 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVidTok: A Versatile and Open-Source Video Tokenizer
Dec 17, 2024



Encoding video content into compact latent tokens has become a fundamental step in video generation and understanding, driven by the need to address the inherent redundancy in pixel-level representations. Consequently, there is a growing demand for high-performance, open-source video tokenizers as video-centric research gains prominence. We introduce VidTok, a versatile video tokenizer that delivers state-of-the-art performance in both continuous and discrete tokenizations. VidTok incorporates several key advancements over existing approaches: 1) model architecture such as convolutional layers and up/downsampling modules; 2) to address the training instability and codebook collapse commonly associated with conventional Vector Quantization (VQ), we integrate Finite Scalar Quantization (FSQ) into discrete video tokenization; 3) improved training strategies, including a two-stage training process and the use of reduced frame rates. By integrating these advancements, VidTok achieves substantial improvements over existing methods, demonstrating superior performance across multiple metrics, including PSNR, SSIM, LPIPS, and FVD, under standardized evaluation settings.
Rate-aware Compression for NeRF-based Volumetric Video
Nov 08, 2024



The neural radiance fields (NeRF) have advanced the development of 3D volumetric video technology, but the large data volumes they involve pose significant challenges for storage and transmission. To address these problems, the existing solutions typically compress these NeRF representations after the training stage, leading to a separation between representation training and compression. In this paper, we try to directly learn a compact NeRF representation for volumetric video in the training stage based on the proposed rate-aware compression framework. Specifically, for volumetric video, we use a simple yet effective modeling strategy to reduce temporal redundancy for the NeRF representation. Then, during the training phase, an implicit entropy model is utilized to estimate the bitrate of the NeRF representation. This entropy model is then encoded into the bitstream to assist in the decoding of the NeRF representation. This approach enables precise bitrate estimation, thereby leading to a compact NeRF representation. Furthermore, we propose an adaptive quantization strategy and learn the optimal quantization step for the NeRF representations. Finally, the NeRF representation can be optimized by using the rate-distortion trade-off. Our proposed compression framework can be used for different representations and experimental results demonstrate that our approach significantly reduces the storage size with marginal distortion and achieves state-of-the-art rate-distortion performance for volumetric video on the HumanRF and ReRF datasets. Compared to the previous state-of-the-art method TeTriRF, we achieved an approximately -80% BD-rate on the HumanRF dataset and -60% BD-rate on the ReRF dataset.
Compositional 3D-aware Video Generation with LLM Director
Aug 31, 2024



Significant progress has been made in text-to-video generation through the use of powerful generative models and large-scale internet data. However, substantial challenges remain in precisely controlling individual concepts within the generated video, such as the motion and appearance of specific characters and the movement of viewpoints. In this work, we propose a novel paradigm that generates each concept in 3D representation separately and then composes them with priors from Large Language Models (LLM) and 2D diffusion models. Specifically, given an input textual prompt, our scheme consists of three stages: 1) We leverage LLM as the director to first decompose the complex query into several sub-prompts that indicate individual concepts within the video~(\textit{e.g.}, scene, objects, motions), then we let LLM to invoke pre-trained expert models to obtain corresponding 3D representations of concepts. 2) To compose these representations, we prompt multi-modal LLM to produce coarse guidance on the scales and coordinates of trajectories for the objects. 3) To make the generated frames adhere to natural image distribution, we further leverage 2D diffusion priors and use Score Distillation Sampling to refine the composition. Extensive experiments demonstrate that our method can generate high-fidelity videos from text with diverse motion and flexible control over each concept. Project page: \url{https://aka.ms/c3v}.
Efficient Dynamic-NeRF Based Volumetric Video Coding with Rate Distortion Optimization
Feb 02, 2024



Volumetric videos, benefiting from immersive 3D realism and interactivity, hold vast potential for various applications, while the tremendous data volume poses significant challenges for compression. Recently, NeRF has demonstrated remarkable potential in volumetric video compression thanks to its simple representation and powerful 3D modeling capabilities, where a notable work is ReRF. However, ReRF separates the modeling from compression process, resulting in suboptimal compression efficiency. In contrast, in this paper, we propose a volumetric video compression method based on dynamic NeRF in a more compact manner. Specifically, we decompose the NeRF representation into the coefficient fields and the basis fields, incrementally updating the basis fields in the temporal domain to achieve dynamic modeling. Additionally, we perform end-to-end joint optimization on the modeling and compression process to further improve the compression efficiency. Extensive experiments demonstrate that our method achieves higher compression efficiency compared to ReRF on various datasets.
Memories are One-to-Many Mapping Alleviators in Talking Face Generation
Dec 12, 2022
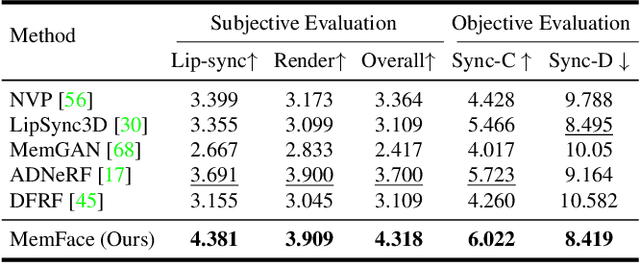
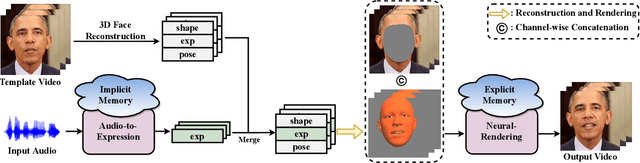
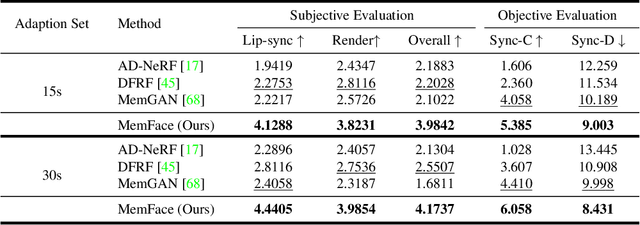
Talking face generation aims at generating photo-realistic video portraits of a target person driven by input audio. Due to its nature of one-to-many mapping from the input audio to the output video (e.g., one speech content may have multiple feasible visual appearances), learning a deterministic mapping like previous works brings ambiguity during training, and thus causes inferior visual results. Although this one-to-many mapping could be alleviated in part by a two-stage framework (i.e., an audio-to-expression model followed by a neural-rendering model), it is still insufficient since the prediction is produced without enough information (e.g., emotions, wrinkles, etc.). In this paper, we propose MemFace to complement the missing information with an implicit memory and an explicit memory that follow the sense of the two stages respectively. More specifically, the implicit memory is employed in the audio-to-expression model to capture high-level semantics in the audio-expression shared space, while the explicit memory is employed in the neural-rendering model to help synthesize pixel-level details. Our experimental results show that our proposed MemFace surpasses all the state-of-the-art results across multiple scenarios consistently and significantly.
Generative Compression for Face Video: A Hybrid Scheme
Apr 26, 2022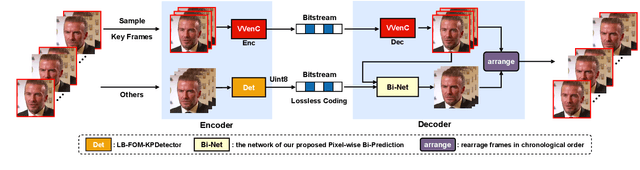

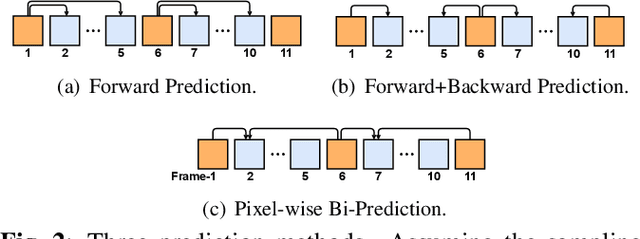
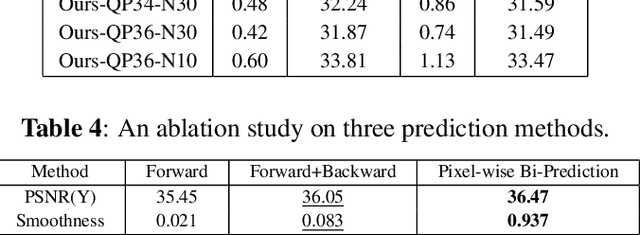
As the latest video coding standard, versatile video coding (VVC) has shown its ability in retaining pixel quality. To excavate more compression potential for video conference scenarios under ultra-low bitrate, this paper proposes a bitrate adjustable hybrid compression scheme for face video. This hybrid scheme combines the pixel-level precise recovery capability of traditional coding with the generation capability of deep learning based on abridged information, where Pixel wise Bi-Prediction, Low-Bitrate-FOM and Lossless Keypoint Encoder collaborate to achieve PSNR up to 36.23 dB at a low bitrate of 1.47 KB/s. Without introducing any additional bitrate, our method has a clear advantage over VVC under a completely fair comparative experiment, which proves the effectiveness of our proposed scheme. Moreover, our scheme can adapt to any existing encoder / configuration to deal with different encoding requirements, and the bitrate can be dynamically adjusted according to the network condition.