 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaterialistic RIR: Material Conditioned Realistic RIR Generation
Apr 22, 2026Rings like gold, thuds like wood! The sound we hear in a scene is shaped not only by the spatial layout of the environment but also by the materials of the objects and surfaces within it. For instance, a room with wooden walls will produce a different acoustic experience from a room with the same spatial layout but concrete walls. Accurately modeling these effects is essential for applications such as virtual reality, robotics, architectural design, and audio engineering. Yet, existing methods for acoustic modeling often entangle spatial and material influences in correlated representations, which limits user control and reduces the realism of the generated acoustics. In this work, we present a novel approach for material-controlled Room Impulse Response (RIR) generation that explicitly disentangles the effects of spatial and material cues in a scene. Our approach models the RIR using two modules: a spatial module that captures the influence of the spatial layout of the scene, and a material module that modulates this spatial RIR according to a user-specified material configuration. This explicitly disentangled design allows users to easily modify the material configuration of a scene and observe its impact on acoustics without altering the spatial structure or scene content. Our model provides significant improvements over prior approaches on both acoustic-based metrics (up to +16% on RTE) and material-based metrics (up to +70%). Furthermore, through a human perceptual study, we demonstrate the improved realism and material sensitivity of our model compared to the strongest baselines.
MistExit: Learning to Exit for Early Mistake Detection in Procedural Videos
Mar 15, 2026We introduce the task of early mistake detection in video, where the goal is to determine whether a keystep in a procedural activity is performed correctly while observing as little of the streaming video as possible. To tackle this problem, we propose a method comprising a mistake detector and a reinforcement learning policy. At each timestep, the detector processes recently observed frames to estimate the keystep's correctness while anticipating future visual features, enabling reliable early mistake estimates. Meanwhile, the policy aggregates the detector outputs and visual observations over time and adaptively decides when to exit (i.e., stop processing incoming frames) while producing the final prediction. Using diverse real-world procedural video datasets, we demonstrate that our MistExit model achieves superior mistake detection accuracy while reducing the fraction of video observed compared to state-of-the-art models. Project: https://vision.cs.utexas.edu/projects/mist_exit.
Audio-Visual Camera Pose Estimation with Passive Scene Sounds and In-the-Wild Video
Dec 16, 2025Understanding camera motion is a fundamental problem in embodied perception and 3D scene understanding. While visual methods have advanced rapidly, they often struggle under visually degraded conditions such as motion blur or occlusions. In this work, we show that passive scene sounds provide complementary cues for relative camera pose estimation for in-the-wild videos. We introduce a simple but effective audio-visual framework that integrates direction-ofarrival (DOA) spectra and binauralized embeddings into a state-of-the-art vision-only pose estimation model. Our results on two large datasets show consistent gains over strong visual baselines, plus robustness when the visual information is corrupted. To our knowledge, this represents the first work to successfully leverage audio for relative camera pose estimation in real-world videos, and it establishes incidental, everyday audio as an unexpected but promising signal for a classic spatial challenge. Project: http://vision.cs.utexas.edu/projects/av_camera_pose.
Switch-a-View: Few-Shot View Selection Learned from Edited Videos
Dec 24, 2024We introduce Switch-a-View, a model that learns to automatically select the viewpoint to display at each timepoint when creating a how-to video. The key insight of our approach is how to train such a model from unlabeled--but human-edited--video samples. We pose a pretext task that pseudo-labels segments in the training videos for their primary viewpoint (egocentric or exocentric), and then discovers the patterns between those view-switch moments on the one hand and the visual and spoken content in the how-to video on the other hand. Armed with this predictor, our model then takes an unseen multi-view video as input and orchestrates which viewpoint should be displayed when. We further introduce a few-shot training setting that permits steering the model towards a new data domain. We demonstrate our idea on a variety of real-world video from HowTo100M and Ego-Exo4D and rigorously validate its advantages.
Which Viewpoint Shows it Best? Language for Weakly Supervising View Selection in Multi-view Videos
Nov 13, 2024



Given a multi-view video, which viewpoint is most informative for a human observer? Existing methods rely on heuristics or expensive ``best-view" supervision to answer this question, limiting their applicability. We propose a weakly supervised approach that leverages language accompanying an instructional multi-view video as a means to recover its most informative viewpoint(s). Our key hypothesis is that the more accurately an individual view can predict a view-agnostic text summary, the more informative it is. To put this into action, we propose a framework that uses the relative accuracy of view-dependent caption predictions as a proxy for best view pseudo-labels. Then, those pseudo-labels are used to train a view selector, together with an auxiliary camera pose predictor that enhances view-sensitivity. During inference, our model takes as input only a multi-view video -- no language or camera poses -- and returns the best viewpoint to watch at each timestep. On two challenging datasets comprised of diverse multi-camera setups and how-to activities, our model consistently outperforms state-of-the-art baselines, both with quantitative metrics and human evaluation.
ActiveRIR: Active Audio-Visual Exploration for Acoustic Environment Modeling
Apr 24, 2024



An environment acoustic model represents how sound is transformed by the physical characteristics of an indoor environment, for any given source/receiver location. Traditional methods for constructing acoustic models involve expensive and time-consuming collection of large quantities of acoustic data at dense spatial locations in the space, or rely on privileged knowledge of scene geometry to intelligently select acoustic data sampling locations. We propose active acoustic sampling, a new task for efficiently building an environment acoustic model of an unmapped environment in which a mobile agent equipped with visual and acoustic sensors jointly constructs the environment acoustic model and the occupancy map on-the-fly. We introduce ActiveRIR, a reinforcement learning (RL) policy that leverages information from audio-visual sensor streams to guide agent navigation and determine optimal acoustic data sampling positions, yielding a high quality acoustic model of the environment from a minimal set of acoustic samples. We train our policy with a novel RL reward based on information gain in the environment acoustic model. Evaluating on diverse unseen indoor environments from a state-of-the-art acoustic simulation platform, ActiveRIR outperforms an array of methods--both traditional navigation agents based on spatial novelty and visual exploration as well as existing state-of-the-art methods.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
Learning Spatial Features from Audio-Visual Correspondence in Egocentric Videos
Jul 10, 2023



We propose a self-supervised method for learning representations based on spatial audio-visual correspondences in egocentric videos. In particular, our method leverages a masked auto-encoding framework to synthesize masked binaural audio through the synergy of audio and vision, thereby learning useful spatial relationships between the two modalities. We use our pretrained features to tackle two downstream video tasks requiring spatial understanding in social scenarios: active speaker detection and spatial audio denoising. We show through extensive experiments that our features are generic enough to improve over multiple state-of-the-art baselines on two public challenging egocentric video datasets, EgoCom and EasyCom. Project: http://vision.cs.utexas.edu/projects/ego_av_corr.
Chat2Map: Efficient Scene Mapping from Multi-Ego Conversations
Jan 04, 2023
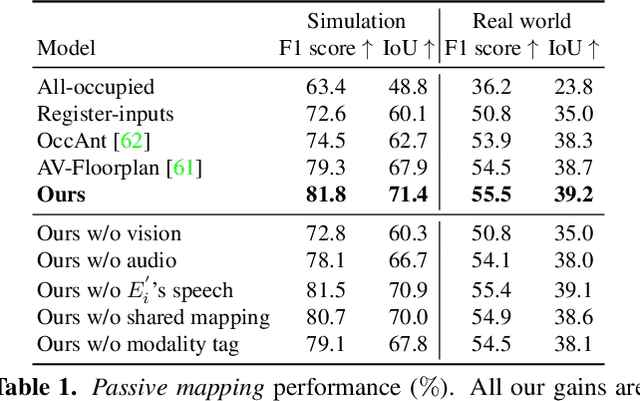

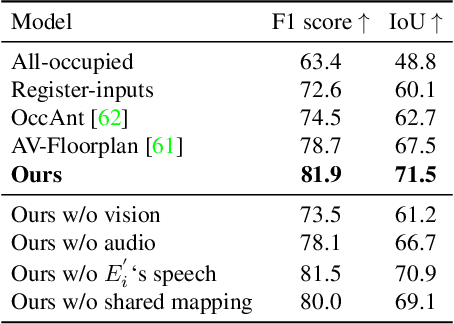
Can conversational videos captured from multiple egocentric viewpoints reveal the map of a scene in a cost-efficient way? We seek to answer this question by proposing a new problem: efficiently building the map of a previously unseen 3D environment by exploiting shared information in the egocentric audio-visual observations of participants in a natural conversation. Our hypothesis is that as multiple people ("egos") move in a scene and talk among themselves, they receive rich audio-visual cues that can help uncover the unseen areas of the scene. Given the high cost of continuously processing egocentric visual streams, we further explore how to actively coordinate the sampling of visual information, so as to minimize redundancy and reduce power use. To that end, we present an audio-visual deep reinforcement learning approach that works with our shared scene mapper to selectively turn on the camera to efficiently chart out the space. We evaluate the approach using a state-of-the-art audio-visual simulator for 3D scenes as well as real-world video. Our model outperforms previous state-of-the-art mapping methods, and achieves an excellent cost-accuracy tradeoff. Project: http://vision.cs.utexas.edu/projects/chat2map.
Retrospectives on the Embodied AI Workshop
Oct 17, 2022

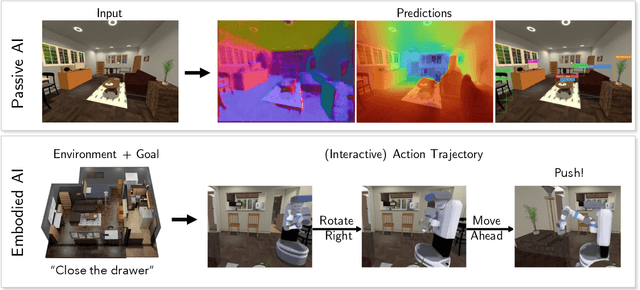
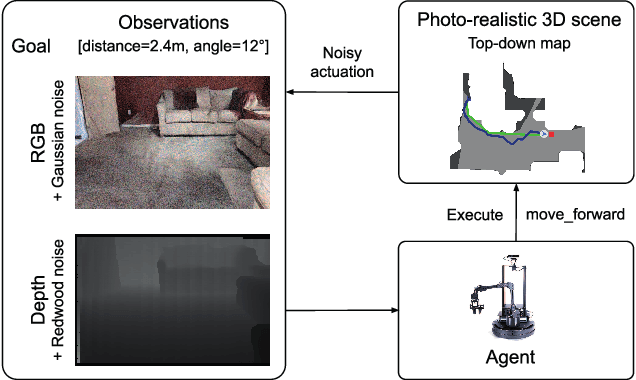
We present a retrospective on the state of Embodied AI research. Our analysis focuses on 13 challenges presented at the Embodied AI Workshop at CVPR. These challenges are grouped into three themes: (1) visual navigation, (2) rearrangement, and (3) embodied vision-and-language. We discuss the dominant datasets within each theme, evaluation metrics for the challenges, and the performance of state-of-the-art models. We highlight commonalities between top approaches to the challenges and identify potential future directions for Embodied AI research.