 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIPS: Text-Image Pretraining with Spatial Awareness
Oct 21, 2024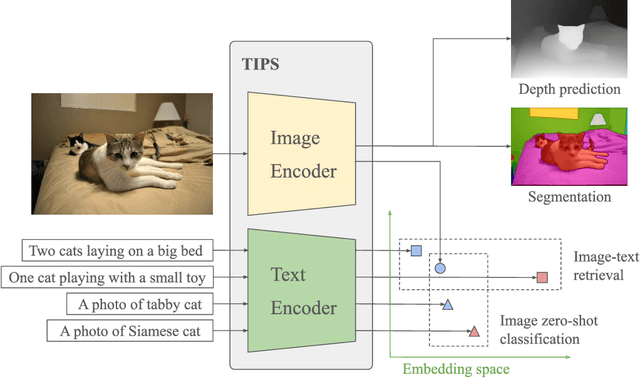
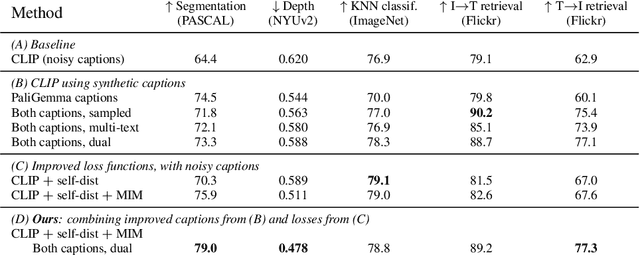
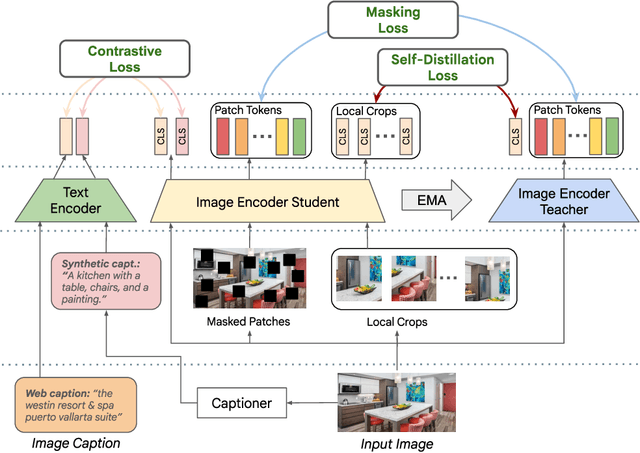
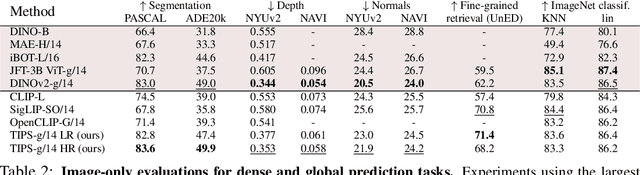
While image-text representation learning has become very popular in recent years, existing models tend to lack spatial awareness and have limited direct applicability for dense understanding tasks. For this reason, self-supervised image-only pretraining is still the go-to method for many dense vision applications (e.g. depth estimation, semantic segmentation), despite the lack of explicit supervisory signals. In this paper, we close this gap between image-text and self-supervised learning, by proposing a novel general-purpose image-text model, which can be effectively used off-the-shelf for dense and global vision tasks. Our method, which we refer to as Text-Image Pretraining with Spatial awareness (TIPS), leverages two simple and effective insights. First, on textual supervision: we reveal that replacing noisy web image captions by synthetically generated textual descriptions boosts dense understanding performance significantly, due to a much richer signal for learning spatially aware representations. We propose an adapted training method that combines noisy and synthetic captions, resulting in improvements across both dense and global understanding tasks. Second, on the learning technique: we propose to combine contrastive image-text learning with self-supervised masked image modeling, to encourage spatial coherence, unlocking substantial enhancements for downstream applications. Building on these two ideas, we scale our model using the transformer architecture, trained on a curated set of public images. Our experiments are conducted on 8 tasks involving 16 datasets in total, demonstrating strong off-the-shelf performance on both dense and global understanding, for several image-only and image-text tasks.
OmniGlue: Generalizable Feature Matching with Foundation Model Guidance
May 21, 2024The image matching field has been witnessing a continuous emergence of novel learnable feature matching techniques, with ever-improving performance on conventional benchmarks. However, our investigation shows that despite these gains, their potential for real-world applications is restricted by their limited generalization capabilities to novel image domains. In this paper, we introduce OmniGlue, the first learnable image matcher that is designed with generalization as a core principle. OmniGlue leverages broad knowledge from a vision foundation model to guide the feature matching process, boosting generalization to domains not seen at training time. Additionally, we propose a novel keypoint position-guided attention mechanism which disentangles spatial and appearance information, leading to enhanced matching descriptors. We perform comprehensive experiments on a suite of $7$ datasets with varied image domains, including scene-level, object-centric and aerial images. OmniGlue's novel components lead to relative gains on unseen domains of $20.9\%$ with respect to a directly comparable reference model, while also outperforming the recent LightGlue method by $9.5\%$ relatively.Code and model can be found at https://hwjiang1510.github.io/OmniGlue
Global Features are All You Need for Image Retrieval and Reranking
Aug 19, 2023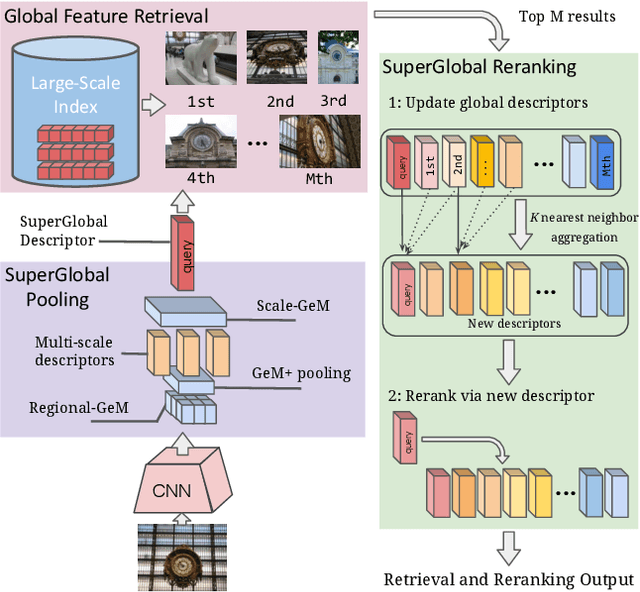
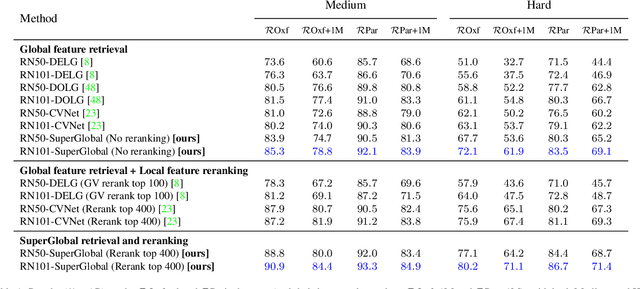
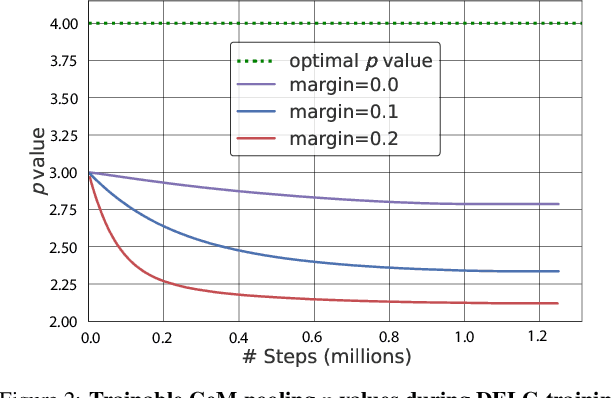

Image retrieval systems conventionally use a two-stage paradigm, leveraging global features for initial retrieval and local features for reranking. However, the scalability of this method is often limited due to the significant storage and computation cost incurred by local feature matching in the reranking stage. In this paper, we present SuperGlobal, a novel approach that exclusively employs global features for both stages, improving efficiency without sacrificing accuracy. SuperGlobal introduces key enhancements to the retrieval system, specifically focusing on the global feature extraction and reranking processes. For extraction, we identify sub-optimal performance when the widely-used ArcFace loss and Generalized Mean (GeM) pooling methods are combined and propose several new modules to improve GeM pooling. In the reranking stage, we introduce a novel method to update the global features of the query and top-ranked images by only considering feature refinement with a small set of images, thus being very compute and memory efficient. Our experiments demonstrate substantial improvements compared to the state of the art in standard benchmarks. Notably, on the Revisited Oxford+1M Hard dataset, our single-stage results improve by 7.1%, while our two-stage gain reaches 3.7% with a strong 64,865x speedup. Our two-stage system surpasses the current single-stage state-of-the-art by 16.3%, offering a scalable, accurate alternative for high-performing image retrieval systems with minimal time overhead. Code: https://github.com/ShihaoShao-GH/SuperGlobal.
NAVI: Category-Agnostic Image Collections with High-Quality 3D Shape and Pose Annotations
Jun 15, 2023



Recent advances in neural reconstruction enable high-quality 3D object reconstruction from casually captured image collections. Current techniques mostly analyze their progress on relatively simple image collections where Structure-from-Motion (SfM) techniques can provide ground-truth (GT) camera poses. We note that SfM techniques tend to fail on in-the-wild image collections such as image search results with varying backgrounds and illuminations. To enable systematic research progress on 3D reconstruction from casual image captures, we propose NAVI: a new dataset of category-agnostic image collections of objects with high-quality 3D scans along with per-image 2D-3D alignments providing near-perfect GT camera parameters. These 2D-3D alignments allow us to extract accurate derivative annotations such as dense pixel correspondences, depth and segmentation maps. We demonstrate the use of NAVI image collections on different problem settings and show that NAVI enables more thorough evaluations that were not possible with existing datasets. We believe NAVI is beneficial for systematic research progress on 3D reconstruction and correspondence estimation. Project page: https://navidataset.github.io
LFM-3D: Learnable Feature Matching Across Wide Baselines Using 3D Signals
Mar 22, 2023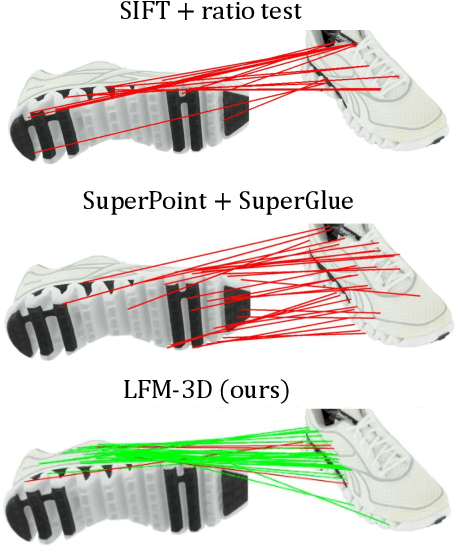
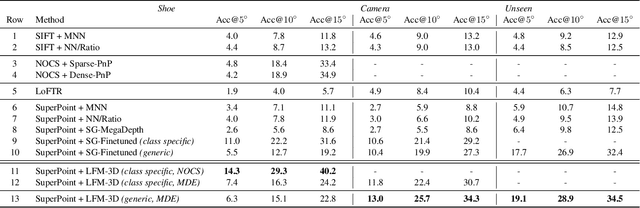
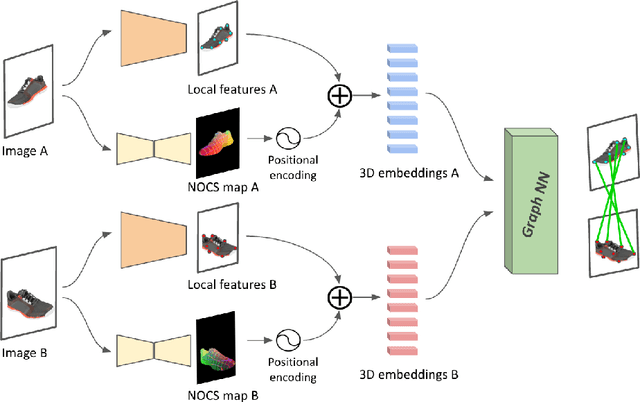
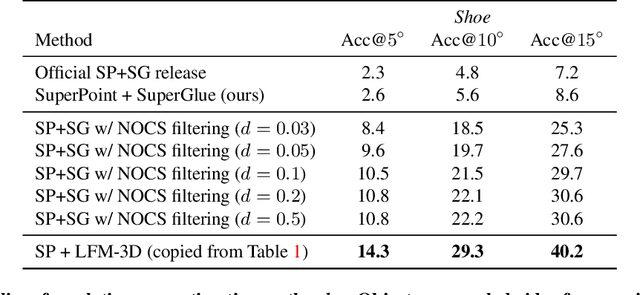
Finding localized correspondences across different images of the same object is crucial to understand its geometry. In recent years, this problem has seen remarkable progress with the advent of deep learning based local image features and learnable matchers. Still, learnable matchers often underperform when there exists only small regions of co-visibility between image pairs (i.e. wide camera baselines). To address this problem, we leverage recent progress in coarse single-view geometry estimation methods. We propose LFM-3D, a Learnable Feature Matching framework that uses models based on graph neural networks, and enhances their capabilities by integrating noisy, estimated 3D signals to boost correspondence estimation. When integrating 3D signals into the matcher model, we show that a suitable positional encoding is critical to effectively make use of the low-dimensional 3D information. We experiment with two different 3D signals - normalized object coordinates and monocular depth estimates - and evaluate our method on large-scale (synthetic and real) datasets containing object-centric image pairs across wide baselines. We observe strong feature matching improvements compared to 2D-only methods, with up to +6% total recall and +28% precision at fixed recall. We additionally demonstrate that the resulting improved correspondences lead to much higher relative posing accuracy for in-the-wild image pairs, with a more than 8% boost compared to the 2D-only approach.
Nutrition5k: Towards Automatic Nutritional Understanding of Generic Food
Mar 04, 2021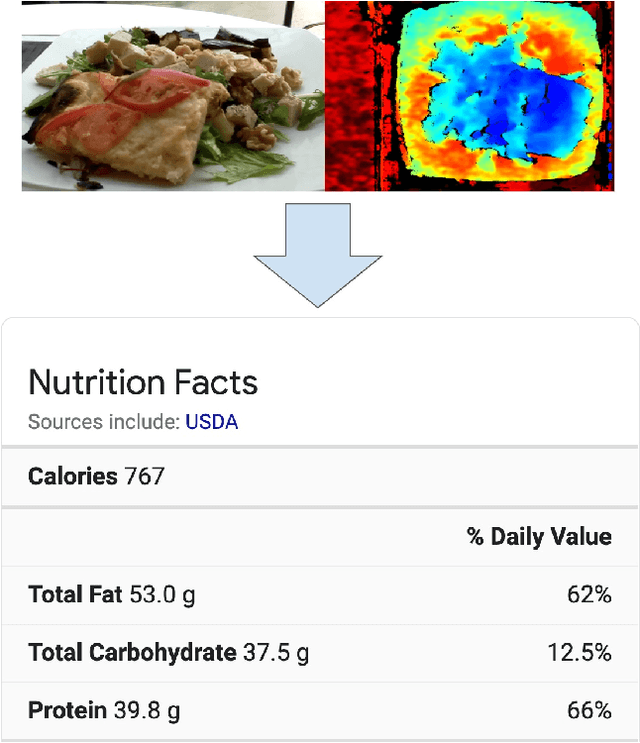
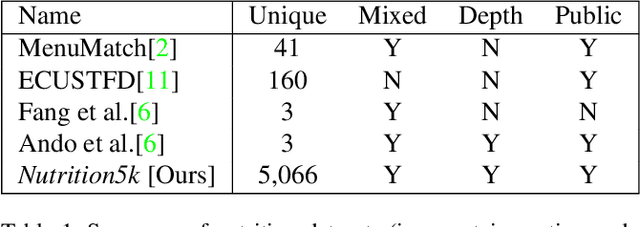

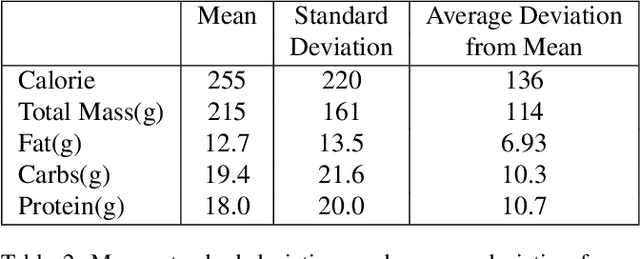
Understanding the nutritional content of food from visual data is a challenging computer vision problem, with the potential to have a positive and widespread impact on public health. Studies in this area are limited to existing datasets in the field that lack sufficient diversity or labels required for training models with nutritional understanding capability. We introduce Nutrition5k, a novel dataset of 5k diverse, real world food dishes with corresponding video streams, depth images, component weights, and high accuracy nutritional content annotation. We demonstrate the potential of this dataset by training a computer vision algorithm capable of predicting the caloric and macronutrient values of a complex, real world dish at an accuracy that outperforms professional nutritionists. Further we present a baseline for incorporating depth sensor data to improve nutrition predictions. We will publicly release Nutrition5k in the hope that it will accelerate innovation in the space of nutritional understanding.
Unsupervised Domain Adaptation for 3D Keypoint Estimation via View Consistency
Jul 26, 2018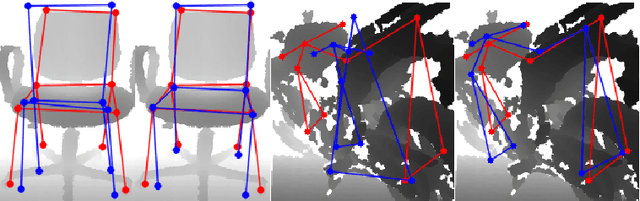

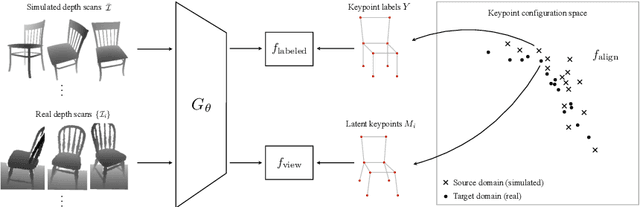
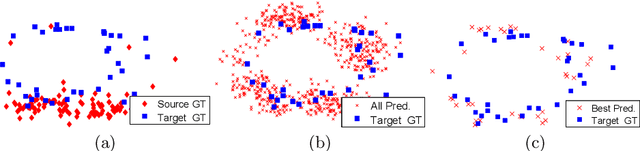
In this paper, we introduce a novel unsupervised domain adaptation technique for the task of 3D keypoint prediction from a single depth scan or image. Our key idea is to utilize the fact that predictions from different views of the same or similar objects should be consistent with each other. Such view consistency can provide effective regularization for keypoint prediction on unlabeled instances. In addition, we introduce a geometric alignment term to regularize predictions in the target domain. The resulting loss function can be effectively optimized via alternating minimization. We demonstrate the effectiveness of our approach on real datasets and present experimental results showing that our approach is superior to state-of-the-art general-purpose domain adaptation techniques.
StarMap for Category-Agnostic Keypoint and Viewpoint Estimation
Jul 26, 2018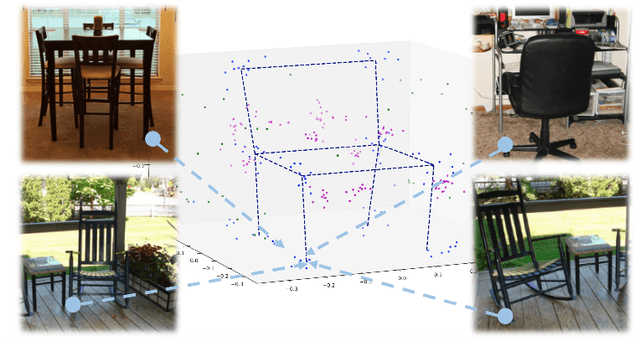
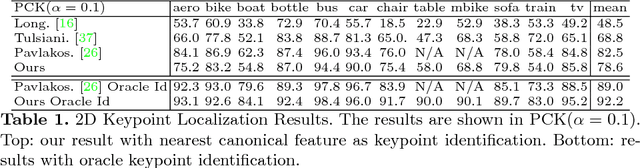
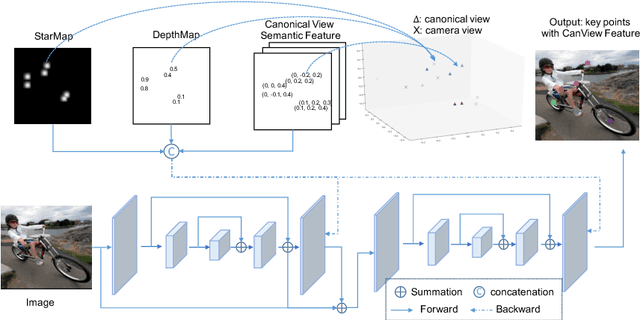
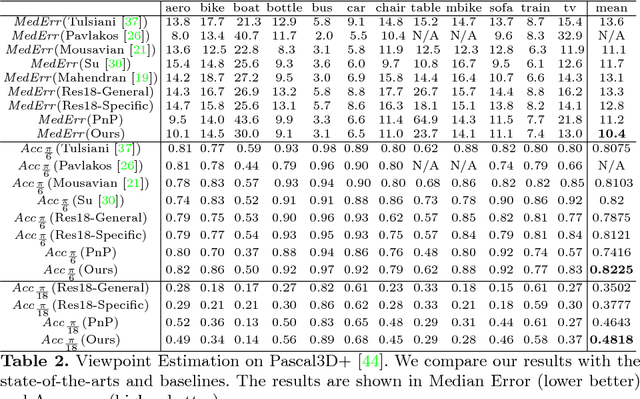
Semantic keypoints provide concise abstractions for a variety of visual understanding tasks. Existing methods define semantic keypoints separately for each category with a fixed number of semantic labels in fixed indices. As a result, this keypoint representation is in-feasible when objects have a varying number of parts, e.g. chairs with varying number of legs. We propose a category-agnostic keypoint representation, which combines a multi-peak heatmap (StarMap) for all the keypoints and their corresponding features as 3D locations in the canonical viewpoint (CanViewFeature) defined for each instance. Our intuition is that the 3D locations of the keypoints in canonical object views contain rich semantic and compositional information. Using our flexible representation, we demonstrate competitive performance in keypoint detection and localization compared to category-specific state-of-the-art methods. Moreover, we show that when augmented with an additional depth channel (DepthMap) to lift the 2D keypoints to 3D, our representation can achieve state-of-the-art results in viewpoint estimation. Finally, we show that our category-agnostic keypoint representation can be generalized to novel categories.