 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialNet with Binaural Loss Function for Correcting Binaural Signal Matching Outputs under Head Rotations
Dec 23, 2025Binaural reproduction is gaining increasing attention with the rise of devices such as virtual reality headsets, smart glasses, and head-tracked headphones. Achieving accurate binaural signals with these systems is challenging, as they often employ arbitrary microphone arrays with limited spatial resolution. The Binaural Signals Matching with Magnitude Least-Squares (BSM-MagLS) method was developed to address limitations of earlier BSM formulations, improving reproduction at high frequencies and under head rotation. However, its accuracy still degrades as head rotation increases, resulting in spatial and timbral artifacts, particularly when the virtual listener's ear moves farther from the nearest microphones. In this work, we propose the integration of deep learning with BSM-MagLS to mitigate these degradations. A post-processing framework based on the SpatialNet network is employed, leveraging its ability to process spatial information effectively and guided by both signal-level loss and a perceptually motivated binaural loss derived from a theoretical model of human binaural hearing. The effectiveness of the approach is investigated in a simulation study with a six-microphone semicircular array, showing its ability to perform robustly across head rotations. These findings are further studied in a listening experiment across different reverberant acoustic environments and head rotations, demonstrating that the proposed framework effectively mitigates BSM-MagLS degradations and provides robust correction across substantial head rotations.
HyBeam: Hybrid Microphone-Beamforming Array-Agnostic Speech Enhancement for Wearables
Oct 26, 2025Speech enhancement is a fundamental challenge in signal processing, particularly when robustness is required across diverse acoustic conditions and microphone setups. Deep learning methods have been successful for speech enhancement, but often assume fixed array geometries, limiting their use in mobile, embedded, and wearable devices. Existing array-agnostic approaches typically rely on either raw microphone signals or beamformer outputs, but both have drawbacks under changing geometries. We introduce HyBeam, a hybrid framework that uses raw microphone signals at low frequencies and beamformer signals at higher frequencies, exploiting their complementary strengths while remaining highly array-agnostic. Simulations across diverse rooms and wearable array configurations demonstrate that HyBeam consistently surpasses microphone-only and beamformer-only baselines in PESQ, STOI, and SI-SDR. A bandwise analysis shows that the hybrid approach leverages beamformer directivity at high frequencies and microphone cues at low frequencies, outperforming either method alone across all bands.
SRP-PHAT-NET: A Reliability-Driven DNN for Reverberant Speaker Localization
Oct 26, 2025

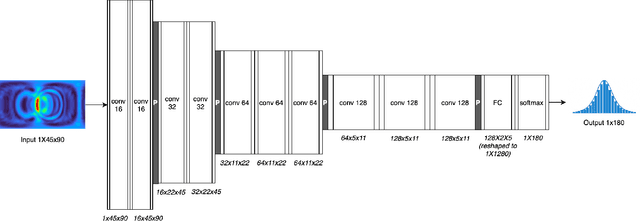

Accurate Direction-of-Arrival (DOA) estimation in reverberant environments remains a fundamental challenge for spatial audio applications. While deep learning methods have shown strong performance in such conditions, they typically lack a mechanism to assess the reliability of their predictions - an essential feature for real-world deployment. In this work, we present the SRP-PHAT-NET, a deep neural network framework that leverages SRP-PHAT directional maps as spatial features and introduces a built-in reliability estimation. To enable meaningful reliability scoring, the model is trained using Gaussian-weighted labels centered around the true direction. We systematically analyze the influence of label smoothing on accuracy and reliability, demonstrating that the choice of Gaussian kernel width can be tuned to application-specific requirements. Experimental results show that selectively using high-confidence predictions yields significantly improved localization accuracy, highlighting the practical benefits of integrating reliability into deep learning-based DOA estimation.
AmbiDrop: Array-Agnostic Speech Enhancement Using Ambisonics Encoding and Dropout-Based Learning
Sep 18, 2025
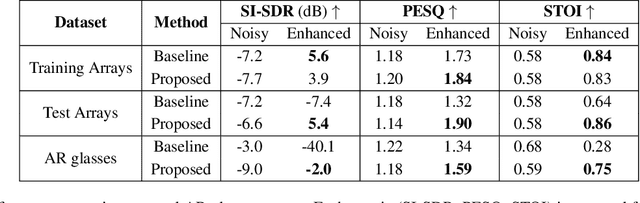
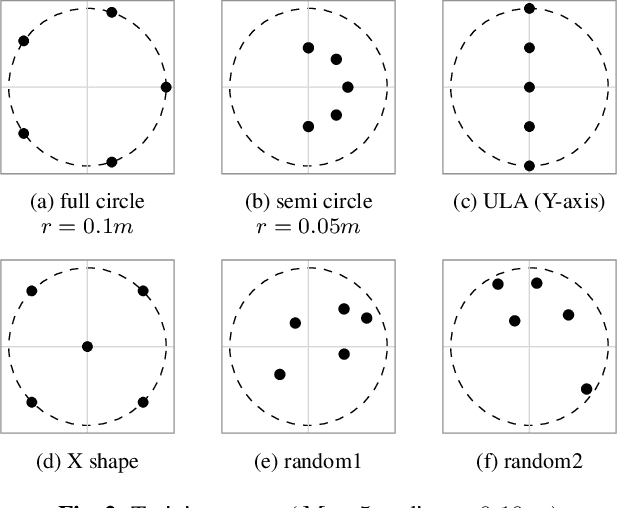
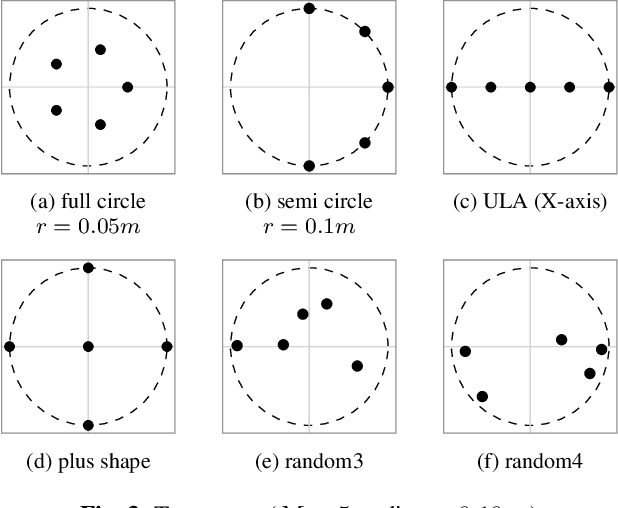
Multichannel speech enhancement leverages spatial cues to improve intelligibility and quality, but most learning-based methods rely on specific microphone array geometry, unable to account for geometry changes. To mitigate this limitation, current array-agnostic approaches employ large multi-geometry datasets but may still fail to generalize to unseen layouts. We propose AmbiDrop (Ambisonics with Dropouts), an Ambisonics-based framework that encodes arbitrary array recordings into the spherical harmonics domain using Ambisonics Signal Matching (ASM). A deep neural network is trained on simulated Ambisonics data, combined with channel dropout for robustness against array-dependent encoding errors, therefore omitting the need for a diverse microphone array database. Experiments show that while the baseline and proposed models perform similarly on the training arrays, the baseline degrades on unseen arrays. In contrast, AmbiDrop consistently improves SI-SDR, PESQ, and STOI, demonstrating strong generalization and practical potential for array-agnostic speech enhancement.
Loss functions incorporating auditory spatial perception in deep learning -- a review
Jun 24, 2025Binaural reproduction aims to deliver immersive spatial audio with high perceptual realism over headphones. Loss functions play a central role in optimizing and evaluating algorithms that generate binaural signals. However, traditional signal-related difference measures often fail to capture the perceptual properties that are essential to spatial audio quality. This review paper surveys recent loss functions that incorporate spatial perception cues relevant to binaural reproduction. It focuses on losses applied to binaural signals, which are often derived from microphone recordings or Ambisonics signals, while excluding those based on room impulse responses. Guided by the Spatial Audio Quality Inventory (SAQI), the review emphasizes perceptual dimensions related to source localization and room response, while excluding general spectral-temporal attributes. The literature survey reveals a strong focus on localization cues, such as interaural time and level differences (ITDs, ILDs), while reverberation and other room acoustic attributes remain less explored in loss function design. Recent works that estimate room acoustic parameters and develop embeddings that capture room characteristics indicate their potential for future integration into neural network training. The paper concludes by highlighting future research directions toward more perceptually grounded loss functions that better capture the listener's spatial experience.
BSM-iMagLS: ILD Informed Binaural Signal Matching for Reproduction with Head-Mounted Microphone Arrays
Jan 30, 2025

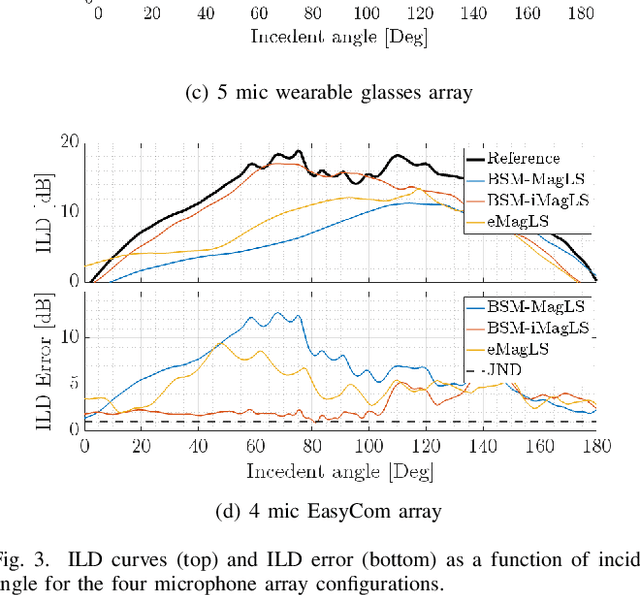

Headphone listening in applications such as augmented and virtual reality (AR and VR) relies on high-quality spatial audio to ensure immersion, making accurate binaural reproduction a critical component. As capture devices, wearable arrays with only a few microphones with irregular arrangement face challenges in achieving a reproduction quality comparable to that of arrays with a large number of microphones. Binaural signal matching (BSM) has recently been presented as a signal-independent approach for generating high-quality binaural signal using only a few microphones, which is further improved using magnitude-least squares (MagLS) optimization at high frequencies. This paper extends BSM with MagLS by introducing interaural level difference (ILD) into the MagLS, integrated into BSM (BSM-iMagLS). Using a deep neural network (DNN)-based solver, BSM-iMagLS achieves joint optimization of magnitude, ILD, and magnitude derivatives, improving spatial fidelity. Performance is validated through theoretical analysis, numerical simulations with diverse HRTFs and head-mounted array geometries, and listening experiments, demonstrating a substantial reduction in ILD errors while maintaining comparable magnitude accuracy to state-of-the-art solutions. The results highlight the potential of BSM-iMagLS to enhance binaural reproduction for wearable and portable devices.
Ambisonics Binaural Rendering via Masked Magnitude Least Squares
Jan 30, 2025



Ambisonics rendering has become an integral part of 3D audio for headphones. It works well with existing recording hardware, the processing cost is mostly independent of the number of sound sources, and it elegantly allows for rotating the scene and listener. One challenge in Ambisonics headphone rendering is to find a perceptually well behaved low-order representation of the Head-Related Transfer Functions (HRTFs) that are contained in the rendering pipe-line. Low-order rendering is of interest, when working with microphone arrays containing only a few sensors, or for reducing the bandwidth for signal transmission. Magnitude Least Squares rendering became the de facto standard for this, which discards high-frequency interaural phase information in favor of reducing magnitude errors. Building upon this idea, we suggest Masked Magnitude Least Squares, which optimized the Ambisonics coefficients with a neural network and employs a spatio-spectral weighting mask to control the accuracy of the magnitude reconstruction. In the tested case, the weighting mask helped to maintain high-frequency notches in the low-order HRTFs and improved the modeled median plane localization performance in comparison to MagLS, while only marginally affecting the overall accuracy of the magnitude reconstruction.
The importance of spatial and spectral information in multiple speaker tracking
Oct 15, 2024Multi-speaker localization and tracking using microphone array recording is of importance in a wide range of applications. One of the challenges with multi-speaker tracking is to associate direction estimates with the correct speaker. Most existing association approaches rely on spatial or spectral information alone, leading to performance degradation when one of these information channels is partially known or missing. This paper studies a joint probability data association (JPDA)-based method that facilitates association based on joint spatial-spectral information. This is achieved by integrating speaker time-frequency (TF) masks, estimated based on spectral information, in the association probabilities calculation. An experimental study that tested the proposed method on recordings from the LOCATA challenge demonstrates the enhanced performance obtained by using joint spatial-spectral information in the association.
Improved direction of arrival estimations with a wearable microphone array for dynamic environments by reliability weighting
Sep 22, 2024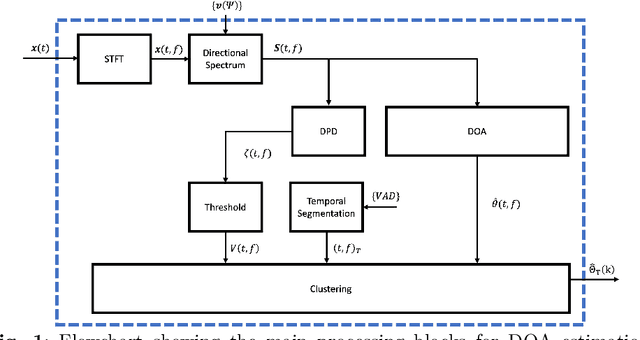
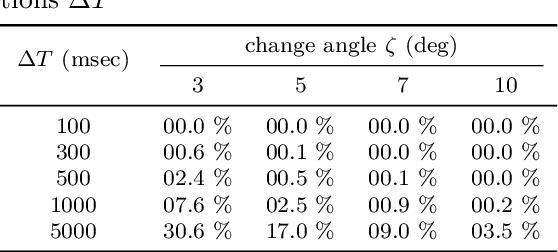
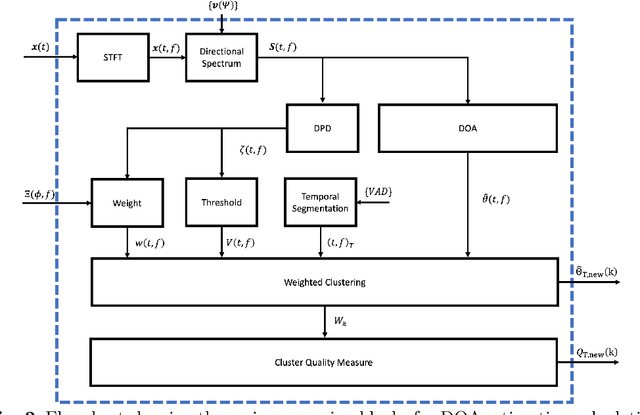

Direction-of-arrival estimation of multiple speakers in a room is an important task for a wide range of applications. In particular, challenging environments with moving speakers, reverberation and noise, lead to significant performance degradation for current methods. With the aim of better understanding factors affecting performance and improving current methods, in this paper multi-speaker direction-of-arrival (DOA) estimation is investigated using a modified version of the local space domain distance (LSDD) algorithm in a noisy, dynamic and reverberant environment employing a wearable microphone array. This study utilizes the recently published EasyCom speech dataset, recorded using a wearable microphone array mounted on eyeglasses. While the original LSDD algorithm demonstrates strong performance in static environments, its efficacy significantly diminishes in the dynamic settings of the EasyCom dataset. Several enhancements to the LSDD algorithm are developed following a comprehensive performance and system analysis, which enable improved DOA estimation under these challenging conditions. These improvements include incorporating a weighted reliability approach and introducing a new quality measure that reliably identifies the more accurate DOA estimates, thereby enhancing both the robustness and accuracy of the algorithm in challenging environments.
Insights into the Incorporation of Signal Information in Binaural Signal Matching with Wearable Microphone Arrays
Sep 18, 2024The increasing popularity of spatial audio in applications such as teleconferencing, entertainment, and virtual reality has led to the recent developments of binaural reproduction methods. However, only a few of these methods are well-suited for wearable and mobile arrays, which typically consist of a small number of microphones. One such method is binaural signal matching (BSM), which has been shown to produce high-quality binaural signals for wearable arrays. However, BSM may be suboptimal in cases of high direct-to-reverberant ratio (DRR) as it is based on the diffuse sound field assumption. To overcome this limitation, previous studies incorporated sound-field models other than diffuse. However, this approach was not studied comprehensively. This paper extensively investigates two BSM-based methods designed for high DRR scenarios. The methods incorporate a sound field model composed of direct and reverberant components.The methods are investigated both mathematically and using simulations, finally validated by a listening test. The results show that the proposed methods can significantly improve the performance of BSM , in particular in the direction of the source, while presenting only a negligible degradation in other directions. Furthermore, when source direction estimation is inaccurate, performance of these methods degrade to equal that of the BSM, presenting a desired robustness quality.