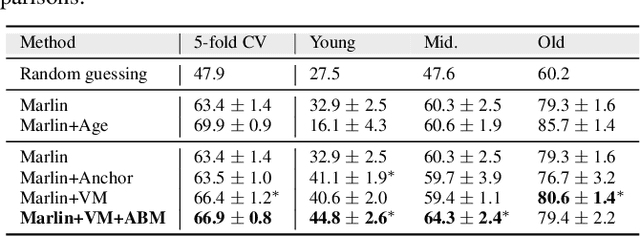
Individuals with impaired hearing experience difficulty in conversations, especially in noisy environments. This difficulty often manifests as a change in behavior and may be captured via facial expressions, such as the expression of discomfort or fatigue. In this work, we build on this idea and introduce the problem of detecting hearing loss from an individual's facial expressions during a conversation. Building machine learning models that can represent hearing-related facial expression changes is a challenge. In addition, models need to disentangle spurious age-related correlations from hearing-driven expressions. To this end, we propose a self-supervised pre-training strategy tailored for the modeling of expression variations. We also use adversarial representation learning to mitigate the age bias. We evaluate our approach on a large-scale egocentric dataset with real-world conversational scenarios involving subjects with hearing loss and show that our method for hearing loss detection achieves superior performance over baselines.
The Audio-Visual Conversational Graph: From an Egocentric-Exocentric Perspective
Dec 20, 2023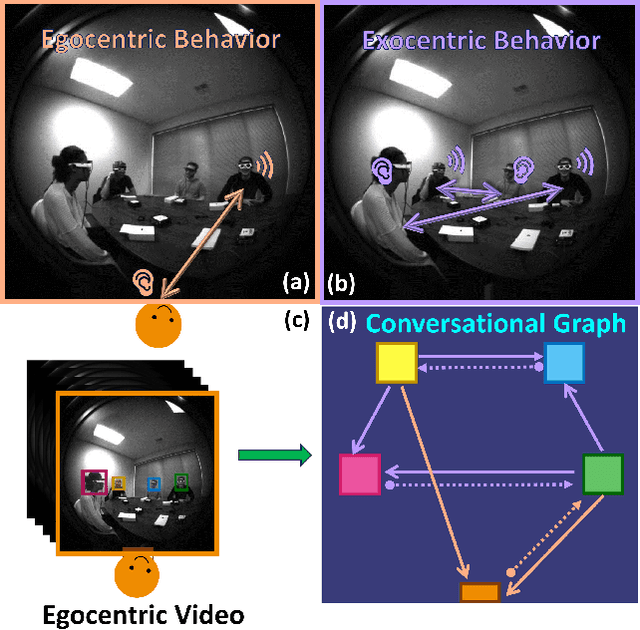
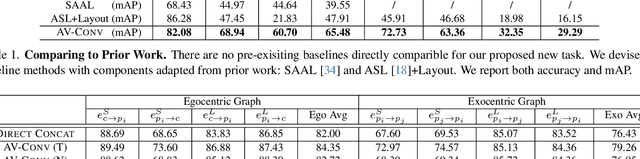
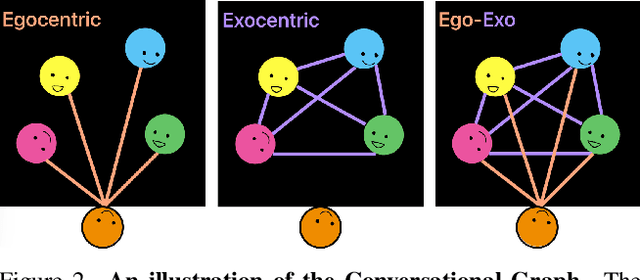
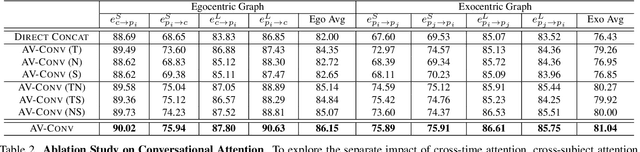
In recent years, the thriving development of research related to egocentric videos has provided a unique perspective for the study of conversational interactions, where both visual and audio signals play a crucial role. While most prior work focus on learning about behaviors that directly involve the camera wearer, we introduce the Ego-Exocentric Conversational Graph Prediction problem, marking the first attempt to infer exocentric conversational interactions from egocentric videos. We propose a unified multi-modal, multi-task framework -- Audio-Visual Conversational Attention (Av-CONV), for the joint prediction of conversation behaviors -- speaking and listening -- for both the camera wearer as well as all other social partners present in the egocentric video. Specifically, we customize the self-attention mechanism to model the representations across-time, across-subjects, and across-modalities. To validate our method, we conduct experiments on a challenging egocentric video dataset that includes first-person perspective, multi-speaker, and multi-conversation scenarios. Our results demonstrate the superior performance of our method compared to a series of baselines. We also present detailed ablation studies to assess the contribution of each component in our model. Project page: https://vjwq.github.io/AV-CONV/.
Towards Improved Room Impulse Response Estimation for Speech Recognition
Nov 08, 2022



We propose to characterize and improve the performance of blind room impulse response (RIR) estimation systems in the context of a downstream application scenario, far-field automatic speech recognition (ASR). We first draw the connection between improved RIR estimation and improved ASR performance, as a means of evaluating neural RIR estimators. We then propose a GAN-based architecture that encodes RIR features from reverberant speech and constructs an RIR from the encoded features, and uses a novel energy decay relief loss to optimize for capturing energy-based properties of the input reverberant speech. We show that our model outperforms the state-of-the-art baselines on acoustic benchmarks (by 72% on the energy decay relief and 22% on an early-reflection energy metric), as well as in an ASR evaluation task (by 6.9% in word error rate).