 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Frame: Generating 360° Panoramic Videos from Perspective Videos
Apr 10, 2025360{\deg} videos have emerged as a promising medium to represent our dynamic visual world. Compared to the "tunnel vision" of standard cameras, their borderless field of view offers a more complete perspective of our surroundings. While existing video models excel at producing standard videos, their ability to generate full panoramic videos remains elusive. In this paper, we investigate the task of video-to-360{\deg} generation: given a perspective video as input, our goal is to generate a full panoramic video that is consistent with the original video. Unlike conventional video generation tasks, the output's field of view is significantly larger, and the model is required to have a deep understanding of both the spatial layout of the scene and the dynamics of objects to maintain spatio-temporal consistency. To address these challenges, we first leverage the abundant 360{\deg} videos available online and develop a high-quality data filtering pipeline to curate pairwise training data. We then carefully design a series of geometry- and motion-aware operations to facilitate the learning process and improve the quality of 360{\deg} video generation. Experimental results demonstrate that our model can generate realistic and coherent 360{\deg} videos from in-the-wild perspective video. In addition, we showcase its potential applications, including video stabilization, camera viewpoint control, and interactive visual question answering.
PhysPart: Physically Plausible Part Completion for Interactable Objects
Aug 25, 2024



Interactable objects are ubiquitous in our daily lives. Recent advances in 3D generative models make it possible to automate the modeling of these objects, benefiting a range of applications from 3D printing to the creation of robot simulation environments. However, while significant progress has been made in modeling 3D shapes and appearances, modeling object physics, particularly for interactable objects, remains challenging due to the physical constraints imposed by inter-part motions. In this paper, we tackle the problem of physically plausible part completion for interactable objects, aiming to generate 3D parts that not only fit precisely into the object but also allow smooth part motions. To this end, we propose a diffusion-based part generation model that utilizes geometric conditioning through classifier-free guidance and formulates physical constraints as a set of stability and mobility losses to guide the sampling process. Additionally, we demonstrate the generation of dependent parts, paving the way toward sequential part generation for objects with complex part-whole hierarchies. Experimentally, we introduce a new metric for measuring physical plausibility based on motion success rates. Our model outperforms existing baselines over shape and physical metrics, especially those that do not adequately model physical constraints. We also demonstrate our applications in 3D printing, robot manipulation, and sequential part generation, showing our strength in realistic tasks with the demand for high physical plausibility.
Unsupervised Discovery of Object-Centric Neural Fields
Feb 12, 2024
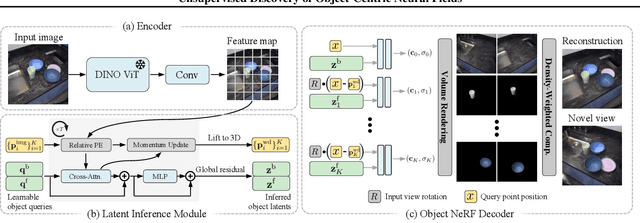

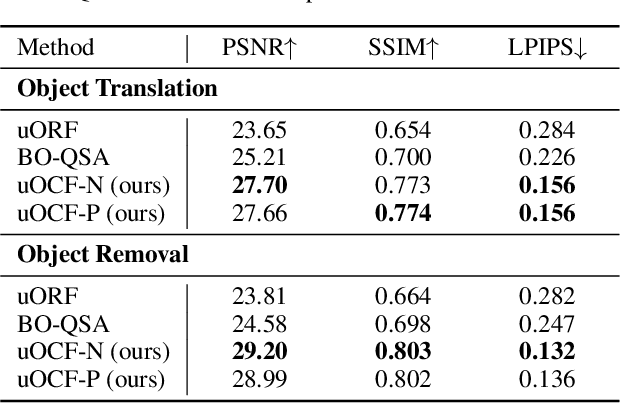
We study inferring 3D object-centric scene representations from a single image. While recent methods have shown potential in unsupervised 3D object discovery from simple synthetic images, they fail to generalize to real-world scenes with visually rich and diverse objects. This limitation stems from their object representations, which entangle objects' intrinsic attributes like shape and appearance with extrinsic, viewer-centric properties such as their 3D location. To address this bottleneck, we propose Unsupervised discovery of Object-Centric neural Fields (uOCF). uOCF focuses on learning the intrinsics of objects and models the extrinsics separately. Our approach significantly improves systematic generalization, thus enabling unsupervised learning of high-fidelity object-centric scene representations from sparse real-world images. To evaluate our approach, we collect three new datasets, including two real kitchen environments. Extensive experiments show that uOCF enables unsupervised discovery of visually rich objects from a single real image, allowing applications such as 3D object segmentation and scene manipulation. Notably, uOCF demonstrates zero-shot generalization to unseen objects from a single real image. Project page: https://red-fairy.github.io/uOCF/
Similarity Min-Max: Zero-Shot Day-Night Domain Adaptation
Jul 19, 2023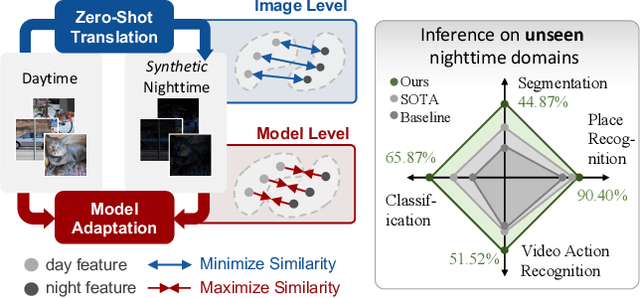
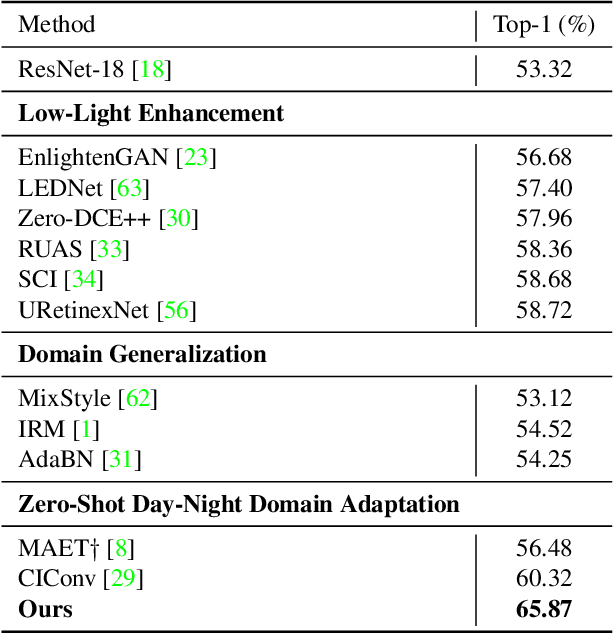
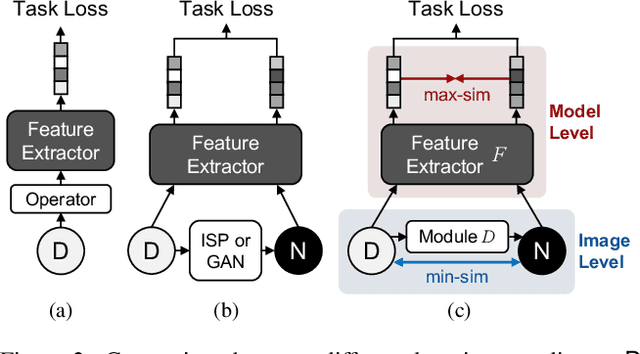
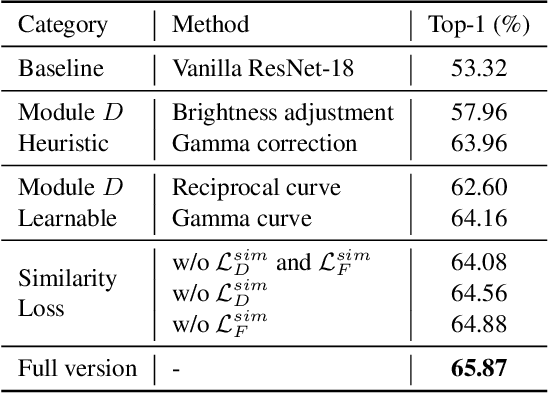
Low-light conditions not only hamper human visual experience but also degrade the model's performance on downstream vision tasks. While existing works make remarkable progress on day-night domain adaptation, they rely heavily on domain knowledge derived from the task-specific nighttime dataset. This paper challenges a more complicated scenario with border applicability, i.e., zero-shot day-night domain adaptation, which eliminates reliance on any nighttime data. Unlike prior zero-shot adaptation approaches emphasizing either image-level translation or model-level adaptation, we propose a similarity min-max paradigm that considers them under a unified framework. On the image level, we darken images towards minimum feature similarity to enlarge the domain gap. Then on the model level, we maximize the feature similarity between the darkened images and their normal-light counterparts for better model adaptation. To the best of our knowledge, this work represents the pioneering effort in jointly optimizing both aspects, resulting in a significant improvement of model generalizability. Extensive experiments demonstrate our method's effectiveness and broad applicability on various nighttime vision tasks, including classification, semantic segmentation, visual place recognition, and video action recognition. Code and pre-trained models are available at https://red-fairy.github.io/ZeroShotDayNightDA-Webpage/.
Rethinking the Effect of Data Augmentation in Adversarial Contrastive Learning
Mar 03, 2023Recent works have shown that self-supervised learning can achieve remarkable robustness when integrated with adversarial training (AT). However, the robustness gap between supervised AT (sup-AT) and self-supervised AT (self-AT) remains significant. Motivated by this observation, we revisit existing self-AT methods and discover an inherent dilemma that affects self-AT robustness: either strong or weak data augmentations are harmful to self-AT, and a medium strength is insufficient to bridge the gap. To resolve this dilemma, we propose a simple remedy named DYNACL (Dynamic Adversarial Contrastive Learning). In particular, we propose an augmentation schedule that gradually anneals from a strong augmentation to a weak one to benefit from both extreme cases. Besides, we adopt a fast post-processing stage for adapting it to downstream tasks. Through extensive experiments, we show that DYNACL can improve state-of-the-art self-AT robustness by 8.84% under Auto-Attack on the CIFAR-10 dataset, and can even outperform vanilla supervised adversarial training for the first time. Our code is available at \url{https://github.com/PKU-ML/DYNACL}.