 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLFM-3D: Learnable Feature Matching Across Wide Baselines Using 3D Signals
Paper and Code
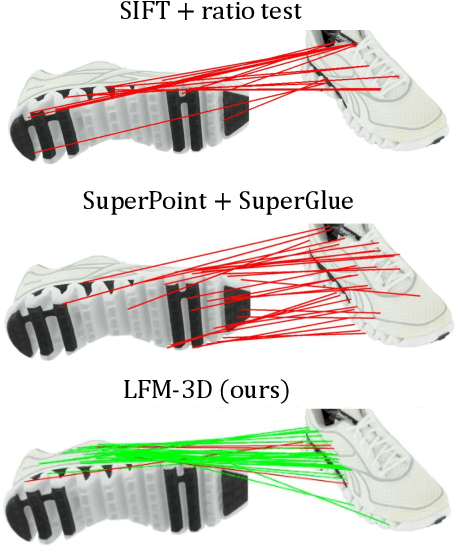
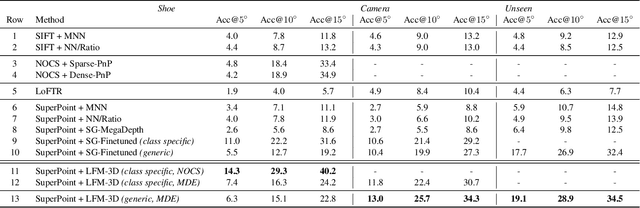
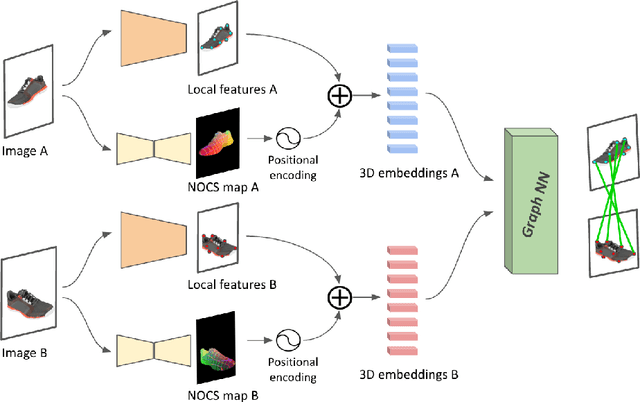
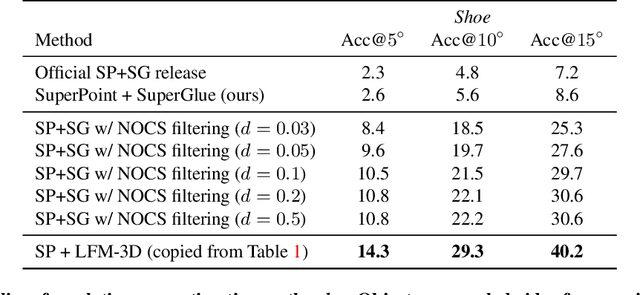
Finding localized correspondences across different images of the same object is crucial to understand its geometry. In recent years, this problem has seen remarkable progress with the advent of deep learning based local image features and learnable matchers. Still, learnable matchers often underperform when there exists only small regions of co-visibility between image pairs (i.e. wide camera baselines). To address this problem, we leverage recent progress in coarse single-view geometry estimation methods. We propose LFM-3D, a Learnable Feature Matching framework that uses models based on graph neural networks, and enhances their capabilities by integrating noisy, estimated 3D signals to boost correspondence estimation. When integrating 3D signals into the matcher model, we show that a suitable positional encoding is critical to effectively make use of the low-dimensional 3D information. We experiment with two different 3D signals - normalized object coordinates and monocular depth estimates - and evaluate our method on large-scale (synthetic and real) datasets containing object-centric image pairs across wide baselines. We observe strong feature matching improvements compared to 2D-only methods, with up to +6% total recall and +28% precision at fixed recall. We additionally demonstrate that the resulting improved correspondences lead to much higher relative posing accuracy for in-the-wild image pairs, with a more than 8% boost compared to the 2D-only approach.