 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising Hamiltonian Network for Physical Reasoning
Mar 10, 2025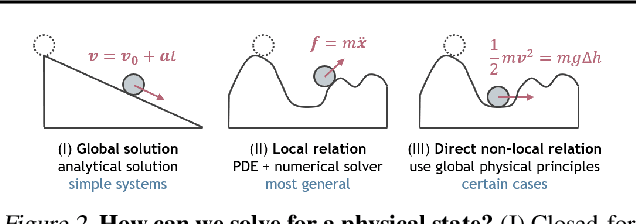
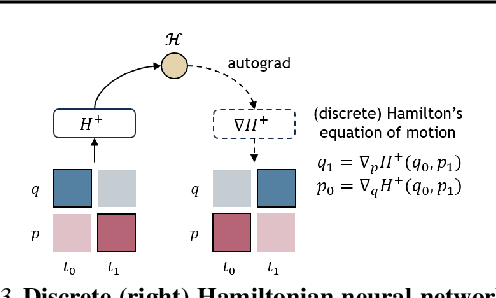
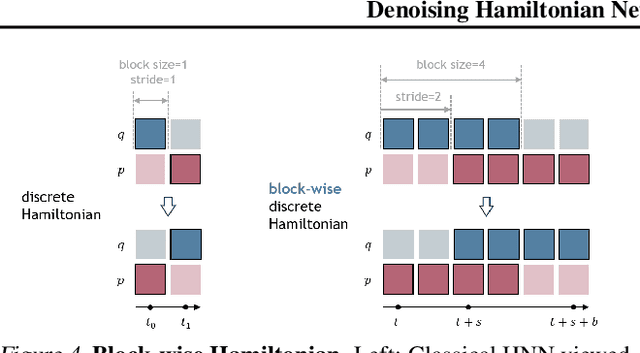
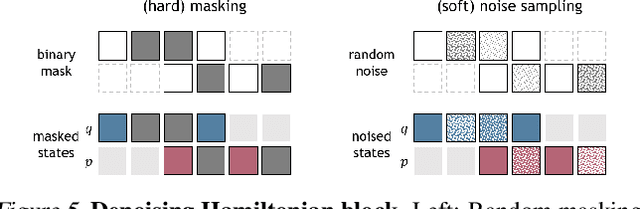
Machine learning frameworks for physical problems must capture and enforce physical constraints that preserve the structure of dynamical systems. Many existing approaches achieve this by integrating physical operators into neural networks. While these methods offer theoretical guarantees, they face two key limitations: (i) they primarily model local relations between adjacent time steps, overlooking longer-range or higher-level physical interactions, and (ii) they focus on forward simulation while neglecting broader physical reasoning tasks. We propose the Denoising Hamiltonian Network (DHN), a novel framework that generalizes Hamiltonian mechanics operators into more flexible neural operators. DHN captures non-local temporal relationships and mitigates numerical integration errors through a denoising mechanism. DHN also supports multi-system modeling with a global conditioning mechanism. We demonstrate its effectiveness and flexibility across three diverse physical reasoning tasks with distinct inputs and outputs.
Multiview Equivariance Improves 3D Correspondence Understanding with Minimal Feature Finetuning
Nov 29, 2024Vision foundation models, particularly the ViT family, have revolutionized image understanding by providing rich semantic features. However, despite their success in 2D comprehension, their abilities on grasping 3D spatial relationships are still unclear. In this work, we evaluate and enhance the 3D awareness of ViT-based models. We begin by systematically assessing their ability to learn 3D equivariant features, specifically examining the consistency of semantic embeddings across different viewpoints. Our findings indicate that improved 3D equivariance leads to better performance on various downstream tasks, including pose estimation, tracking, and semantic transfer. Building on this insight, we propose a simple yet effective finetuning strategy based on 3D correspondences, which significantly enhances the 3D correspondence understanding of existing vision models. Remarkably, even finetuning on a single object for just one iteration results in substantial performance gains. All code and resources will be made publicly available to support further advancements in 3D-aware vision models. Our code is available at https://github.com/qq456cvb/3DCorrEnhance.
Neural Attention Field: Emerging Point Relevance in 3D Scenes for One-Shot Dexterous Grasping
Oct 30, 2024



One-shot transfer of dexterous grasps to novel scenes with object and context variations has been a challenging problem. While distilled feature fields from large vision models have enabled semantic correspondences across 3D scenes, their features are point-based and restricted to object surfaces, limiting their capability of modeling complex semantic feature distributions for hand-object interactions. In this work, we propose the \textit{neural attention field} for representing semantic-aware dense feature fields in the 3D space by modeling inter-point relevance instead of individual point features. Core to it is a transformer decoder that computes the cross-attention between any 3D query point with all the scene points, and provides the query point feature with an attention-based aggregation. We further propose a self-supervised framework for training the transformer decoder from only a few 3D pointclouds without hand demonstrations. Post-training, the attention field can be applied to novel scenes for semantics-aware dexterous grasping from one-shot demonstration. Experiments show that our method provides better optimization landscapes by encouraging the end-effector to focus on task-relevant scene regions, resulting in significant improvements in success rates on real robots compared with the feature-field-based methods.
D3RoMa: Disparity Diffusion-based Depth Sensing for Material-Agnostic Robotic Manipulation
Sep 25, 2024



Depth sensing is an important problem for 3D vision-based robotics. Yet, a real-world active stereo or ToF depth camera often produces noisy and incomplete depth which bottlenecks robot performances. In this work, we propose D3RoMa, a learning-based depth estimation framework on stereo image pairs that predicts clean and accurate depth in diverse indoor scenes, even in the most challenging scenarios with translucent or specular surfaces where classical depth sensing completely fails. Key to our method is that we unify depth estimation and restoration into an image-to-image translation problem by predicting the disparity map with a denoising diffusion probabilistic model. At inference time, we further incorporated a left-right consistency constraint as classifier guidance to the diffusion process. Our framework combines recently advanced learning-based approaches and geometric constraints from traditional stereo vision. For model training, we create a large scene-level synthetic dataset with diverse transparent and specular objects to compensate for existing tabletop datasets. The trained model can be directly applied to real-world in-the-wild scenes and achieve state-of-the-art performance in multiple public depth estimation benchmarks. Further experiments in real environments show that accurate depth prediction significantly improves robotic manipulation in various scenarios.
PhysPart: Physically Plausible Part Completion for Interactable Objects
Aug 25, 2024



Interactable objects are ubiquitous in our daily lives. Recent advances in 3D generative models make it possible to automate the modeling of these objects, benefiting a range of applications from 3D printing to the creation of robot simulation environments. However, while significant progress has been made in modeling 3D shapes and appearances, modeling object physics, particularly for interactable objects, remains challenging due to the physical constraints imposed by inter-part motions. In this paper, we tackle the problem of physically plausible part completion for interactable objects, aiming to generate 3D parts that not only fit precisely into the object but also allow smooth part motions. To this end, we propose a diffusion-based part generation model that utilizes geometric conditioning through classifier-free guidance and formulates physical constraints as a set of stability and mobility losses to guide the sampling process. Additionally, we demonstrate the generation of dependent parts, paving the way toward sequential part generation for objects with complex part-whole hierarchies. Experimentally, we introduce a new metric for measuring physical plausibility based on motion success rates. Our model outperforms existing baselines over shape and physical metrics, especially those that do not adequately model physical constraints. We also demonstrate our applications in 3D printing, robot manipulation, and sequential part generation, showing our strength in realistic tasks with the demand for high physical plausibility.
RAM: Retrieval-Based Affordance Transfer for Generalizable Zero-Shot Robotic Manipulation
Jul 05, 2024



This work proposes a retrieve-and-transfer framework for zero-shot robotic manipulation, dubbed RAM, featuring generalizability across various objects, environments, and embodiments. Unlike existing approaches that learn manipulation from expensive in-domain demonstrations, RAM capitalizes on a retrieval-based affordance transfer paradigm to acquire versatile manipulation capabilities from abundant out-of-domain data. First, RAM extracts unified affordance at scale from diverse sources of demonstrations including robotic data, human-object interaction (HOI) data, and custom data to construct a comprehensive affordance memory. Then given a language instruction, RAM hierarchically retrieves the most similar demonstration from the affordance memory and transfers such out-of-domain 2D affordance to in-domain 3D executable affordance in a zero-shot and embodiment-agnostic manner. Extensive simulation and real-world evaluations demonstrate that our RAM consistently outperforms existing works in diverse daily tasks. Additionally, RAM shows significant potential for downstream applications such as automatic and efficient data collection, one-shot visual imitation, and LLM/VLM-integrated long-horizon manipulation. For more details, please check our website at https://yxkryptonite.github.io/RAM/.
EquiBot: SIM(3)-Equivariant Diffusion Policy for Generalizable and Data Efficient Learning
Jul 01, 2024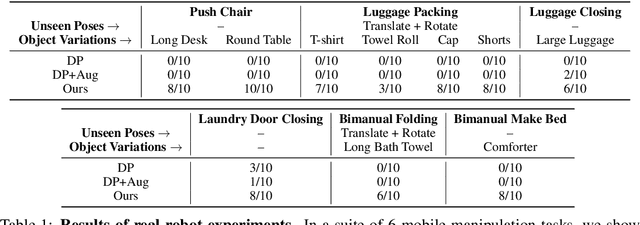
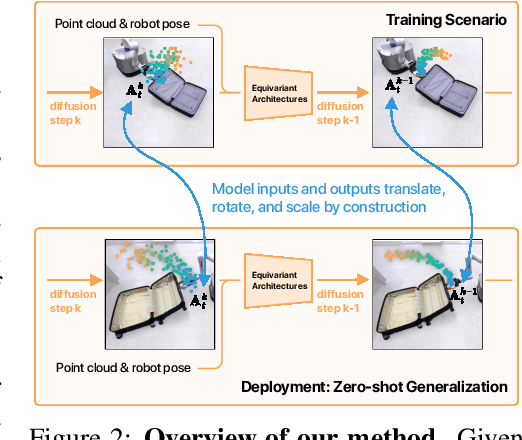


Building effective imitation learning methods that enable robots to learn from limited data and still generalize across diverse real-world environments is a long-standing problem in robot learning. We propose EquiBot, a robust, data-efficient, and generalizable approach for robot manipulation task learning. Our approach combines SIM(3)-equivariant neural network architectures with diffusion models. This ensures that our learned policies are invariant to changes in scale, rotation, and translation, enhancing their applicability to unseen environments while retaining the benefits of diffusion-based policy learning such as multi-modality and robustness. We show in a suite of 6 simulation tasks that our proposed method reduces the data requirements and improves generalization to novel scenarios. In the real world, we show with in total 10 variations of 6 mobile manipulation tasks that our method can easily generalize to novel objects and scenes after learning from just 5 minutes of human demonstrations in each task.
Zero-Shot Image Feature Consensus with Deep Functional Maps
Mar 18, 2024



Correspondences emerge from large-scale vision models trained for generative and discriminative tasks. This has been revealed and benchmarked by computing correspondence maps between pairs of images, using nearest neighbors on the feature grids. Existing work has attempted to improve the quality of these correspondence maps by carefully mixing features from different sources, such as by combining the features of different layers or networks. We point out that a better correspondence strategy is available, which directly imposes structure on the correspondence field: the functional map. Wielding this simple mathematical tool, we lift the correspondence problem from the pixel space to the function space and directly optimize for mappings that are globally coherent. We demonstrate that our technique yields correspondences that are not only smoother but also more accurate, with the possibility of better reflecting the knowledge embedded in the large-scale vision models that we are studying. Our approach sets a new state-of-the-art on various dense correspondence tasks. We also demonstrate our effectiveness in keypoint correspondence and affordance map transfer.
SAGE: Bridging Semantic and Actionable Parts for GEneralizable Articulated-Object Manipulation under Language Instructions
Dec 03, 2023Generalizable manipulation of articulated objects remains a challenging problem in many real-world scenarios, given the diverse object structures, functionalities, and goals. In these tasks, both semantic interpretations and physical plausibilities are crucial for a policy to succeed. To address this problem, we propose SAGE, a novel framework that bridges the understanding of semantic and actionable parts of articulated objects to achieve generalizable manipulation under language instructions. Given a manipulation goal specified by natural language, an instruction interpreter with Large Language Models (LLMs) first translates them into programmatic actions on the object's semantic parts. This process also involves a scene context parser for understanding the visual inputs, which is designed to generate scene descriptions with both rich information and accurate interaction-related facts by joining the forces of generalist Visual-Language Models (VLMs) and domain-specialist part perception models. To further convert the action programs into executable policies, a part grounding module then maps the object semantic parts suggested by the instruction interpreter into so-called Generalizable Actionable Parts (GAParts). Finally, an interactive feedback module is incorporated to respond to failures, which greatly increases the robustness of the overall framework. Experiments both in simulation environments and on real robots show that our framework can handle a large variety of articulated objects with diverse language-instructed goals. We also provide a new benchmark for language-guided articulated-object manipulation in realistic scenarios.
Rethinking Directional Integration in Neural Radiance Fields
Nov 28, 2023



Recent works use the Neural radiance field (NeRF) to perform multi-view 3D reconstruction, providing a significant leap in rendering photorealistic scenes. However, despite its efficacy, NeRF exhibits limited capability of learning view-dependent effects compared to light field rendering or image-based view synthesis. To that end, we introduce a modification to the NeRF rendering equation which is as simple as a few lines of code change for any NeRF variations, while greatly improving the rendering quality of view-dependent effects. By swapping the integration operator and the direction decoder network, we only integrate the positional features along the ray and move the directional terms out of the integration, resulting in a disentanglement of the view-dependent and independent components. The modified equation is equivalent to the classical volumetric rendering in ideal cases on object surfaces with Dirac densities. Furthermore, we prove that with the errors caused by network approximation and numerical integration, our rendering equation exhibits better convergence properties with lower error accumulations compared to the classical NeRF. We also show that the modified equation can be interpreted as light field rendering with learned ray embeddings. Experiments on different NeRF variations show consistent improvements in the quality of view-dependent effects with our simple modification.