 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-to-Stage: Spatial Layouts from Long-form Narratives
Mar 18, 2026In this work, we probe the ability of a language model to demonstrate spatial reasoning from unstructured text, mimicking human capabilities and automating a process that benefits many downstream media applications. Concretely, we study the narrative-to-play task: inferring stage-play layouts (scenes, speaker positions, movements, and room types) from text that lacks explicit spatial, positional, or relational cues. We then introduce a dramaturgy-inspired deterministic evaluation suite and, finally, a training and inference recipe that combines rejection SFT using Best-of-N sampling with RL from verifiable rewards via GRPO. Experiments on a text-only corpus of classical English literature demonstrate improvements over vanilla models across multiple metrics (character attribution, spatial plausibility, and movement economy), as well as alignment with an LLM-as-a-judge and subjective human preferences.
Sound Event Detection with Boundary-Aware Optimization and Inference
Jan 07, 2026Temporal detection problems appear in many fields including time-series estimation, activity recognition and sound event detection (SED). In this work, we propose a new approach to temporal event modeling by explicitly modeling event onsets and offsets, and by introducing boundary-aware optimization and inference strategies that substantially enhance temporal event detection. The presented methodology incorporates new temporal modeling layers - Recurrent Event Detection (RED) and Event Proposal Network (EPN) - which, together with tailored loss functions, enable more effective and precise temporal event detection. We evaluate the proposed method in the SED domain using a subset of the temporally-strongly annotated portion of AudioSet. Experimental results show that our approach not only outperforms traditional frame-wise SED models with state-of-the-art post-processing, but also removes the need for post-processing hyperparameter tuning, and scales to achieve new state-of-the-art performance across all AudioSet Strong classes.
Hearing Anywhere in Any Environment
Apr 14, 2025In mixed reality applications, a realistic acoustic experience in spatial environments is as crucial as the visual experience for achieving true immersion. Despite recent advances in neural approaches for Room Impulse Response (RIR) estimation, most existing methods are limited to the single environment on which they are trained, lacking the ability to generalize to new rooms with different geometries and surface materials. We aim to develop a unified model capable of reconstructing the spatial acoustic experience of any environment with minimum additional measurements. To this end, we present xRIR, a framework for cross-room RIR prediction. The core of our generalizable approach lies in combining a geometric feature extractor, which captures spatial context from panorama depth images, with a RIR encoder that extracts detailed acoustic features from only a few reference RIR samples. To evaluate our method, we introduce ACOUSTICROOMS, a new dataset featuring high-fidelity simulation of over 300,000 RIRs from 260 rooms. Experiments show that our method strongly outperforms a series of baselines. Furthermore, we successfully perform sim-to-real transfer by evaluating our model on four real-world environments, demonstrating the generalizability of our approach and the realism of our dataset.
Modulating State Space Model with SlowFast Framework for Compute-Efficient Ultra Low-Latency Speech Enhancement
Nov 04, 2024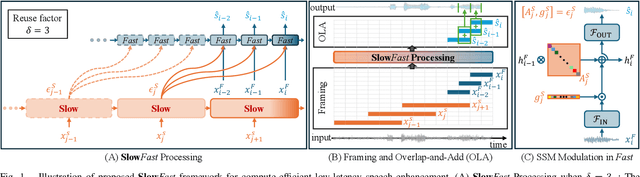
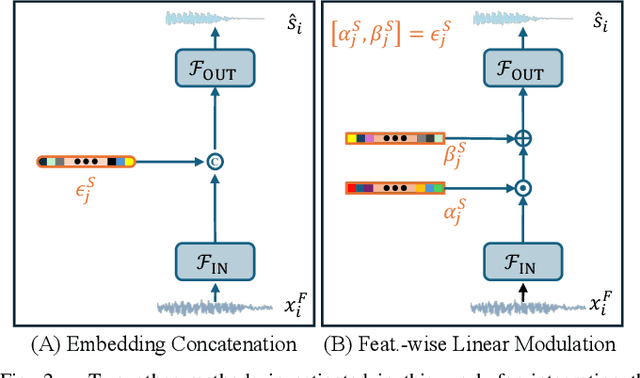
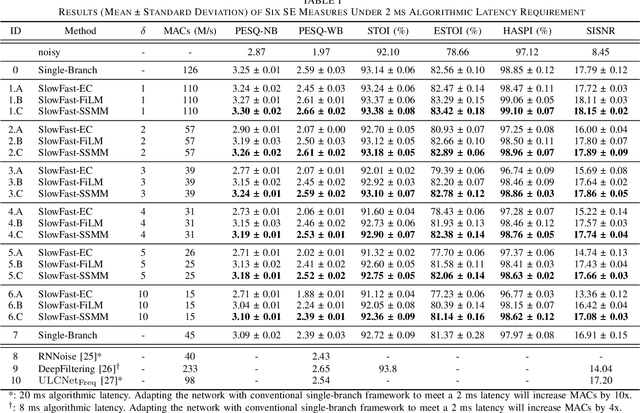

Deep learning-based speech enhancement (SE) methods often face significant computational challenges when needing to meet low-latency requirements because of the increased number of frames to be processed. This paper introduces the SlowFast framework which aims to reduce computation costs specifically when low-latency enhancement is needed. The framework consists of a slow branch that analyzes the acoustic environment at a low frame rate, and a fast branch that performs SE in the time domain at the needed higher frame rate to match the required latency. Specifically, the fast branch employs a state space model where its state transition process is dynamically modulated by the slow branch. Experiments on a SE task with a 2 ms algorithmic latency requirement using the Voice Bank + Demand dataset show that our approach reduces computation cost by 70% compared to a baseline single-branch network with equivalent parameters, without compromising enhancement performance. Furthermore, by leveraging the SlowFast framework, we implemented a network that achieves an algorithmic latency of just 60 {\mu}s (one sample point at 16 kHz sample rate) with a computation cost of 100 M MACs/s, while scoring a PESQ-NB of 3.12 and SISNR of 16.62.
Spherical World-Locking for Audio-Visual Localization in Egocentric Videos
Aug 09, 2024


Egocentric videos provide comprehensive contexts for user and scene understanding, spanning multisensory perception to behavioral interaction. We propose Spherical World-Locking (SWL) as a general framework for egocentric scene representation, which implicitly transforms multisensory streams with respect to measurements of head orientation. Compared to conventional head-locked egocentric representations with a 2D planar field-of-view, SWL effectively offsets challenges posed by self-motion, allowing for improved spatial synchronization between input modalities. Using a set of multisensory embeddings on a worldlocked sphere, we design a unified encoder-decoder transformer architecture that preserves the spherical structure of the scene representation, without requiring expensive projections between image and world coordinate systems. We evaluate the effectiveness of the proposed framework on multiple benchmark tasks for egocentric video understanding, including audio-visual active speaker localization, auditory spherical source localization, and behavior anticipation in everyday activities.
Hearing Loss Detection from Facial Expressions in One-on-one Conversations
Jan 17, 2024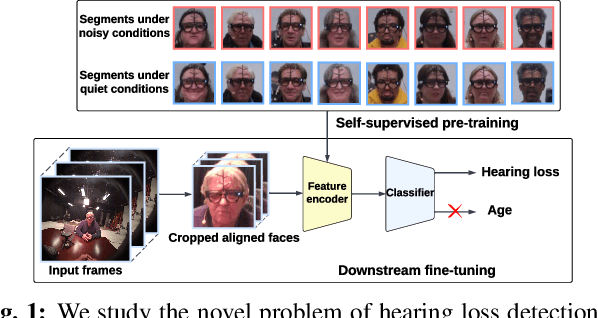
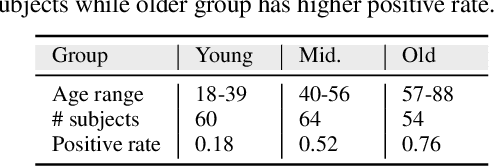
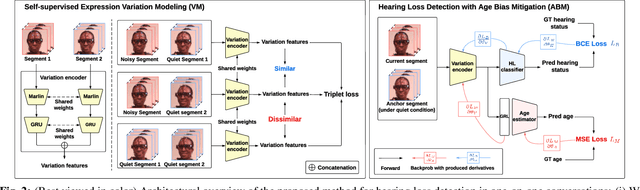
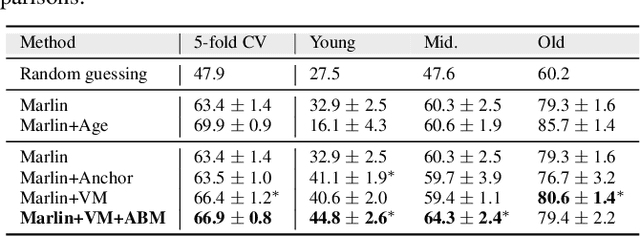
Individuals with impaired hearing experience difficulty in conversations, especially in noisy environments. This difficulty often manifests as a change in behavior and may be captured via facial expressions, such as the expression of discomfort or fatigue. In this work, we build on this idea and introduce the problem of detecting hearing loss from an individual's facial expressions during a conversation. Building machine learning models that can represent hearing-related facial expression changes is a challenge. In addition, models need to disentangle spurious age-related correlations from hearing-driven expressions. To this end, we propose a self-supervised pre-training strategy tailored for the modeling of expression variations. We also use adversarial representation learning to mitigate the age bias. We evaluate our approach on a large-scale egocentric dataset with real-world conversational scenarios involving subjects with hearing loss and show that our method for hearing loss detection achieves superior performance over baselines.
The Audio-Visual Conversational Graph: From an Egocentric-Exocentric Perspective
Dec 20, 2023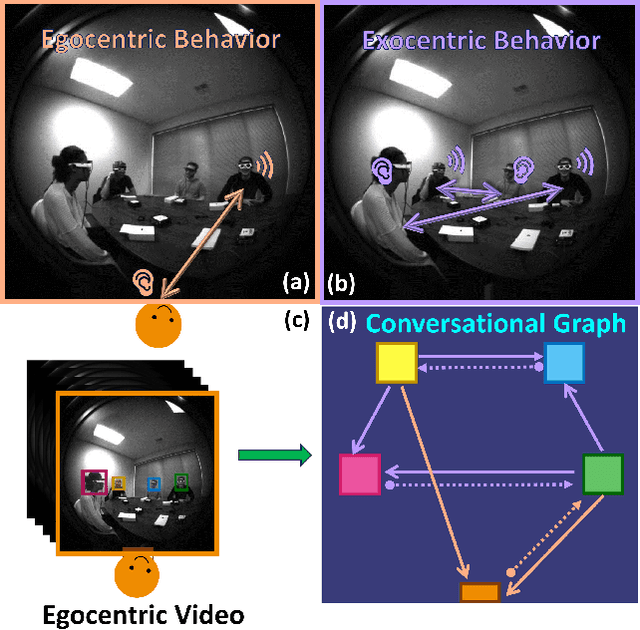
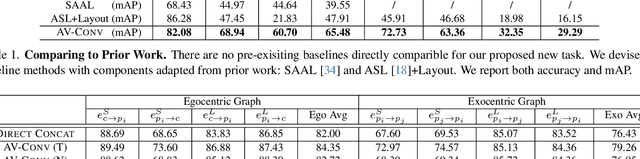
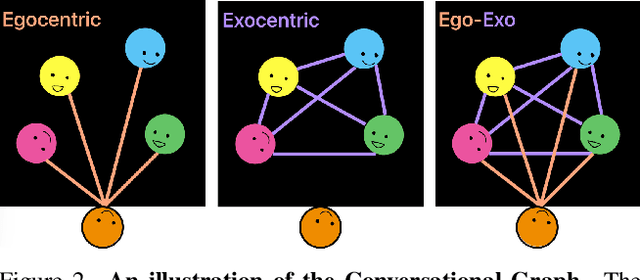
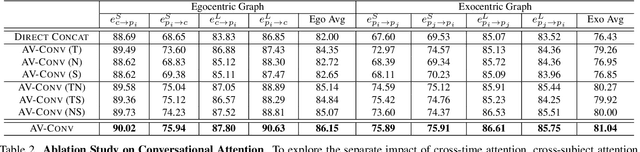
In recent years, the thriving development of research related to egocentric videos has provided a unique perspective for the study of conversational interactions, where both visual and audio signals play a crucial role. While most prior work focus on learning about behaviors that directly involve the camera wearer, we introduce the Ego-Exocentric Conversational Graph Prediction problem, marking the first attempt to infer exocentric conversational interactions from egocentric videos. We propose a unified multi-modal, multi-task framework -- Audio-Visual Conversational Attention (Av-CONV), for the joint prediction of conversation behaviors -- speaking and listening -- for both the camera wearer as well as all other social partners present in the egocentric video. Specifically, we customize the self-attention mechanism to model the representations across-time, across-subjects, and across-modalities. To validate our method, we conduct experiments on a challenging egocentric video dataset that includes first-person perspective, multi-speaker, and multi-conversation scenarios. Our results demonstrate the superior performance of our method compared to a series of baselines. We also present detailed ablation studies to assess the contribution of each component in our model. Project page: https://vjwq.github.io/AV-CONV/.
Egocentric Auditory Attention Localization in Conversations
Mar 28, 2023


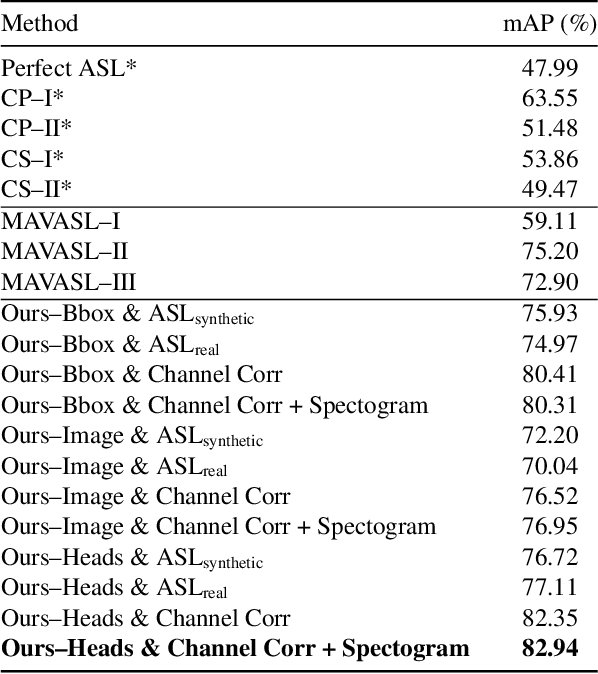
In a noisy conversation environment such as a dinner party, people often exhibit selective auditory attention, or the ability to focus on a particular speaker while tuning out others. Recognizing who somebody is listening to in a conversation is essential for developing technologies that can understand social behavior and devices that can augment human hearing by amplifying particular sound sources. The computer vision and audio research communities have made great strides towards recognizing sound sources and speakers in scenes. In this work, we take a step further by focusing on the problem of localizing auditory attention targets in egocentric video, or detecting who in a camera wearer's field of view they are listening to. To tackle the new and challenging Selective Auditory Attention Localization problem, we propose an end-to-end deep learning approach that uses egocentric video and multichannel audio to predict the heatmap of the camera wearer's auditory attention. Our approach leverages spatiotemporal audiovisual features and holistic reasoning about the scene to make predictions, and outperforms a set of baselines on a challenging multi-speaker conversation dataset. Project page: https://fkryan.github.io/saal
Novel-View Acoustic Synthesis
Jan 23, 2023



We introduce the novel-view acoustic synthesis (NVAS) task: given the sight and sound observed at a source viewpoint, can we synthesize the sound of that scene from an unseen target viewpoint? We propose a neural rendering approach: Visually-Guided Acoustic Synthesis (ViGAS) network that learns to synthesize the sound of an arbitrary point in space by analyzing the input audio-visual cues. To benchmark this task, we collect two first-of-their-kind large-scale multi-view audio-visual datasets, one synthetic and one real. We show that our model successfully reasons about the spatial cues and synthesizes faithful audio on both datasets. To our knowledge, this work represents the very first formulation, dataset, and approach to solve the novel-view acoustic synthesis task, which has exciting potential applications ranging from AR/VR to art and design. Unlocked by this work, we believe that the future of novel-view synthesis is in multi-modal learning from videos.
Chat2Map: Efficient Scene Mapping from Multi-Ego Conversations
Jan 04, 2023
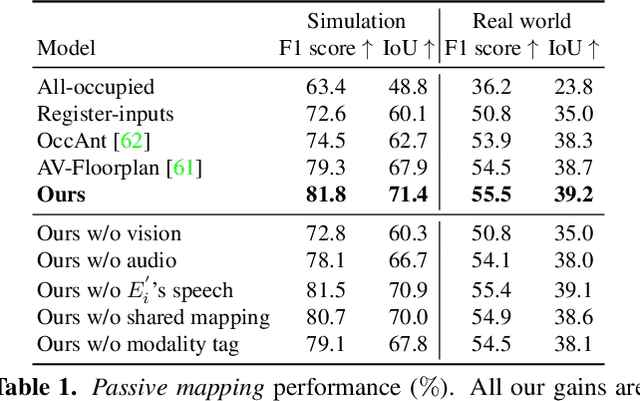

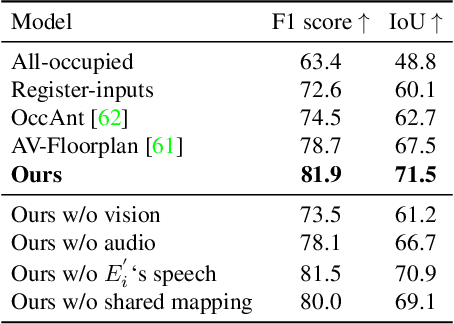
Can conversational videos captured from multiple egocentric viewpoints reveal the map of a scene in a cost-efficient way? We seek to answer this question by proposing a new problem: efficiently building the map of a previously unseen 3D environment by exploiting shared information in the egocentric audio-visual observations of participants in a natural conversation. Our hypothesis is that as multiple people ("egos") move in a scene and talk among themselves, they receive rich audio-visual cues that can help uncover the unseen areas of the scene. Given the high cost of continuously processing egocentric visual streams, we further explore how to actively coordinate the sampling of visual information, so as to minimize redundancy and reduce power use. To that end, we present an audio-visual deep reinforcement learning approach that works with our shared scene mapper to selectively turn on the camera to efficiently chart out the space. We evaluate the approach using a state-of-the-art audio-visual simulator for 3D scenes as well as real-world video. Our model outperforms previous state-of-the-art mapping methods, and achieves an excellent cost-accuracy tradeoff. Project: http://vision.cs.utexas.edu/projects/chat2map.