 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo multimodal models imagine electric sheep?
May 10, 2026Yes. We find that large multimodal models develop mental imagery when solving spatial puzzles, and they do imagine sheep when solving sheep puzzles. We fine-tune a Qwen3.5 VLM to solve twelve diverse visual reasoning tasks -- including tangram, jigsaw, sokoban, 3D mental rotation, and rush hour -- that require understanding geometry, spatial relationships, and the consequences of actions. By supervising the model to predict the open-loop sequence of actions to solve a puzzle from an initial state, we show that the model's activations after each action encode meaningful visual information about the intermediate state. This finding suggests that an imperfect visual world model begins to form as a byproduct of learning to select correct actions, in the absence of any explicit visual supervision. Building on this observation, we propose two ways to sharpen and use the mental images formed by the model. We find that integrating as few as sixteen visual tokens per step into the chain of thought improves the average solve rate from 83% to 89%, with particularly strong gains on reasoning-heavy tasks such as jigsaw and 3D mental rotation.
Does Spatial Cognition Emerge in Frontier Models?
Oct 09, 2024Not yet. We present SPACE, a benchmark that systematically evaluates spatial cognition in frontier models. Our benchmark builds on decades of research in cognitive science. It evaluates large-scale mapping abilities that are brought to bear when an organism traverses physical environments, smaller-scale reasoning about object shapes and layouts, and cognitive infrastructure such as spatial attention and memory. For many tasks, we instantiate parallel presentations via text and images, allowing us to benchmark both large language models and large multimodal models. Results suggest that contemporary frontier models fall short of the spatial intelligence of animals, performing near chance level on a number of classic tests of animal cognition.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
Video-Mined Task Graphs for Keystep Recognition in Instructional Videos
Jul 17, 2023



Procedural activity understanding requires perceiving human actions in terms of a broader task, where multiple keysteps are performed in sequence across a long video to reach a final goal state -- such as the steps of a recipe or a DIY fix-it task. Prior work largely treats keystep recognition in isolation of this broader structure, or else rigidly confines keysteps to align with a predefined sequential script. We propose discovering a task graph automatically from how-to videos to represent probabilistically how people tend to execute keysteps, and then leverage this graph to regularize keystep recognition in novel videos. On multiple datasets of real-world instructional videos, we show the impact: more reliable zero-shot keystep localization and improved video representation learning, exceeding the state of the art.
SpotEM: Efficient Video Search for Episodic Memory
Jun 28, 2023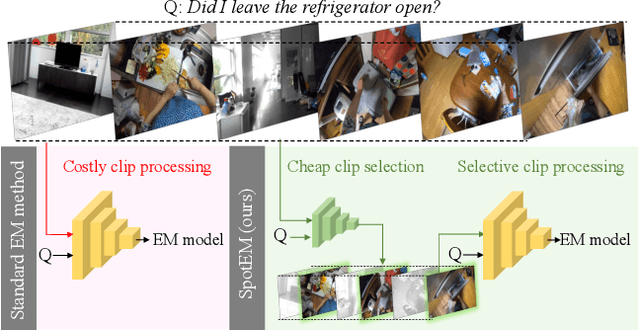
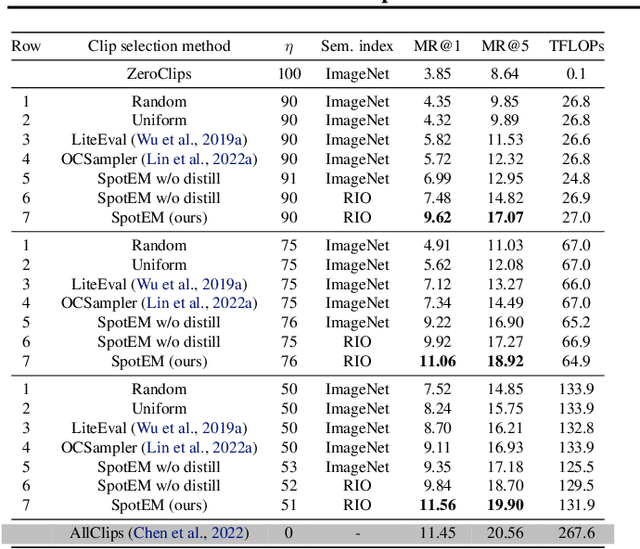
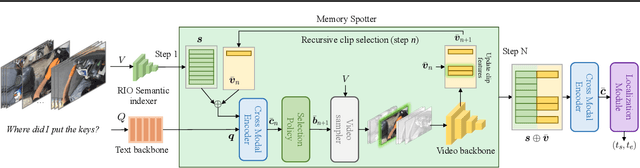
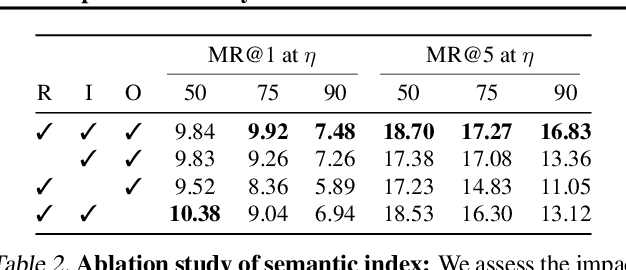
The goal in episodic memory (EM) is to search a long egocentric video to answer a natural language query (e.g., "where did I leave my purse?"). Existing EM methods exhaustively extract expensive fixed-length clip features to look everywhere in the video for the answer, which is infeasible for long wearable-camera videos that span hours or even days. We propose SpotEM, an approach to achieve efficiency for a given EM method while maintaining good accuracy. SpotEM consists of three key ideas: 1) a novel clip selector that learns to identify promising video regions to search conditioned on the language query; 2) a set of low-cost semantic indexing features that capture the context of rooms, objects, and interactions that suggest where to look; and 3) distillation losses that address the optimization issues arising from end-to-end joint training of the clip selector and EM model. Our experiments on 200+ hours of video from the Ego4D EM Natural Language Queries benchmark and three different EM models demonstrate the effectiveness of our approach: computing only 10% - 25% of the clip features, we preserve 84% - 97% of the original EM model's accuracy. Project page: https://vision.cs.utexas.edu/projects/spotem
Single-Stage Visual Query Localization in Egocentric Videos
Jun 15, 2023
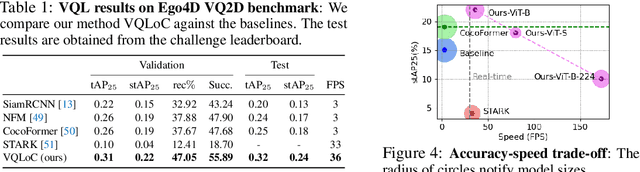
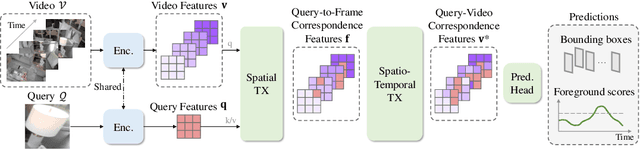
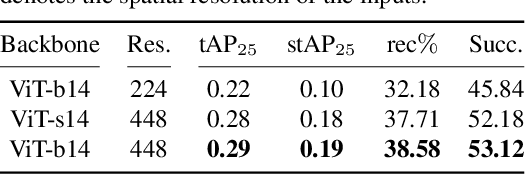
Visual Query Localization on long-form egocentric videos requires spatio-temporal search and localization of visually specified objects and is vital to build episodic memory systems. Prior work develops complex multi-stage pipelines that leverage well-established object detection and tracking methods to perform VQL. However, each stage is independently trained and the complexity of the pipeline results in slow inference speeds. We propose VQLoC, a novel single-stage VQL framework that is end-to-end trainable. Our key idea is to first build a holistic understanding of the query-video relationship and then perform spatio-temporal localization in a single shot manner. Specifically, we establish the query-video relationship by jointly considering query-to-frame correspondences between the query and each video frame and frame-to-frame correspondences between nearby video frames. Our experiments demonstrate that our approach outperforms prior VQL methods by 20% accuracy while obtaining a 10x improvement in inference speed. VQLoC is also the top entry on the Ego4D VQ2D challenge leaderboard. Project page: https://hwjiang1510.github.io/VQLoC/
A Domain-Agnostic Approach for Characterization of Lifelong Learning Systems
Jan 18, 2023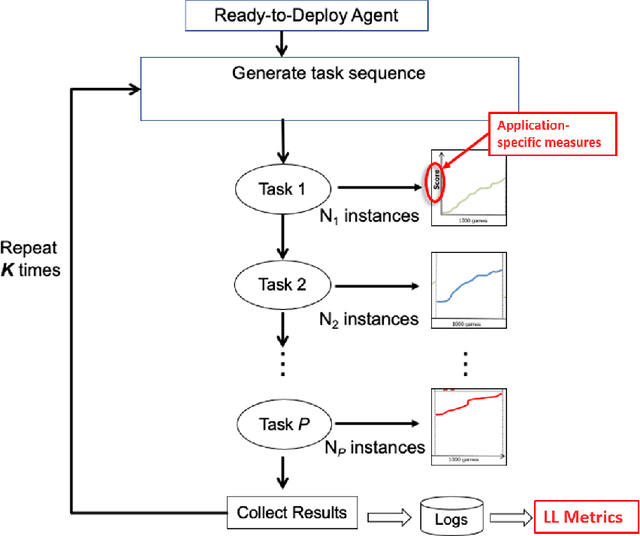


Despite the advancement of machine learning techniques in recent years, state-of-the-art systems lack robustness to "real world" events, where the input distributions and tasks encountered by the deployed systems will not be limited to the original training context, and systems will instead need to adapt to novel distributions and tasks while deployed. This critical gap may be addressed through the development of "Lifelong Learning" systems that are capable of 1) Continuous Learning, 2) Transfer and Adaptation, and 3) Scalability. Unfortunately, efforts to improve these capabilities are typically treated as distinct areas of research that are assessed independently, without regard to the impact of each separate capability on other aspects of the system. We instead propose a holistic approach, using a suite of metrics and an evaluation framework to assess Lifelong Learning in a principled way that is agnostic to specific domains or system techniques. Through five case studies, we show that this suite of metrics can inform the development of varied and complex Lifelong Learning systems. We highlight how the proposed suite of metrics quantifies performance trade-offs present during Lifelong Learning system development - both the widely discussed Stability-Plasticity dilemma and the newly proposed relationship between Sample Efficient and Robust Learning. Further, we make recommendations for the formulation and use of metrics to guide the continuing development of Lifelong Learning systems and assess their progress in the future.
NaQ: Leveraging Narrations as Queries to Supervise Episodic Memory
Jan 02, 2023



Searching long egocentric videos with natural language queries (NLQ) has compelling applications in augmented reality and robotics, where a fluid index into everything that a person (agent) has seen before could augment human memory and surface relevant information on demand. However, the structured nature of the learning problem (free-form text query inputs, localized video temporal window outputs) and its needle-in-a-haystack nature makes it both technically challenging and expensive to supervise. We introduce Narrations-as-Queries (NaQ), a data augmentation strategy that transforms standard video-text narrations into training data for a video query localization model. Validating our idea on the Ego4D benchmark, we find it has tremendous impact in practice. NaQ improves multiple top models by substantial margins (even doubling their accuracy), and yields the very best results to date on the Ego4D NLQ challenge, soundly outperforming all challenge winners in the CVPR and ECCV 2022 competitions and topping the current public leaderboard. Beyond achieving the state-of-the-art for NLQ, we also demonstrate unique properties of our approach such as gains on long-tail object queries, and the ability to perform zero-shot and few-shot NLQ.
Habitat-Matterport 3D Semantics Dataset
Oct 11, 2022
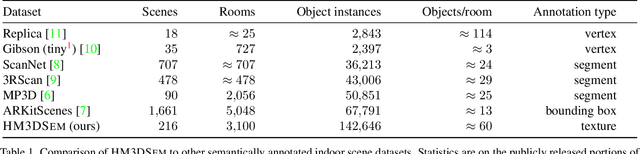

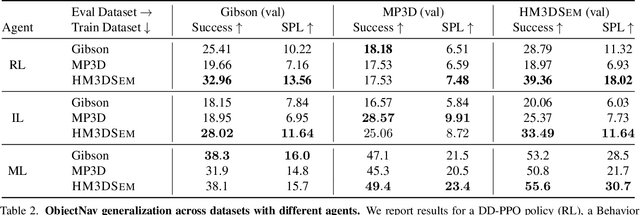
We present the Habitat-Matterport 3D Semantics (HM3DSEM) dataset. HM3DSEM is the largest dataset of 3D real-world spaces with densely annotated semantics that is currently available to the academic community. It consists of 142,646 object instance annotations across 216 3D spaces and 3,100 rooms within those spaces. The scale, quality, and diversity of object annotations far exceed those of datasets from prior work. A key difference setting apart HM3DSEM from other datasets is the use of texture information to annotate pixel-accurate object boundaries. We demonstrate the effectiveness of HM3DSEM dataset for the Object Goal Navigation task using different methods. Policies trained using HM3DSEM perform comparable or better than those trained on prior datasets.
Egocentric scene context for human-centric environment understanding from video
Jul 22, 2022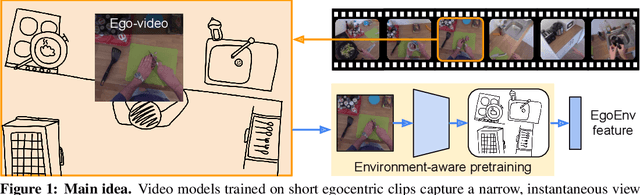
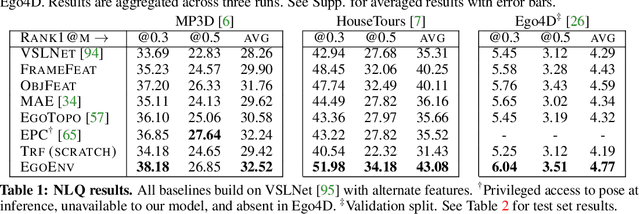
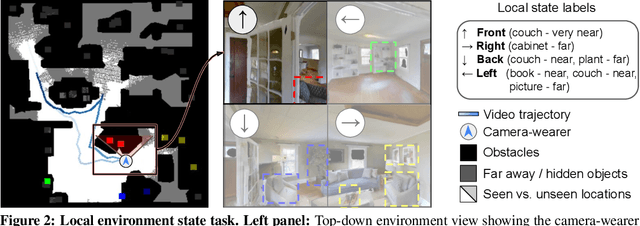
First-person video highlights a camera-wearer's activities in the context of their persistent environment. However, current video understanding approaches reason over visual features from short video clips that are detached from the underlying physical space and only capture what is directly seen. We present an approach that links egocentric video and camera pose over time by learning representations that are predictive of the camera-wearer's (potentially unseen) local surroundings to facilitate human-centric environment understanding. We train such models using videos from agents in simulated 3D environments where the environment is fully observable, and test them on real-world videos of house tours from unseen environments. We show that by grounding videos in their physical environment, our models surpass traditional scene classification models at predicting which room a camera-wearer is in (where frame-level information is insufficient), and can leverage this grounding to localize video moments corresponding to environment-centric queries, outperforming prior methods. Project page: http://vision.cs.utexas.edu/projects/ego-scene-context/