 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanNOVA: Photorealistic, Universal and Rapid 3D Human Avatar Modeling from a Single Image
Jun 01, 2026In this paper, we present HumanNOVA, a photorealistic, universal, and rapid model for generating 3D human avatars from a single RGB image. Achieving both photorealism and generalization is challenging due to the scarcity of diverse, high-quality 3D human data. To address this, we build a scalable data generation pipeline that follows two strategies. The first one is to leverage existing rigged assets and animate them with extensive poses from daily life. The second strategy is to utilize existing multi-camera captures of humans and employ fitting to generate more diverse views for training. These two strategies enable us to scale up to 100k assets, significantly enhancing both the quantity and the diversity of data for robust model training. In terms of the architecture, HumanNOVA adopts a feed-forward, token-conditioned avatar modeling framework that allows fast inference in less than one second and requires no test-time optimization. Given an input image and an estimated simplified human mesh (SMPL) without detailed geometry or appearance, the model first encodes both inputs into compact token representations. These tokens then act as conditioning signals and are fused through cross-attention to construct a triplane-based 3D avatar representation. Extensive experiments on multiple benchmarks demonstrate the superiority of our approach, both quantitatively and qualitatively, as well as its robustness under diverse input image conditions. Project page at https://HumanNOVA.github.io .
MotiMotion: Motion-Controlled Video Generation with Visual Reasoning
May 21, 2026Current motion-controlled image-to-video generation models rigidly follow user-provided trajectories that are often sparse, imprecise, and causally incomplete. Such reliance often yields unnatural or implausible outcomes, especially by missing secondary causal consequences. To address this, we introduce MotiMotion, a novel framework that reformulates motion control as a reasoning-then-generation problem. To encourage causally grounded and commonsense-consistent interactions, we leverage a training-free vision-language reasoner to refine image-space coordinates of primary trajectories and to hallucinate plausible secondary motions. To further improve motion naturalness, we propose a confidence-aware control scheme that modulates guidance strength, enabling the model to closely follow high-confidence plans while correcting artifacts under low-confidence inputs with its internal generative priors. To support systematic evaluation, we curate a new image-to-video benchmark, MotiBench, consisting of interaction-centric scenes where new events are triggered by motion. Both VLM-based evaluation and a human study on MotiBench demonstrate that MotiMotion produces videos with more plausible object behaviors and interaction, and is preferred over existing approaches.
Mining Attribute Subspaces for Efficient Fine-tuning of 3D Foundation Models
Apr 11, 2026With the emergence of 3D foundation models, there is growing interest in fine-tuning them for downstream tasks, where LoRA is the dominant fine-tuning paradigm. As 3D datasets exhibit distinct variations in texture, geometry, camera motion, and lighting, there are interesting fundamental questions: 1) Are there LoRA subspaces associated with each type of variation? 2) Are these subspaces disentangled (i.e., orthogonal to each other)? 3) How do we compute them effectively? This paper provides answers to all these questions. We introduce a robust approach that generates synthetic datasets with controlled variations, fine-tunes a LoRA adapter on each dataset, and extracts a LoRA sub-space associated with each type of variation. We show that these subspaces are approximately disentangled. Integrating them leads to a reduced LoRA subspace that enables efficient LoRA fine-tuning with improved prediction accuracy for downstream tasks. In particular, we show that such a reduced LoRA subspace, despite being derived entirely from synthetic data, generalizes to real datasets. An ablation study validates the effectiveness of the choices in our approach.
Spherical Leech Quantization for Visual Tokenization and Generation
Dec 16, 2025



Non-parametric quantization has received much attention due to its efficiency on parameters and scalability to a large codebook. In this paper, we present a unified formulation of different non-parametric quantization methods through the lens of lattice coding. The geometry of lattice codes explains the necessity of auxiliary loss terms when training auto-encoders with certain existing lookup-free quantization variants such as BSQ. As a step forward, we explore a few possible candidates, including random lattices, generalized Fibonacci lattices, and densest sphere packing lattices. Among all, we find the Leech lattice-based quantization method, which is dubbed as Spherical Leech Quantization ($Λ_{24}$-SQ), leads to both a simplified training recipe and an improved reconstruction-compression tradeoff thanks to its high symmetry and even distribution on the hypersphere. In image tokenization and compression tasks, this quantization approach achieves better reconstruction quality across all metrics than BSQ, the best prior art, while consuming slightly fewer bits. The improvement also extends to state-of-the-art auto-regressive image generation frameworks.
E-RayZer: Self-supervised 3D Reconstruction as Spatial Visual Pre-training
Dec 11, 2025



Self-supervised pre-training has revolutionized foundation models for languages, individual 2D images and videos, but remains largely unexplored for learning 3D-aware representations from multi-view images. In this paper, we present E-RayZer, a self-supervised large 3D Vision model that learns truly 3D-aware representations directly from unlabeled images. Unlike prior self-supervised methods such as RayZer that infer 3D indirectly through latent-space view synthesis, E-RayZer operates directly in 3D space, performing self-supervised 3D reconstruction with Explicit geometry. This formulation eliminates shortcut solutions and yields representations that are geometrically grounded. To ensure convergence and scalability, we introduce a novel fine-grained learning curriculum that organizes training from easy to hard samples and harmonizes heterogeneous data sources in an entirely unsupervised manner. Experiments demonstrate that E-RayZer significantly outperforms RayZer on pose estimation, matches or sometimes surpasses fully supervised reconstruction models such as VGGT. Furthermore, its learned representations outperform leading visual pre-training models (e.g., DINOv3, CroCo v2, VideoMAE V2, and RayZer) when transferring to 3D downstream tasks, establishing E-RayZer as a new paradigm for 3D-aware visual pre-training.
WorldReel: 4D Video Generation with Consistent Geometry and Motion Modeling
Dec 08, 2025Recent video generators achieve striking photorealism, yet remain fundamentally inconsistent in 3D. We present WorldReel, a 4D video generator that is natively spatio-temporally consistent. WorldReel jointly produces RGB frames together with 4D scene representations, including pointmaps, camera trajectory, and dense flow mapping, enabling coherent geometry and appearance modeling over time. Our explicit 4D representation enforces a single underlying scene that persists across viewpoints and dynamic content, yielding videos that remain consistent even under large non-rigid motion and significant camera movement. We train WorldReel by carefully combining synthetic and real data: synthetic data providing precise 4D supervision (geometry, motion, and camera), while real videos contribute visual diversity and realism. This blend allows WorldReel to generalize to in-the-wild footage while preserving strong geometric fidelity. Extensive experiments demonstrate that WorldReel sets a new state-of-the-art for consistent video generation with dynamic scenes and moving cameras, improving metrics of geometric consistency, motion coherence, and reducing view-time artifacts over competing methods. We believe that WorldReel brings video generation closer to 4D-consistent world modeling, where agents can render, interact, and reason about scenes through a single and stable spatiotemporal representation.
RayZer: A Self-supervised Large View Synthesis Model
May 01, 2025



We present RayZer, a self-supervised multi-view 3D Vision model trained without any 3D supervision, i.e., camera poses and scene geometry, while exhibiting emerging 3D awareness. Concretely, RayZer takes unposed and uncalibrated images as input, recovers camera parameters, reconstructs a scene representation, and synthesizes novel views. During training, RayZer relies solely on its self-predicted camera poses to render target views, eliminating the need for any ground-truth camera annotations and allowing RayZer to be trained with 2D image supervision. The emerging 3D awareness of RayZer is attributed to two key factors. First, we design a self-supervised framework, which achieves 3D-aware auto-encoding of input images by disentangling camera and scene representations. Second, we design a transformer-based model in which the only 3D prior is the ray structure, connecting camera, pixel, and scene simultaneously. RayZer demonstrates comparable or even superior novel view synthesis performance than ``oracle'' methods that rely on pose annotations in both training and testing. Project: https://hwjiang1510.github.io/RayZer/
MegaSynth: Scaling Up 3D Scene Reconstruction with Synthesized Data
Dec 18, 2024



We propose scaling up 3D scene reconstruction by training with synthesized data. At the core of our work is MegaSynth, a procedurally generated 3D dataset comprising 700K scenes - over 50 times larger than the prior real dataset DL3DV - dramatically scaling the training data. To enable scalable data generation, our key idea is eliminating semantic information, removing the need to model complex semantic priors such as object affordances and scene composition. Instead, we model scenes with basic spatial structures and geometry primitives, offering scalability. Besides, we control data complexity to facilitate training while loosely aligning it with real-world data distribution to benefit real-world generalization. We explore training LRMs with both MegaSynth and available real data. Experiment results show that joint training or pre-training with MegaSynth improves reconstruction quality by 1.2 to 1.8 dB PSNR across diverse image domains. Moreover, models trained solely on MegaSynth perform comparably to those trained on real data, underscoring the low-level nature of 3D reconstruction. Additionally, we provide an in-depth analysis of MegaSynth's properties for enhancing model capability, training stability, and generalization.
LVSM: A Large View Synthesis Model with Minimal 3D Inductive Bias
Oct 22, 2024



We propose the Large View Synthesis Model (LVSM), a novel transformer-based approach for scalable and generalizable novel view synthesis from sparse-view inputs. We introduce two architectures: (1) an encoder-decoder LVSM, which encodes input image tokens into a fixed number of 1D latent tokens, functioning as a fully learned scene representation, and decodes novel-view images from them; and (2) a decoder-only LVSM, which directly maps input images to novel-view outputs, completely eliminating intermediate scene representations. Both models bypass the 3D inductive biases used in previous methods -- from 3D representations (e.g., NeRF, 3DGS) to network designs (e.g., epipolar projections, plane sweeps) -- addressing novel view synthesis with a fully data-driven approach. While the encoder-decoder model offers faster inference due to its independent latent representation, the decoder-only LVSM achieves superior quality, scalability, and zero-shot generalization, outperforming previous state-of-the-art methods by 1.5 to 3.5 dB PSNR. Comprehensive evaluations across multiple datasets demonstrate that both LVSM variants achieve state-of-the-art novel view synthesis quality. Notably, our models surpass all previous methods even with reduced computational resources (1-2 GPUs). Please see our website for more details: https://haian-jin.github.io/projects/LVSM/ .
Atlas Gaussians Diffusion for 3D Generation with Infinite Number of Points
Aug 23, 2024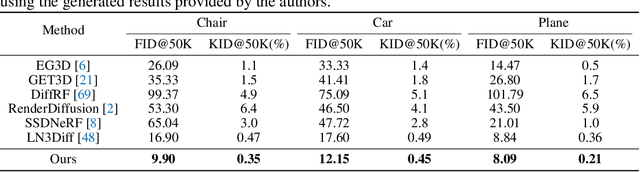
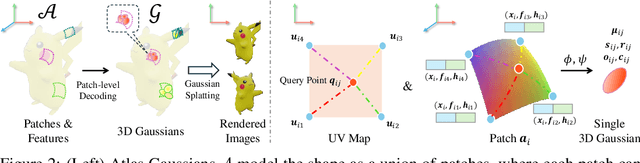
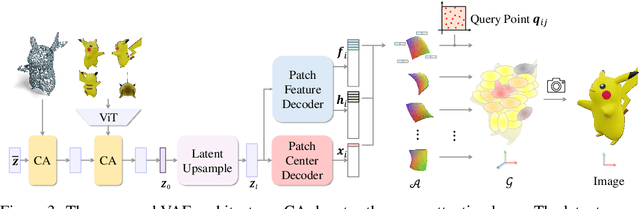
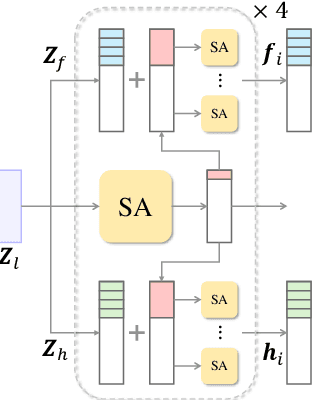
Using the latent diffusion model has proven effective in developing novel 3D generation techniques. To harness the latent diffusion model, a key challenge is designing a high-fidelity and efficient representation that links the latent space and the 3D space. In this paper, we introduce Atlas Gaussians, a novel representation for feed-forward native 3D generation. Atlas Gaussians represent a shape as the union of local patches, and each patch can decode 3D Gaussians. We parameterize a patch as a sequence of feature vectors and design a learnable function to decode 3D Gaussians from the feature vectors. In this process, we incorporate UV-based sampling, enabling the generation of a sufficiently large, and theoretically infinite, number of 3D Gaussian points. The large amount of 3D Gaussians enables high-quality details of generation results. Moreover, due to local awareness of the representation, the transformer-based decoding procedure operates on a patch level, ensuring efficiency. We train a variational autoencoder to learn the Atlas Gaussians representation, and then apply a latent diffusion model on its latent space for learning 3D Generation. Experiments show that our approach outperforms the prior arts of feed-forward native 3D generation.