 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Audiovisual Speech Processing via MUTUD: Multimodal Training and Unimodal Deployment
Jan 30, 2025



Building reliable speech systems often requires combining multiple modalities, like audio and visual cues. While such multimodal solutions frequently lead to improvements in performance and may even be critical in certain cases, they come with several constraints such as increased sensory requirements, computational cost, and modality synchronization, to mention a few. These challenges constrain the direct uses of these multimodal solutions in real-world applications. In this work, we develop approaches where the learning happens with all available modalities but the deployment or inference is done with just one or reduced modalities. To do so, we propose a Multimodal Training and Unimodal Deployment (MUTUD) framework which includes a Temporally Aligned Modality feature Estimation (TAME) module that can estimate information from missing modality using modalities present during inference. This innovative approach facilitates the integration of information across different modalities, enhancing the overall inference process by leveraging the strengths of each modality to compensate for the absence of certain modalities during inference. We apply MUTUD to various audiovisual speech tasks and show that it can reduce the performance gap between the multimodal and corresponding unimodal models to a considerable extent. MUTUD can achieve this while reducing the model size and compute compared to multimodal models, in some cases by almost 80%.
Insights into the Incorporation of Signal Information in Binaural Signal Matching with Wearable Microphone Arrays
Sep 18, 2024The increasing popularity of spatial audio in applications such as teleconferencing, entertainment, and virtual reality has led to the recent developments of binaural reproduction methods. However, only a few of these methods are well-suited for wearable and mobile arrays, which typically consist of a small number of microphones. One such method is binaural signal matching (BSM), which has been shown to produce high-quality binaural signals for wearable arrays. However, BSM may be suboptimal in cases of high direct-to-reverberant ratio (DRR) as it is based on the diffuse sound field assumption. To overcome this limitation, previous studies incorporated sound-field models other than diffuse. However, this approach was not studied comprehensively. This paper extensively investigates two BSM-based methods designed for high DRR scenarios. The methods incorporate a sound field model composed of direct and reverberant components.The methods are investigated both mathematically and using simulations, finally validated by a listening test. The results show that the proposed methods can significantly improve the performance of BSM , in particular in the direction of the source, while presenting only a negligible degradation in other directions. Furthermore, when source direction estimation is inaccurate, performance of these methods degrade to equal that of the BSM, presenting a desired robustness quality.
M-BEST-RQ: A Multi-Channel Speech Foundation Model for Smart Glasses
Sep 17, 2024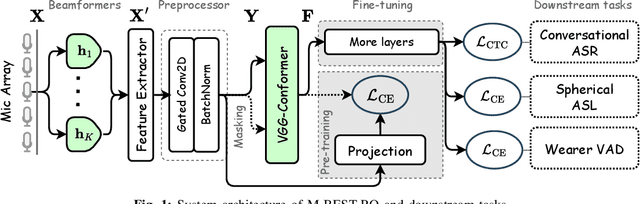

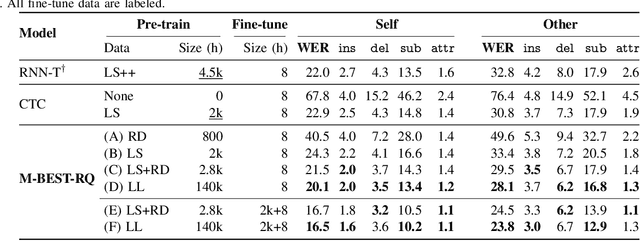
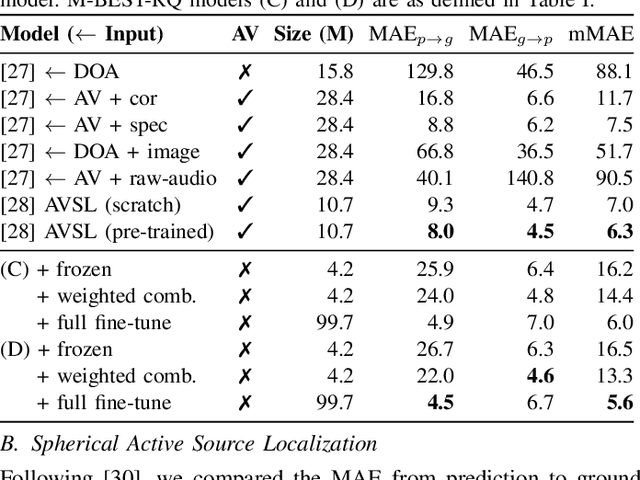
The growing popularity of multi-channel wearable devices, such as smart glasses, has led to a surge of applications such as targeted speech recognition and enhanced hearing. However, current approaches to solve these tasks use independently trained models, which may not benefit from large amounts of unlabeled data. In this paper, we propose M-BEST-RQ, the first multi-channel speech foundation model for smart glasses, which is designed to leverage large-scale self-supervised learning (SSL) in an array-geometry agnostic approach. While prior work on multi-channel speech SSL only evaluated on simulated settings, we curate a suite of real downstream tasks to evaluate our model, namely (i) conversational automatic speech recognition (ASR), (ii) spherical active source localization, and (iii) glasses wearer voice activity detection, which are sourced from the MMCSG and EasyCom datasets. We show that a general-purpose M-BEST-RQ encoder is able to match or surpass supervised models across all tasks. For the conversational ASR task in particular, using only 8 hours of labeled speech, our model outperforms a supervised ASR baseline that is trained on 2000 hours of labeled data, which demonstrates the effectiveness of our approach.
Spherical World-Locking for Audio-Visual Localization in Egocentric Videos
Aug 09, 2024


Egocentric videos provide comprehensive contexts for user and scene understanding, spanning multisensory perception to behavioral interaction. We propose Spherical World-Locking (SWL) as a general framework for egocentric scene representation, which implicitly transforms multisensory streams with respect to measurements of head orientation. Compared to conventional head-locked egocentric representations with a 2D planar field-of-view, SWL effectively offsets challenges posed by self-motion, allowing for improved spatial synchronization between input modalities. Using a set of multisensory embeddings on a worldlocked sphere, we design a unified encoder-decoder transformer architecture that preserves the spherical structure of the scene representation, without requiring expensive projections between image and world coordinate systems. We evaluate the effectiveness of the proposed framework on multiple benchmark tasks for egocentric video understanding, including audio-visual active speaker localization, auditory spherical source localization, and behavior anticipation in everyday activities.
Design and Analysis of Binaural Signal Matching with Arbitrary Microphone Arrays
Aug 07, 2024Binaural reproduction is rapidly becoming a topic of great interest in the research community, especially with the surge of new and popular devices, such as virtual reality headsets, smart glasses, and head-tracked headphones. In order to immerse the listener in a virtual or remote environment with such devices, it is essential to generate realistic and accurate binaural signals. This is challenging, especially since the microphone arrays mounted on these devices are typically composed of an arbitrarily-arranged small number of microphones, which impedes the use of standard audio formats like Ambisonics, and provides limited spatial resolution. The binaural signal matching (BSM) method was developed recently to overcome these challenges. While it produced binaural signals with low error using relatively simple arrays, its performance degraded significantly when head rotation was introduced. This paper aims to develop the BSM method further and overcome its limitations. For this purpose, the method is first analyzed in detail, and a design framework that guarantees accurate binaural reproduction for relatively complex acoustic environments is presented. Next, it is shown that the BSM accuracy may significantly degrade at high frequencies, and thus, a perceptually motivated extension to the method is proposed, based on a magnitude least-squares (MagLS) formulation. These insights and developments are then analyzed with the help of an extensive simulation study of a simple six-microphone semi-circular array. It is further shown that the BSM-MagLS method can be very useful in compensating for head rotations with this array. Finally, a listening experiment is conducted with a four-microphone array on a pair of glasses in a reverberant speech environment and including head rotations, where it is shown that BSM-MagLS can indeed produce binaural signals with a high perceived quality.
Ambisonics Encoding For Arbitrary Microphone Arrays Incorporating Residual Channels For Binaural Reproduction
Feb 27, 2024


In the rapidly evolving fields of virtual and augmented reality, accurate spatial audio capture and reproduction are essential. For these applications, Ambisonics has emerged as a standard format. However, existing methods for encoding Ambisonics signals from arbitrary microphone arrays face challenges, such as errors due to the irregular array configurations and limited spatial resolution resulting from a typically small number of microphones. To address these limitations and challenges, a mathematical framework for studying Ambisonics encoding is presented, highlighting the importance of incorporating the full steering function, and providing a novel measure for predicting the accuracy of encoding each Ambisonics channel from the steering functions alone. Furthermore, novel residual channels are formulated supplementing the Ambisonics channels. A simulation study for several array configurations demonstrates a reduction in binaural error for this approach.
On the Importance of Neural Wiener Filter for Resource Efficient Multichannel Speech Enhancement
Jan 15, 2024
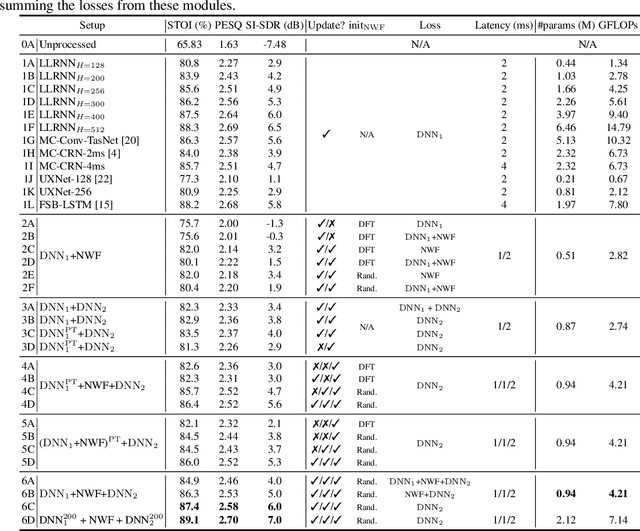
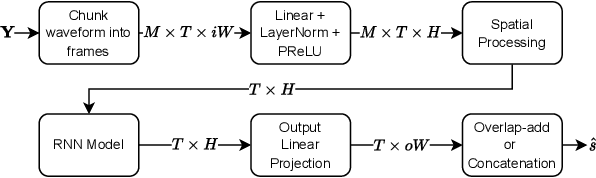
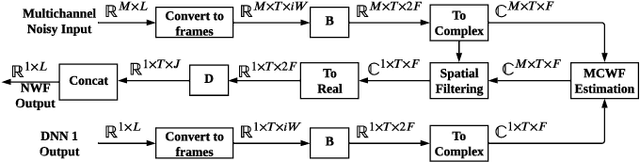
We introduce a time-domain framework for efficient multichannel speech enhancement, emphasizing low latency and computational efficiency. This framework incorporates two compact deep neural networks (DNNs) surrounding a multichannel neural Wiener filter (NWF). The first DNN enhances the speech signal to estimate NWF coefficients, while the second DNN refines the output from the NWF. The NWF, while conceptually similar to the traditional frequency-domain Wiener filter, undergoes a training process optimized for low-latency speech enhancement, involving fine-tuning of both analysis and synthesis transforms. Our research results illustrate that the NWF output, having minimal nonlinear distortions, attains performance levels akin to those of the first DNN, deviating from conventional Wiener filter paradigms. Training all components jointly outperforms sequential training, despite its simplicity. Consequently, this framework achieves superior performance with fewer parameters and reduced computational demands, making it a compelling solution for resource-efficient multichannel speech enhancement.
Subspace Hybrid MVDR Beamforming for Augmented Hearing
Nov 30, 2023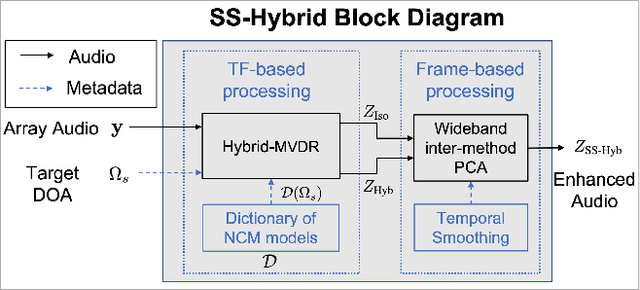
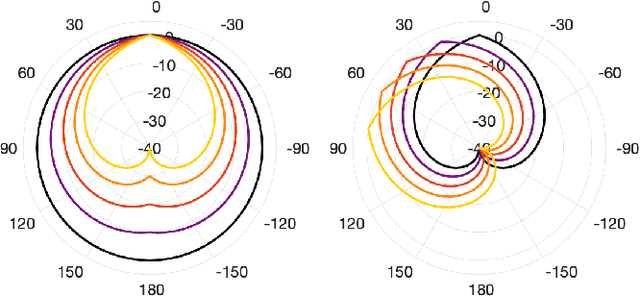
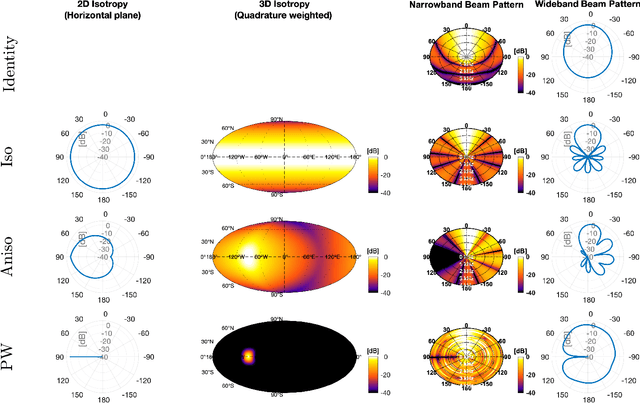
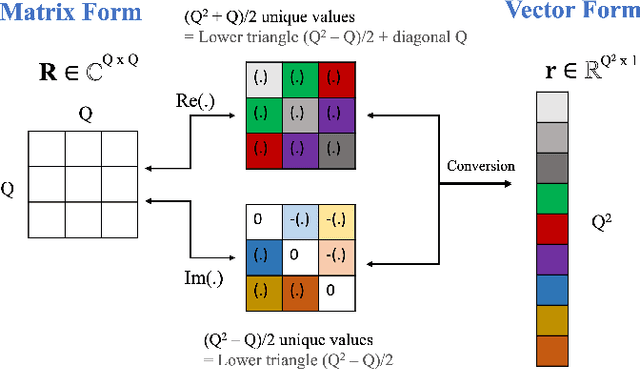
Signal-dependent beamformers are advantageous over signal-independent beamformers when the acoustic scenario - be it real-world or simulated - is straightforward in terms of the number of sound sources, the ambient sound field and their dynamics. However, in the context of augmented reality audio using head-worn microphone arrays, the acoustic scenarios encountered are often far from straightforward. The design of robust, high-performance, adaptive beamformers for such scenarios is an on-going challenge. This is due to the violation of the typically required assumptions on the noise field caused by, for example, rapid variations resulting from complex acoustic environments, and/or rotations of the listener's head. This work proposes a multi-channel speech enhancement algorithm which utilises the adaptability of signal-dependent beamformers while still benefiting from the computational efficiency and robust performance of signal-independent super-directive beamformers. The algorithm has two stages. (i) The first stage is a hybrid beamformer based on a dictionary of weights corresponding to a set of noise field models. (ii) The second stage is a wide-band subspace post-filter to remove any artifacts resulting from (i). The algorithm is evaluated using both real-world recordings and simulations of a cocktail-party scenario. Noise suppression, intelligibility and speech quality results show a significant performance improvement by the proposed algorithm compared to the baseline super-directive beamformer. A data-driven implementation of the noise field dictionary is shown to provide more noise suppression, and similar speech intelligibility and quality, compared to a parametric dictionary.
Performance Analysis Of Binaural Signal Matching (BSM) in the Time-Frequency Domain
Nov 23, 2023
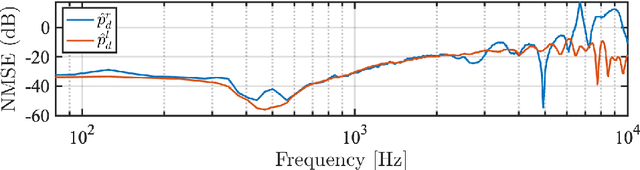
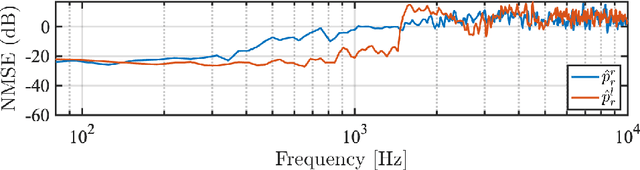
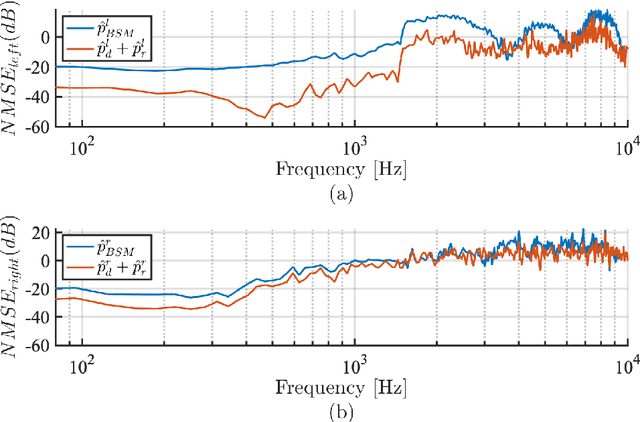
The capture and reproduction of spatial audio is becoming increasingly popular, with the mushrooming of applications in teleconferencing, entertainment and virtual reality. Many binaural reproduction methods have been developed and studied extensively for spherical and other specially designed arrays. However, the recent increased popularity of wearable and mobile arrays requires the development of binaural reproduction methods for these arrays. One such method is binaural signal matching (BSM). However, to date this method has only been investigated with fixed matched filters designed for long audio recordings. With the aim of making the BSM method more adaptive to dynamic environments, this paper analyzes BSM with a parameterized sound-field in the time-frequency domain. The paper presents results of implementing the BSM method on a sound-field that was decomposed into its direct and reverberant components, and compares this implementation with the BSM computed for the entire sound-field, to compare performance for binaural reproduction of reverberant speech in a simulated environment.
Subspace Hybrid Beamforming for Head-worn Microphone Arrays
Mar 15, 2023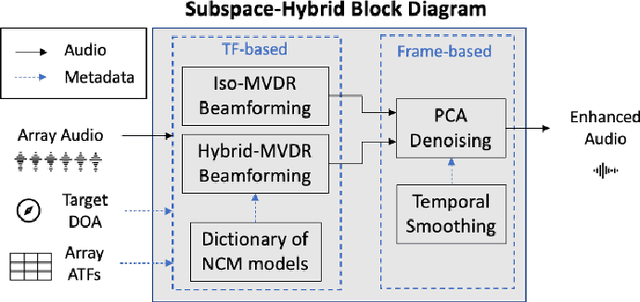
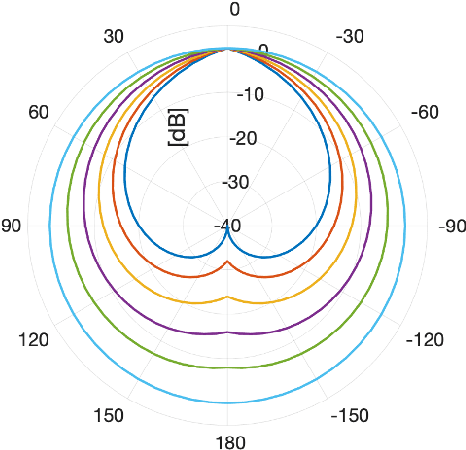
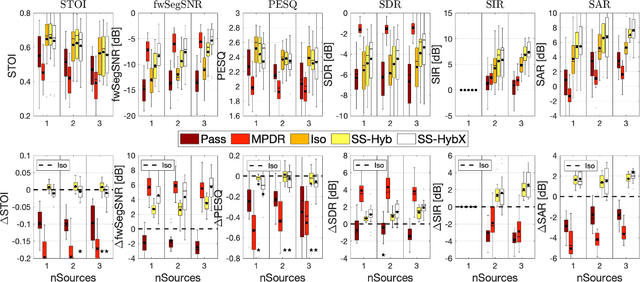
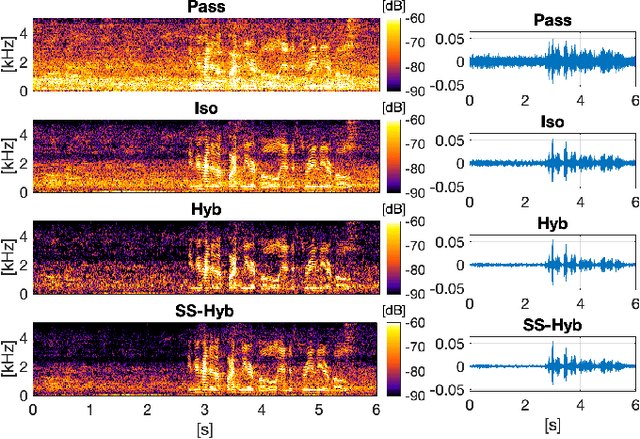
A two-stage multi-channel speech enhancement method is proposed which consists of a novel adaptive beamformer, Hybrid Minimum Variance Distortionless Response (MVDR), Isotropic-MVDR (Iso), and a novel multi-channel spectral Principal Components Analysis (PCA) denoising. In the first stage, the Hybrid-MVDR performs multiple MVDRs using a dictionary of pre-defined noise field models and picks the minimum-power outcome, which benefits from the robustness of signal-independent beamforming and the performance of adaptive beamforming. In the second stage, the outcomes of Hybrid and Iso are jointly used in a two-channel PCA-based denoising to remove the 'musical noise' produced by Hybrid beamformer. On a dataset of real 'cocktail-party' recordings with head-worn array, the proposed method outperforms the baseline superdirective beamformer in noise suppression (fwSegSNR, SDR, SIR, SAR) and speech intelligibility (STOI) with similar speech quality (PESQ) improvement.