 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoney, I Shrunk the Arc de Triomphe!
Jun 01, 2026Metric scale monocular geometry estimation has seen significant progress through large-scale data aggregation, yet current foundation models suffer from a persistent ''scale-collapse'' phenomenon: distant landmarks and vast landscapes are metrically underestimated. We hypothesize that this performance gap stems from a training data bottleneck, where existing metric-scale datasets are hardware-constrained to homogenous vehicle-captured LiDAR or short-range indoor scans, or consist of synthetic data that lacks the semantic complexity of the physical world. To bridge this gap, we curate a new metrically-grounded, in-the-wild dataset that we call MetricScenes, gathered from a variety of sources including Internet photo collections and stereo imagery. We estimate camera poses and initial depth maps for each scene using off-the-shelf methods, and recover absolute scale from geo-tagged metadata as well as known stereo camera baselines. We also improve the quality of depth maps derived from MetricScenes via a new two-stage Poisson completion method. Fine-tuning MoGe-2 on our dataset significantly mitigates scale-collapse and achieves superior metric accuracy in unconstrained, open-domain scenes while maintaining state-of-the-art performance on standard benchmarks.
G3T Up! Gravity Aligned Coordinate Frames Simplify Pointmap Processing
May 26, 2026Modern feed-forward 3D reconstruction methods like VGGT predict pixel-aligned pointmaps in camera-centric coordinate frames. However, this choice of coordinate frame is not always optimal. We propose instead to predict pointmaps in upright, gravity-aligned frames that exploit strong structural cues present in many real-world scenes. Unlike camera-centric frames, gravity-aligned frames share a common vertical axis across viewpoints, reducing the rotational degrees of freedom needed to relate pointmaps to one another. To this end, we introduce the Gravity Grounded Geometry Transformer (G3T), fine-tuned from existing models on gravity-aligned 3D data. G3T produces highly accurate gravity-aware predictions, including upright pointmaps and camera-to-gravity poses. We further introduce G3T-Long, a submap-based incremental 3D reconstruction pipeline that leverages the reduced rotational degrees of freedom afforded by upright frames to achieve significantly improved reconstruction accuracy.
Flat-Pack Bench: Evaluating Spatio-Temporal Understanding in Large Vision-Language Models through Furniture Assembly
May 20, 2026The emergence of Large Vision-Language Models (LVLMs) has significantly advanced video understanding capabilities. However, existing benchmarks focus predominantly on coarse-grained tasks such as action segmentation, classification, captioning, and retrieval. Furthermore, these benchmarks often rely on entities that can be easily identified verbally, like household objects, animals, human subjects, etc., limiting their applicability to complex, in-the-wild video scenarios. But, many applications such as furniture assembly, cooking, etc., require step-by-step fine-grained spatio-temporal understanding of the video, which is not sufficiently evaluated in current benchmarks. To address this gap, we introduce Flat-Pack Bench, a novel benchmark centered on furniture assembly tasks. Our benchmark evaluates LVLMs on nuanced tasks, including temporal ordering of assembly actions, temporal localization of assembly state, understanding part mating, and tracking, using multiple-choice questions paired with visual prompts highlighting relevant parts as references for fine-grained questions. Our experiments reveal that state-of-the-art LVLMs struggle significantly with fine-grained spatio-temporal reasoning, highlighting their limitations in effectively leveraging temporal information from videos, limited tracking ability, and understanding of spatial interactions like physical contact.
Long-tail Internet photo reconstruction
Apr 24, 2026Internet photo collections exhibit an extremely long-tailed distribution: a few famous landmarks are densely photographed and easily reconstructed in 3D, while most real-world sites are represented with sparse, noisy, uneven imagery beyond the capabilities of both classical and learned 3D methods. We believe that tackling this long-tail regime represents one of the next frontiers for 3D foundation models. Although reliable ground-truth 3D supervision from sparse scenes is challenging to acquire, we observe that it can be effectively simulated by sampling sparse subsets from well-reconstructed Internet landmarks. To this end, we introduce MegaDepth-X, a large dataset of 3D reconstructions with clean, dense depth, together with a strategy for sampling sets of training images that mimic camera distributions in long-tail scenes. Finetuning 3D foundation models with these components yields robust reconstructions under extreme sparsity, and also enables more reliable reconstruction in symmetric and repetitive scenes, while preserving generalization to standard, dense 3D benchmark datasets.
ArchSym: Detecting 3D-Grounded Architectural Symmetries in the Wild
Apr 24, 2026Symmetry detection is a fundamental problem in computer vision, and symmetries serve as powerful priors for downstream tasks. However, existing learning-based methods for detecting 3D symmetries from single images have been almost exclusively trained and evaluated on object-centric or synthetic datasets, and thus fail to generalize to real-world scenes. Furthermore, due to the inherent scale ambiguity of monocular inputs, which makes localizing the 3D plane an ill-posed problem, many existing works only predict the plane's orientation. In this paper, we address these limitations by presenting the first framework for detecting 3D-grounded reflectional symmetries from single, in-the-wild RGB images, focusing on architectural landmarks. We introduce two key innovations: (1) a scalable data annotation pipeline to automatically curate a large-scale dataset of architectural symmetries, ArchSym, from SfM reconstructions by leveraging cross-view image matching; and building on the dataset, (2) a single-view symmetry detector that accurately localizes symmetries in 3D by parameterizing them as signed distance maps defined relative to predicted scene geometry. We validate our symmetry annotation pipeline against geometry-based alternatives and demonstrate that our symmetry detector significantly outperforms state-of-the-art baselines on our new benchmark.
CityRAG: Stepping Into a City via Spatially-Grounded Video Generation
Apr 21, 2026We address the problem of generating a 3D-consistent, navigable environment that is spatially grounded: a simulation of a real location. Existing video generative models can produce a plausible sequence that is consistent with a text (T2V) or image (I2V) prompt. However, the capability to reconstruct the real world under arbitrary weather conditions and dynamic object configurations is essential for downstream applications including autonomous driving and robotics simulation. To this end, we present CityRAG, a video generative model that leverages large corpora of geo-registered data as context to ground generation to the physical scene, while maintaining learned priors for complex motion and appearance changes. CityRAG relies on temporally unaligned training data, which teaches the model to semantically disentangle the underlying scene from its transient attributes. Our experiments demonstrate that CityRAG can generate coherent minutes-long, physically grounded video sequences, maintain weather and lighting conditions over thousands of frames, achieve loop closure, and navigate complex trajectories to reconstruct real-world geography.
ZipMap: Linear-Time Stateful 3D Reconstruction with Test-Time Training
Mar 04, 2026Feed-forward transformer models have driven rapid progress in 3D vision, but state-of-the-art methods such as VGGT and $π^3$ have a computational cost that scales quadratically with the number of input images, making them inefficient when applied to large image collections. Sequential-reconstruction approaches reduce this cost but sacrifice reconstruction quality. We introduce ZipMap, a stateful feed-forward model that achieves linear-time, bidirectional 3D reconstruction while matching or surpassing the accuracy of quadratic-time methods. ZipMap employs test-time training layers to zip an entire image collection into a compact hidden scene state in a single forward pass, enabling reconstruction of over 700 frames in under 10 seconds on a single H100 GPU, more than $20\times$ faster than state-of-the-art methods such as VGGT. Moreover, we demonstrate the benefits of having a stateful representation in real-time scene-state querying and its extension to sequential streaming reconstruction.
Eye2Eye: A Simple Approach for Monocular-to-Stereo Video Synthesis
Apr 30, 2025The rising popularity of immersive visual experiences has increased interest in stereoscopic 3D video generation. Despite significant advances in video synthesis, creating 3D videos remains challenging due to the relative scarcity of 3D video data. We propose a simple approach for transforming a text-to-video generator into a video-to-stereo generator. Given an input video, our framework automatically produces the video frames from a shifted viewpoint, enabling a compelling 3D effect. Prior and concurrent approaches for this task typically operate in multiple phases, first estimating video disparity or depth, then warping the video accordingly to produce a second view, and finally inpainting the disoccluded regions. This approach inherently fails when the scene involves specular surfaces or transparent objects. In such cases, single-layer disparity estimation is insufficient, resulting in artifacts and incorrect pixel shifts during warping. Our work bypasses these restrictions by directly synthesizing the new viewpoint, avoiding any intermediate steps. This is achieved by leveraging a pre-trained video model's priors on geometry, object materials, optics, and semantics, without relying on external geometry models or manually disentangling geometry from the synthesis process. We demonstrate the advantages of our approach in complex, real-world scenarios featuring diverse object materials and compositions. See videos on https://video-eye2eye.github.io
Visual Chronicles: Using Multimodal LLMs to Analyze Massive Collections of Images
Apr 14, 2025
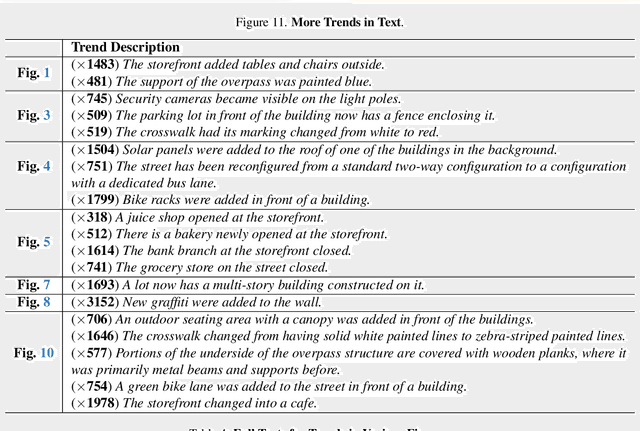


We present a system using Multimodal LLMs (MLLMs) to analyze a large database with tens of millions of images captured at different times, with the aim of discovering patterns in temporal changes. Specifically, we aim to capture frequent co-occurring changes ("trends") across a city over a certain period. Unlike previous visual analyses, our analysis answers open-ended queries (e.g., "what are the frequent types of changes in the city?") without any predetermined target subjects or training labels. These properties cast prior learning-based or unsupervised visual analysis tools unsuitable. We identify MLLMs as a novel tool for their open-ended semantic understanding capabilities. Yet, our datasets are four orders of magnitude too large for an MLLM to ingest as context. So we introduce a bottom-up procedure that decomposes the massive visual analysis problem into more tractable sub-problems. We carefully design MLLM-based solutions to each sub-problem. During experiments and ablation studies with our system, we find it significantly outperforms baselines and is able to discover interesting trends from images captured in large cities (e.g., "addition of outdoor dining,", "overpass was painted blue," etc.). See more results and interactive demos at https://boyangdeng.com/visual-chronicles.
Beyond the Frame: Generating 360° Panoramic Videos from Perspective Videos
Apr 10, 2025360{\deg} videos have emerged as a promising medium to represent our dynamic visual world. Compared to the "tunnel vision" of standard cameras, their borderless field of view offers a more complete perspective of our surroundings. While existing video models excel at producing standard videos, their ability to generate full panoramic videos remains elusive. In this paper, we investigate the task of video-to-360{\deg} generation: given a perspective video as input, our goal is to generate a full panoramic video that is consistent with the original video. Unlike conventional video generation tasks, the output's field of view is significantly larger, and the model is required to have a deep understanding of both the spatial layout of the scene and the dynamics of objects to maintain spatio-temporal consistency. To address these challenges, we first leverage the abundant 360{\deg} videos available online and develop a high-quality data filtering pipeline to curate pairwise training data. We then carefully design a series of geometry- and motion-aware operations to facilitate the learning process and improve the quality of 360{\deg} video generation. Experimental results demonstrate that our model can generate realistic and coherent 360{\deg} videos from in-the-wild perspective video. In addition, we showcase its potential applications, including video stabilization, camera viewpoint control, and interactive visual question answering.