 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBolt3D: Generating 3D Scenes in Seconds
Mar 18, 2025We present a latent diffusion model for fast feed-forward 3D scene generation. Given one or more images, our model Bolt3D directly samples a 3D scene representation in less than seven seconds on a single GPU. We achieve this by leveraging powerful and scalable existing 2D diffusion network architectures to produce consistent high-fidelity 3D scene representations. To train this model, we create a large-scale multiview-consistent dataset of 3D geometry and appearance by applying state-of-the-art dense 3D reconstruction techniques to existing multiview image datasets. Compared to prior multiview generative models that require per-scene optimization for 3D reconstruction, Bolt3D reduces the inference cost by a factor of up to 300 times.
Can Generative Video Models Help Pose Estimation?
Dec 20, 2024Pairwise pose estimation from images with little or no overlap is an open challenge in computer vision. Existing methods, even those trained on large-scale datasets, struggle in these scenarios due to the lack of identifiable correspondences or visual overlap. Inspired by the human ability to infer spatial relationships from diverse scenes, we propose a novel approach, InterPose, that leverages the rich priors encoded within pre-trained generative video models. We propose to use a video model to hallucinate intermediate frames between two input images, effectively creating a dense, visual transition, which significantly simplifies the problem of pose estimation. Since current video models can still produce implausible motion or inconsistent geometry, we introduce a self-consistency score that evaluates the consistency of pose predictions from sampled videos. We demonstrate that our approach generalizes among three state-of-the-art video models and show consistent improvements over the state-of-the-art DUSt3R on four diverse datasets encompassing indoor, outdoor, and object-centric scenes. Our findings suggest a promising avenue for improving pose estimation models by leveraging large generative models trained on vast amounts of video data, which is more readily available than 3D data. See our project page for results: https://inter-pose.github.io/.
Perturb-and-Revise: Flexible 3D Editing with Generative Trajectories
Dec 06, 2024



The fields of 3D reconstruction and text-based 3D editing have advanced significantly with the evolution of text-based diffusion models. While existing 3D editing methods excel at modifying color, texture, and style, they struggle with extensive geometric or appearance changes, thus limiting their applications. We propose Perturb-and-Revise, which makes possible a variety of NeRF editing. First, we perturb the NeRF parameters with random initializations to create a versatile initialization. We automatically determine the perturbation magnitude through analysis of the local loss landscape. Then, we revise the edited NeRF via generative trajectories. Combined with the generative process, we impose identity-preserving gradients to refine the edited NeRF. Extensive experiments demonstrate that Perturb-and-Revise facilitates flexible, effective, and consistent editing of color, appearance, and geometry in 3D. For 360{\deg} results, please visit our project page: https://susunghong.github.io/Perturb-and-Revise.
CAT3D: Create Anything in 3D with Multi-View Diffusion Models
May 16, 2024



Advances in 3D reconstruction have enabled high-quality 3D capture, but require a user to collect hundreds to thousands of images to create a 3D scene. We present CAT3D, a method for creating anything in 3D by simulating this real-world capture process with a multi-view diffusion model. Given any number of input images and a set of target novel viewpoints, our model generates highly consistent novel views of a scene. These generated views can be used as input to robust 3D reconstruction techniques to produce 3D representations that can be rendered from any viewpoint in real-time. CAT3D can create entire 3D scenes in as little as one minute, and outperforms existing methods for single image and few-view 3D scene creation. See our project page for results and interactive demos at https://cat3d.github.io .
CamP: Camera Preconditioning for Neural Radiance Fields
Aug 30, 2023



Neural Radiance Fields (NeRF) can be optimized to obtain high-fidelity 3D scene reconstructions of objects and large-scale scenes. However, NeRFs require accurate camera parameters as input -- inaccurate camera parameters result in blurry renderings. Extrinsic and intrinsic camera parameters are usually estimated using Structure-from-Motion (SfM) methods as a pre-processing step to NeRF, but these techniques rarely yield perfect estimates. Thus, prior works have proposed jointly optimizing camera parameters alongside a NeRF, but these methods are prone to local minima in challenging settings. In this work, we analyze how different camera parameterizations affect this joint optimization problem, and observe that standard parameterizations exhibit large differences in magnitude with respect to small perturbations, which can lead to an ill-conditioned optimization problem. We propose using a proxy problem to compute a whitening transform that eliminates the correlation between camera parameters and normalizes their effects, and we propose to use this transform as a preconditioner for the camera parameters during joint optimization. Our preconditioned camera optimization significantly improves reconstruction quality on scenes from the Mip-NeRF 360 dataset: we reduce error rates (RMSE) by 67% compared to state-of-the-art NeRF approaches that do not optimize for cameras like Zip-NeRF, and by 29% relative to state-of-the-art joint optimization approaches using the camera parameterization of SCNeRF. Our approach is easy to implement, does not significantly increase runtime, can be applied to a wide variety of camera parameterizations, and can straightforwardly be incorporated into other NeRF-like models.
NAVI: Category-Agnostic Image Collections with High-Quality 3D Shape and Pose Annotations
Jun 15, 2023



Recent advances in neural reconstruction enable high-quality 3D object reconstruction from casually captured image collections. Current techniques mostly analyze their progress on relatively simple image collections where Structure-from-Motion (SfM) techniques can provide ground-truth (GT) camera poses. We note that SfM techniques tend to fail on in-the-wild image collections such as image search results with varying backgrounds and illuminations. To enable systematic research progress on 3D reconstruction from casual image captures, we propose NAVI: a new dataset of category-agnostic image collections of objects with high-quality 3D scans along with per-image 2D-3D alignments providing near-perfect GT camera parameters. These 2D-3D alignments allow us to extract accurate derivative annotations such as dense pixel correspondences, depth and segmentation maps. We demonstrate the use of NAVI image collections on different problem settings and show that NAVI enables more thorough evaluations that were not possible with existing datasets. We believe NAVI is beneficial for systematic research progress on 3D reconstruction and correspondence estimation. Project page: https://navidataset.github.io
SCADE: NeRFs from Space Carving with Ambiguity-Aware Depth Estimates
Mar 23, 2023Neural radiance fields (NeRFs) have enabled high fidelity 3D reconstruction from multiple 2D input views. However, a well-known drawback of NeRFs is the less-than-ideal performance under a small number of views, due to insufficient constraints enforced by volumetric rendering. To address this issue, we introduce SCADE, a novel technique that improves NeRF reconstruction quality on sparse, unconstrained input views for in-the-wild indoor scenes. To constrain NeRF reconstruction, we leverage geometric priors in the form of per-view depth estimates produced with state-of-the-art monocular depth estimation models, which can generalize across scenes. A key challenge is that monocular depth estimation is an ill-posed problem, with inherent ambiguities. To handle this issue, we propose a new method that learns to predict, for each view, a continuous, multimodal distribution of depth estimates using conditional Implicit Maximum Likelihood Estimation (cIMLE). In order to disambiguate exploiting multiple views, we introduce an original space carving loss that guides the NeRF representation to fuse multiple hypothesized depth maps from each view and distill from them a common geometry that is consistent with all views. Experiments show that our approach enables higher fidelity novel view synthesis from sparse views. Our project page can be found at https://scade-spacecarving-nerfs.github.io .
LFM-3D: Learnable Feature Matching Across Wide Baselines Using 3D Signals
Mar 22, 2023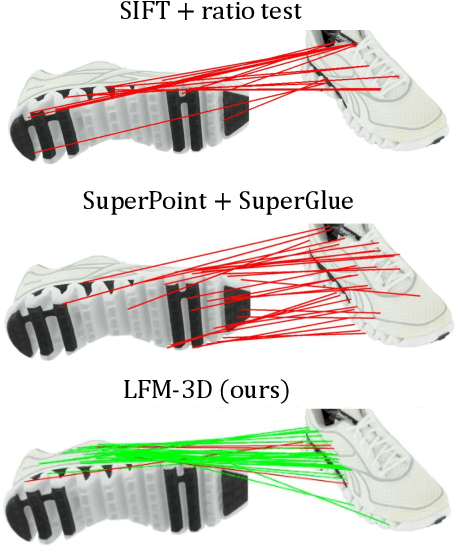
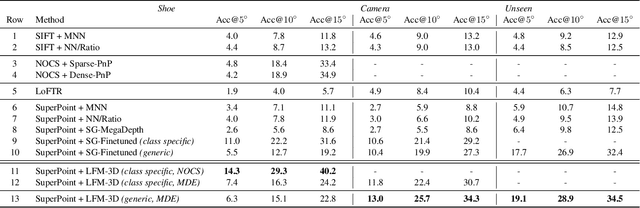
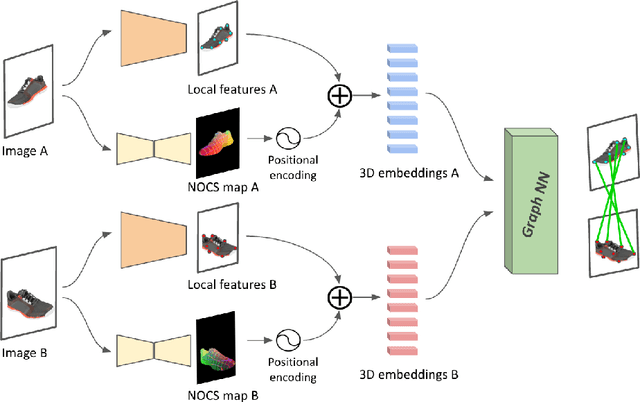
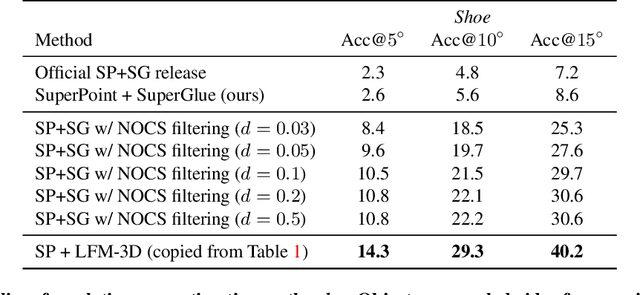
Finding localized correspondences across different images of the same object is crucial to understand its geometry. In recent years, this problem has seen remarkable progress with the advent of deep learning based local image features and learnable matchers. Still, learnable matchers often underperform when there exists only small regions of co-visibility between image pairs (i.e. wide camera baselines). To address this problem, we leverage recent progress in coarse single-view geometry estimation methods. We propose LFM-3D, a Learnable Feature Matching framework that uses models based on graph neural networks, and enhances their capabilities by integrating noisy, estimated 3D signals to boost correspondence estimation. When integrating 3D signals into the matcher model, we show that a suitable positional encoding is critical to effectively make use of the low-dimensional 3D information. We experiment with two different 3D signals - normalized object coordinates and monocular depth estimates - and evaluate our method on large-scale (synthetic and real) datasets containing object-centric image pairs across wide baselines. We observe strong feature matching improvements compared to 2D-only methods, with up to +6% total recall and +28% precision at fixed recall. We additionally demonstrate that the resulting improved correspondences lead to much higher relative posing accuracy for in-the-wild image pairs, with a more than 8% boost compared to the 2D-only approach.
Novel View Synthesis with Diffusion Models
Oct 06, 2022
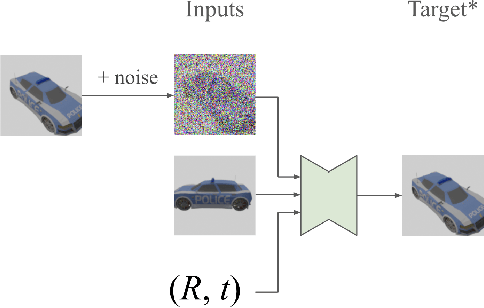
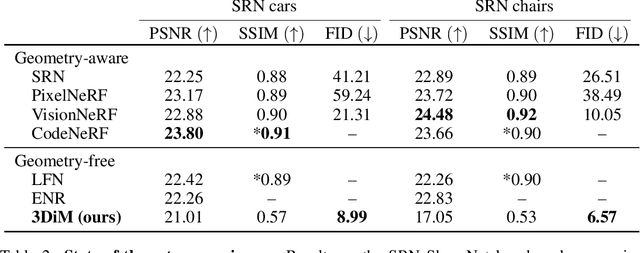
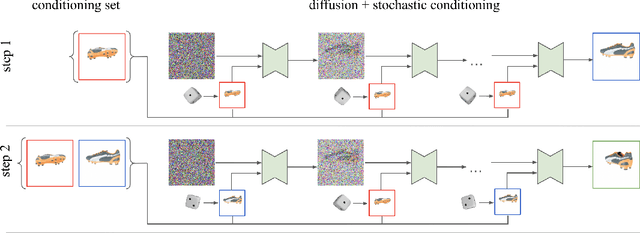
We present 3DiM, a diffusion model for 3D novel view synthesis, which is able to translate a single input view into consistent and sharp completions across many views. The core component of 3DiM is a pose-conditional image-to-image diffusion model, which takes a source view and its pose as inputs, and generates a novel view for a target pose as output. 3DiM can generate multiple views that are 3D consistent using a novel technique called stochastic conditioning. The output views are generated autoregressively, and during the generation of each novel view, one selects a random conditioning view from the set of available views at each denoising step. We demonstrate that stochastic conditioning significantly improves the 3D consistency of a naive sampler for an image-to-image diffusion model, which involves conditioning on a single fixed view. We compare 3DiM to prior work on the SRN ShapeNet dataset, demonstrating that 3DiM's generated completions from a single view achieve much higher fidelity, while being approximately 3D consistent. We also introduce a new evaluation methodology, 3D consistency scoring, to measure the 3D consistency of a generated object by training a neural field on the model's output views. 3DiM is geometry free, does not rely on hyper-networks or test-time optimization for novel view synthesis, and allows a single model to easily scale to a large number of scenes.
NeRF in the Dark: High Dynamic Range View Synthesis from Noisy Raw Images
Nov 26, 2021
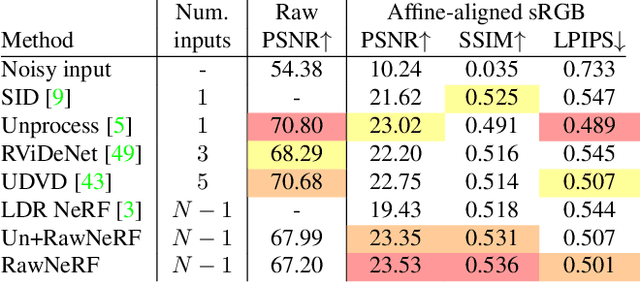
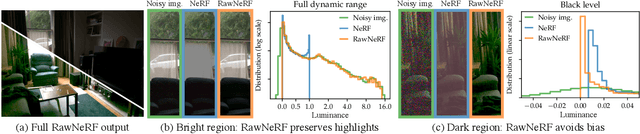
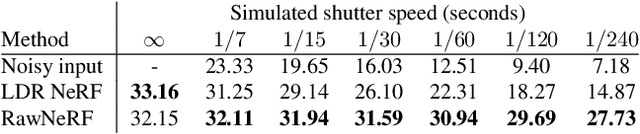
Neural Radiance Fields (NeRF) is a technique for high quality novel view synthesis from a collection of posed input images. Like most view synthesis methods, NeRF uses tonemapped low dynamic range (LDR) as input; these images have been processed by a lossy camera pipeline that smooths detail, clips highlights, and distorts the simple noise distribution of raw sensor data. We modify NeRF to instead train directly on linear raw images, preserving the scene's full dynamic range. By rendering raw output images from the resulting NeRF, we can perform novel high dynamic range (HDR) view synthesis tasks. In addition to changing the camera viewpoint, we can manipulate focus, exposure, and tonemapping after the fact. Although a single raw image appears significantly more noisy than a postprocessed one, we show that NeRF is highly robust to the zero-mean distribution of raw noise. When optimized over many noisy raw inputs (25-200), NeRF produces a scene representation so accurate that its rendered novel views outperform dedicated single and multi-image deep raw denoisers run on the same wide baseline input images. As a result, our method, which we call RawNeRF, can reconstruct scenes from extremely noisy images captured in near-darkness.