 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSportSkills: Physical Skill Learning from Sports Instructional Videos
Mar 26, 2026Current large-scale video datasets focus on general human activity, but lack depth of coverage on fine-grained activities needed to address physical skill learning. We introduce SportSkills, the first large-scale sports dataset geared towards physical skill learning with in-the-wild video. SportSkills has more than 360k instructional videos containing more than 630k visual demonstrations paired with instructional narrations explaining the know-how behind the actions from 55 varied sports. Through a suite of experiments, we show that SportSkills unlocks the ability to understand fine-grained differences between physical actions. Our representation achieves gains of up to 4x with the same model trained on traditional activity-centric datasets. Crucially, building on SportSkills, we introduce the first large-scale task formulation of mistake-conditioned instructional video retrieval, bridging representation learning and actionable feedback generation (e.g., "here's my execution of a skill; which video clip should I watch to improve it?"). Formal evaluations by professional coaches show our retrieval approach significantly advances the ability of video models to personalize visual instructions for a user query.
Human detectors are surprisingly powerful reward models
Jan 21, 2026Video generation models have recently achieved impressive visual fidelity and temporal coherence. Yet, they continue to struggle with complex, non-rigid motions, especially when synthesizing humans performing dynamic actions such as sports, dance, etc. Generated videos often exhibit missing or extra limbs, distorted poses, or physically implausible actions. In this work, we propose a remarkably simple reward model, HuDA, to quantify and improve the human motion in generated videos. HuDA integrates human detection confidence for appearance quality, and a temporal prompt alignment score to capture motion realism. We show this simple reward function that leverages off-the-shelf models without any additional training, outperforms specialized models finetuned with manually annotated data. Using HuDA for Group Reward Policy Optimization (GRPO) post-training of video models, we significantly enhance video generation, especially when generating complex human motions, outperforming state-of-the-art models like Wan 2.1, with win-rate of 73%. Finally, we demonstrate that HuDA improves generation quality beyond just humans, for instance, significantly improving generation of animal videos and human-object interactions.
Learning Skill-Attributes for Transferable Assessment in Video
Nov 17, 2025Skill assessment from video entails rating the quality of a person's physical performance and explaining what could be done better. Today's models specialize for an individual sport, and suffer from the high cost and scarcity of expert-level supervision across the long tail of sports. Towards closing that gap, we explore transferable video representations for skill assessment. Our CrossTrainer approach discovers skill-attributes, such as balance, control, and hand positioning -- whose meaning transcends the boundaries of any given sport, then trains a multimodal language model to generate actionable feedback for a novel video, e.g., "lift hands more to generate more power" as well as its proficiency level, e.g., early expert. We validate the new model on multiple datasets for both cross-sport (transfer) and intra-sport (in-domain) settings, where it achieves gains up to 60% relative to the state of the art. By abstracting out the shared behaviors indicative of human skill, the proposed video representation generalizes substantially better than an array of existing techniques, enriching today's multimodal large language models.
Stitch-a-Recipe: Video Demonstration from Multistep Descriptions
Mar 18, 2025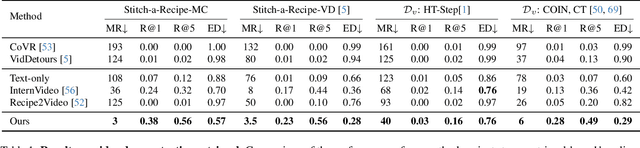
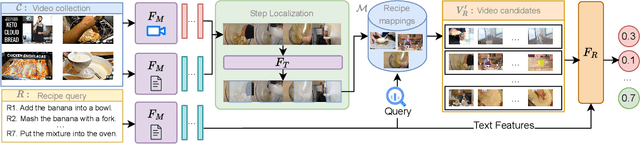
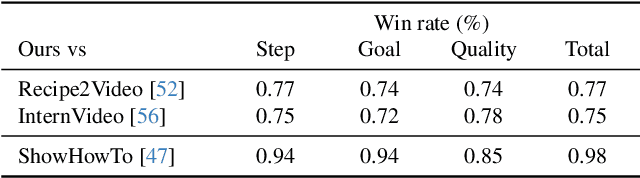

When obtaining visual illustrations from text descriptions, today's methods take a description with-a single text context caption, or an action description-and retrieve or generate the matching visual context. However, prior work does not permit visual illustration of multistep descriptions, e.g. a cooking recipe composed of multiple steps. Furthermore, simply handling each step description in isolation would result in an incoherent demonstration. We propose Stitch-a-Recipe, a novel retrieval-based method to assemble a video demonstration from a multistep description. The resulting video contains clips, possibly from different sources, that accurately reflect all the step descriptions, while being visually coherent. We formulate a training pipeline that creates large-scale weakly supervised data containing diverse and novel recipes and injects hard negatives that promote both correctness and coherence. Validated on in-the-wild instructional videos, Stitch-a-Recipe achieves state-of-the-art performance, with quantitative gains up to 24% as well as dramatic wins in a human preference study.
LLMs can see and hear without any training
Jan 30, 2025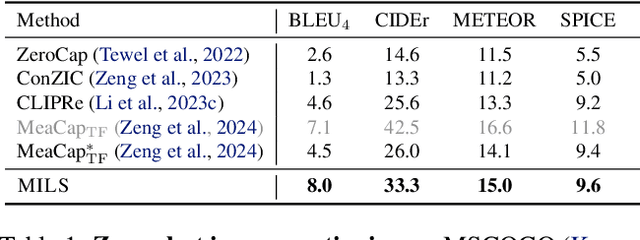
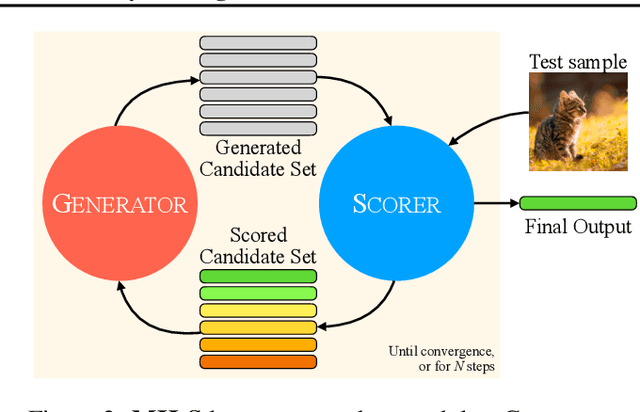


We present MILS: Multimodal Iterative LLM Solver, a surprisingly simple, training-free approach, to imbue multimodal capabilities into your favorite LLM. Leveraging their innate ability to perform multi-step reasoning, MILS prompts the LLM to generate candidate outputs, each of which are scored and fed back iteratively, eventually generating a solution to the task. This enables various applications that typically require training specialized models on task-specific data. In particular, we establish a new state-of-the-art on emergent zero-shot image, video and audio captioning. MILS seamlessly applies to media generation as well, discovering prompt rewrites to improve text-to-image generation, and even edit prompts for style transfer! Finally, being a gradient-free optimization approach, MILS can invert multimodal embeddings into text, enabling applications like cross-modal arithmetic.
FIction: 4D Future Interaction Prediction from Video
Dec 01, 2024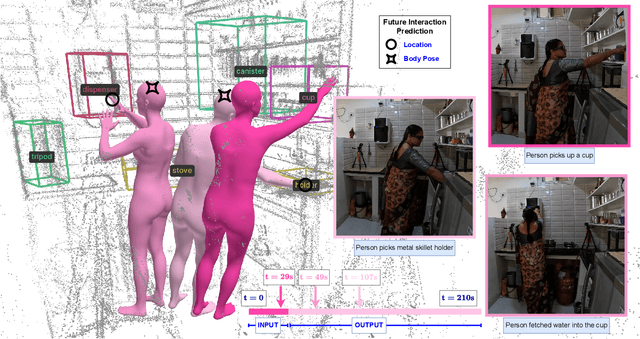
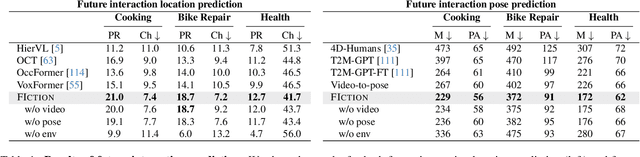
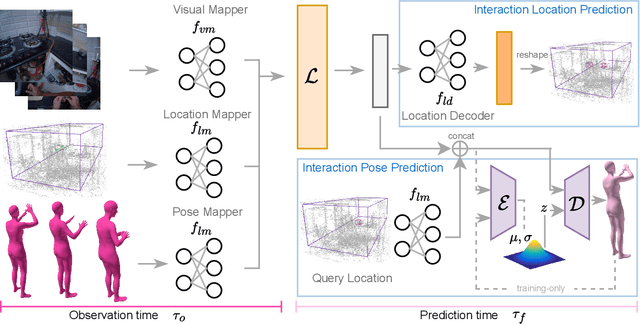
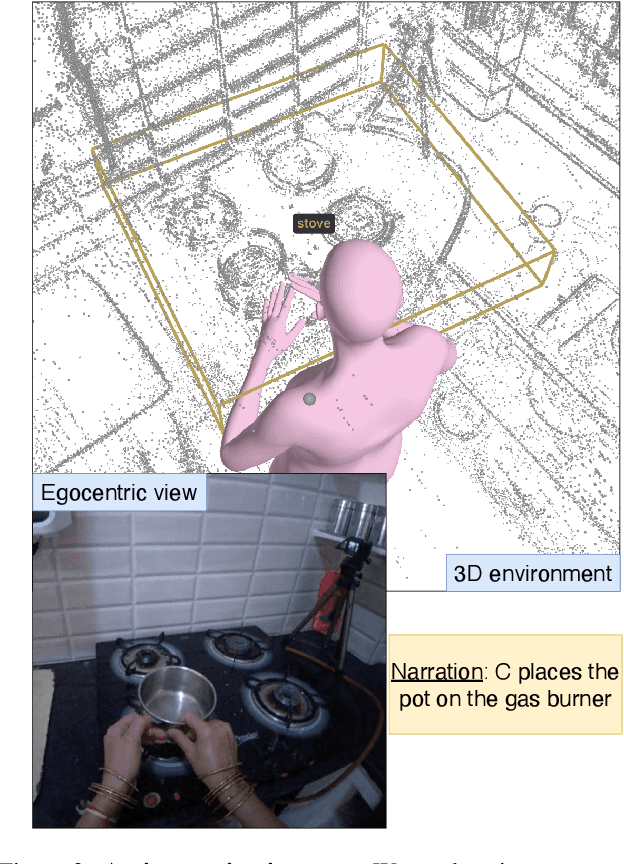
Anticipating how a person will interact with objects in an environment is essential for activity understanding, but existing methods are limited to the 2D space of video frames-capturing physically ungrounded predictions of 'what' and ignoring the 'where' and 'how'. We introduce 4D future interaction prediction from videos. Given an input video of a human activity, the goal is to predict what objects at what 3D locations the person will interact with in the next time period (e.g., cabinet, fridge), and how they will execute that interaction (e.g., poses for bending, reaching, pulling). We propose a novel model FIction that fuses the past video observation of the person's actions and their environment to predict both the 'where' and 'how' of future interactions. Through comprehensive experiments on a variety of activities and real-world environments in Ego-Exo4D, we show that our proposed approach outperforms prior autoregressive and (lifted) 2D video models substantially, with more than 30% relative gains.
ExpertAF: Expert Actionable Feedback from Video
Aug 01, 2024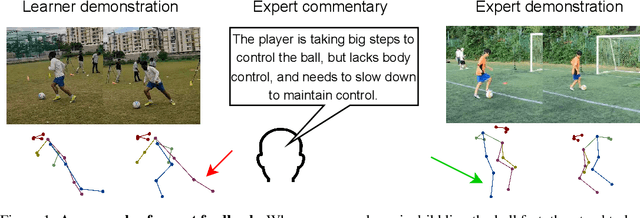
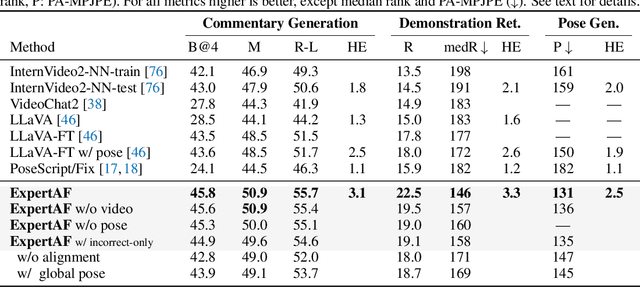
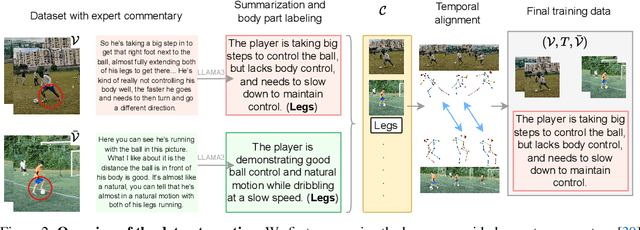
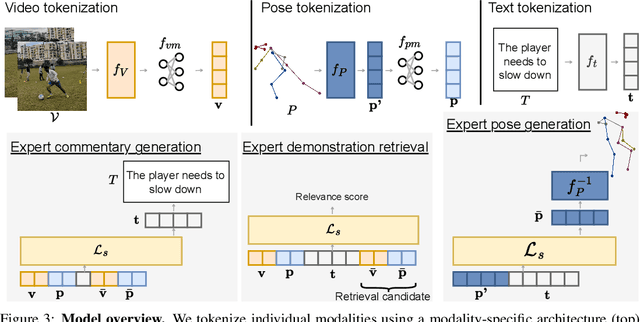
Feedback is essential for learning a new skill or improving one's current skill-level. However, current methods for skill-assessment from video only provide scores or compare demonstrations, leaving the burden of knowing what to do differently on the user. We introduce a novel method to generate actionable feedback from video of a person doing a physical activity, such as basketball or soccer. Our method takes a video demonstration and its accompanying 3D body pose and generates (1) free-form expert commentary describing what the person is doing well and what they could improve, and (2) a visual expert demonstration that incorporates the required corrections. We show how to leverage Ego-Exo4D's videos of skilled activity and expert commentary together with a strong language model to create a weakly-supervised training dataset for this task, and we devise a multimodal video-language model to infer coaching feedback. Our method is able to reason across multi-modal input combinations to output full-spectrum, actionable coaching -- expert commentary, expert video retrieval, and the first-of-its-kind expert pose generation -- outperforming strong vision-language models on both established metrics and human preference studies.
SoundingActions: Learning How Actions Sound from Narrated Egocentric Videos
Apr 08, 2024
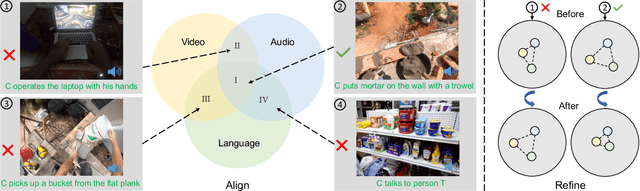
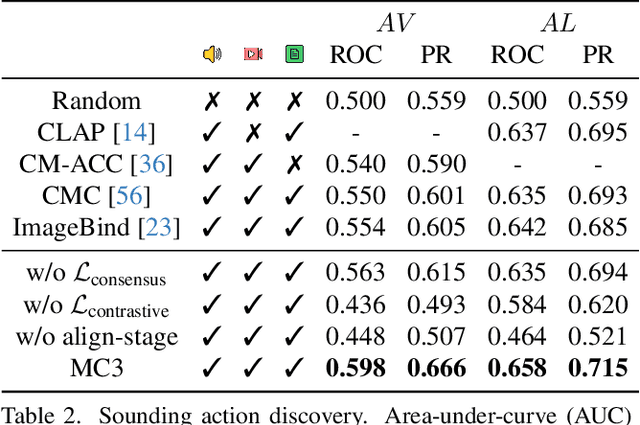
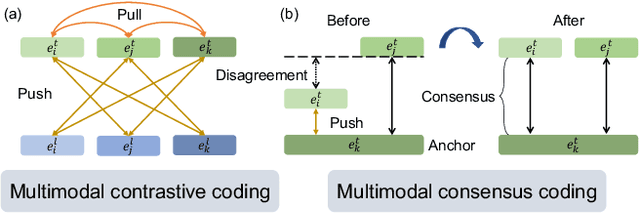
We propose a novel self-supervised embedding to learn how actions sound from narrated in-the-wild egocentric videos. Whereas existing methods rely on curated data with known audio-visual correspondence, our multimodal contrastive-consensus coding (MC3) embedding reinforces the associations between audio, language, and vision when all modality pairs agree, while diminishing those associations when any one pair does not. We show our approach can successfully discover how the long tail of human actions sound from egocentric video, outperforming an array of recent multimodal embedding techniques on two datasets (Ego4D and EPIC-Sounds) and multiple cross-modal tasks.
Detours for Navigating Instructional Videos
Jan 03, 2024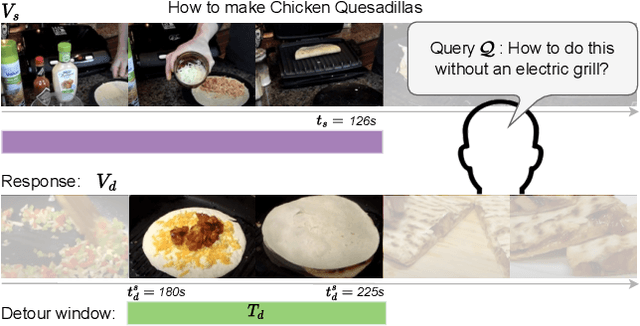
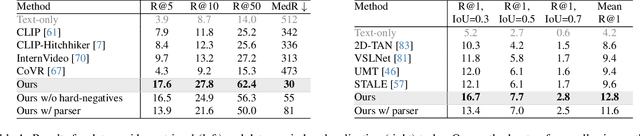

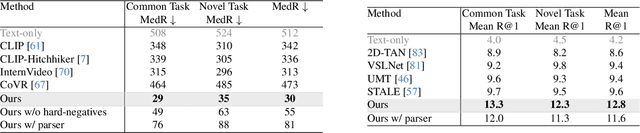
We introduce the video detours problem for navigating instructional videos. Given a source video and a natural language query asking to alter the how-to video's current path of execution in a certain way, the goal is to find a related ''detour video'' that satisfies the requested alteration. To address this challenge, we propose VidDetours, a novel video-language approach that learns to retrieve the targeted temporal segments from a large repository of how-to's using video-and-text conditioned queries. Furthermore, we devise a language-based pipeline that exploits how-to video narration text to create weakly supervised training data. We demonstrate our idea applied to the domain of how-to cooking videos, where a user can detour from their current recipe to find steps with alternate ingredients, tools, and techniques. Validating on a ground truth annotated dataset of 16K samples, we show our model's significant improvements over best available methods for video retrieval and question answering, with recall rates exceeding the state of the art by 35%.
Learning Object State Changes in Videos: An Open-World Perspective
Dec 19, 2023
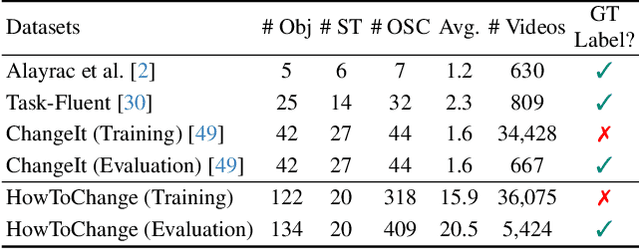
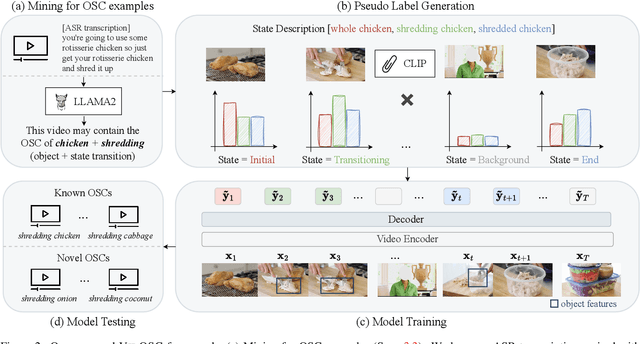
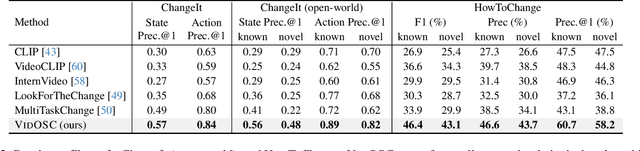
Object State Changes (OSCs) are pivotal for video understanding. While humans can effortlessly generalize OSC understanding from familiar to unknown objects, current approaches are confined to a closed vocabulary. Addressing this gap, we introduce a novel open-world formulation for the video OSC problem. The goal is to temporally localize the three stages of an OSC -- the object's initial state, its transitioning state, and its end state -- whether or not the object has been observed during training. Towards this end, we develop VidOSC, a holistic learning approach that: (1) leverages text and vision-language models for supervisory signals to obviate manually labeling OSC training data, and (2) abstracts fine-grained shared state representations from objects to enhance generalization. Furthermore, we present HowToChange, the first open-world benchmark for video OSC localization, which offers an order of magnitude increase in the label space and annotation volume compared to the best existing benchmark. Experimental results demonstrate the efficacy of our approach, in both traditional closed-world and open-world scenarios.