 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSonicMoE: Accelerating MoE with IO and Tile-aware Optimizations
Dec 16, 2025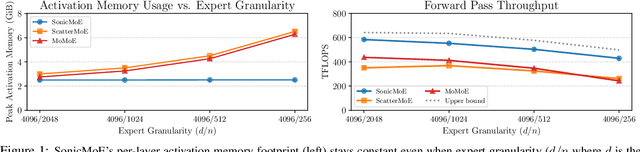
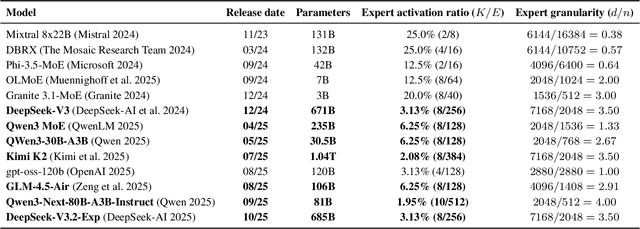
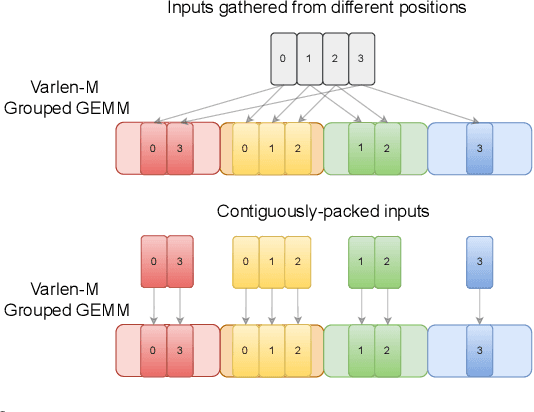
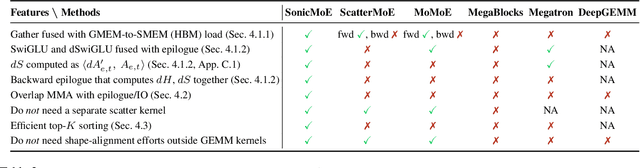
Mixture of Experts (MoE) models have emerged as the de facto architecture for scaling up language models without significantly increasing the computational cost. Recent MoE models demonstrate a clear trend towards high expert granularity (smaller expert intermediate dimension) and higher sparsity (constant number of activated experts with higher number of total experts), which improve model quality per FLOP. However, fine-grained MoEs suffer from increased activation memory footprint and reduced hardware efficiency due to higher IO costs, while sparser MoEs suffer from wasted computations due to padding in Grouped GEMM kernels. In response, we propose a memory-efficient algorithm to compute the forward and backward passes of MoEs with minimal activation caching for the backward pass. We also design GPU kernels that overlap memory IO with computation benefiting all MoE architectures. Finally, we propose a novel "token rounding" method that minimizes the wasted compute due to padding in Grouped GEMM kernels. As a result, our method SonicMoE reduces activation memory by 45% and achieves a 1.86x compute throughput improvement on Hopper GPUs compared to ScatterMoE's BF16 MoE kernel for a fine-grained 7B MoE. Concretely, SonicMoE on 64 H100s achieves a training throughput of 213 billion tokens per day comparable to ScatterMoE's 225 billion tokens per day on 96 H100s for a 7B MoE model training with FSDP-2 using the lm-engine codebase. Under high MoE sparsity settings, our tile-aware token rounding algorithm yields an additional 1.16x speedup on kernel execution time compared to vanilla top-$K$ routing while maintaining similar downstream performance. We open-source all our kernels to enable faster MoE model training.
VidTok: A Versatile and Open-Source Video Tokenizer
Dec 17, 2024



Encoding video content into compact latent tokens has become a fundamental step in video generation and understanding, driven by the need to address the inherent redundancy in pixel-level representations. Consequently, there is a growing demand for high-performance, open-source video tokenizers as video-centric research gains prominence. We introduce VidTok, a versatile video tokenizer that delivers state-of-the-art performance in both continuous and discrete tokenizations. VidTok incorporates several key advancements over existing approaches: 1) model architecture such as convolutional layers and up/downsampling modules; 2) to address the training instability and codebook collapse commonly associated with conventional Vector Quantization (VQ), we integrate Finite Scalar Quantization (FSQ) into discrete video tokenization; 3) improved training strategies, including a two-stage training process and the use of reduced frame rates. By integrating these advancements, VidTok achieves substantial improvements over existing methods, demonstrating superior performance across multiple metrics, including PSNR, SSIM, LPIPS, and FVD, under standardized evaluation settings.
Zero-Shot Image Feature Consensus with Deep Functional Maps
Mar 18, 2024



Correspondences emerge from large-scale vision models trained for generative and discriminative tasks. This has been revealed and benchmarked by computing correspondence maps between pairs of images, using nearest neighbors on the feature grids. Existing work has attempted to improve the quality of these correspondence maps by carefully mixing features from different sources, such as by combining the features of different layers or networks. We point out that a better correspondence strategy is available, which directly imposes structure on the correspondence field: the functional map. Wielding this simple mathematical tool, we lift the correspondence problem from the pixel space to the function space and directly optimize for mappings that are globally coherent. We demonstrate that our technique yields correspondences that are not only smoother but also more accurate, with the possibility of better reflecting the knowledge embedded in the large-scale vision models that we are studying. Our approach sets a new state-of-the-art on various dense correspondence tasks. We also demonstrate our effectiveness in keypoint correspondence and affordance map transfer.