 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAR4D: Autoregressive 4D Generation from Monocular Videos
Jan 03, 2025



Recent advancements in generative models have ignited substantial interest in dynamic 3D content creation (\ie, 4D generation). Existing approaches primarily rely on Score Distillation Sampling (SDS) to infer novel-view videos, typically leading to issues such as limited diversity, spatial-temporal inconsistency and poor prompt alignment, due to the inherent randomness of SDS. To tackle these problems, we propose AR4D, a novel paradigm for SDS-free 4D generation. Specifically, our paradigm consists of three stages. To begin with, for a monocular video that is either generated or captured, we first utilize pre-trained expert models to create a 3D representation of the first frame, which is further fine-tuned to serve as the canonical space. Subsequently, motivated by the fact that videos happen naturally in an autoregressive manner, we propose to generate each frame's 3D representation based on its previous frame's representation, as this autoregressive generation manner can facilitate more accurate geometry and motion estimation. Meanwhile, to prevent overfitting during this process, we introduce a progressive view sampling strategy, utilizing priors from pre-trained large-scale 3D reconstruction models. To avoid appearance drift introduced by autoregressive generation, we further incorporate a refinement stage based on a global deformation field and the geometry of each frame's 3D representation. Extensive experiments have demonstrated that AR4D can achieve state-of-the-art 4D generation without SDS, delivering greater diversity, improved spatial-temporal consistency, and better alignment with input prompts.
GSemSplat: Generalizable Semantic 3D Gaussian Splatting from Uncalibrated Image Pairs
Dec 22, 2024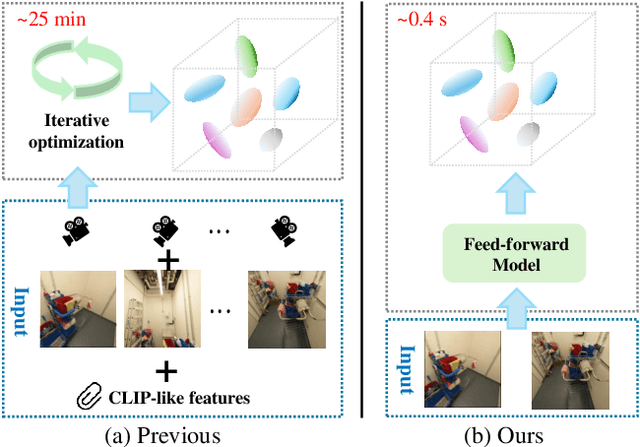



Modeling and understanding the 3D world is crucial for various applications, from augmented reality to robotic navigation. Recent advancements based on 3D Gaussian Splatting have integrated semantic information from multi-view images into Gaussian primitives. However, these methods typically require costly per-scene optimization from dense calibrated images, limiting their practicality. In this paper, we consider the new task of generalizable 3D semantic field modeling from sparse, uncalibrated image pairs. Building upon the Splatt3R architecture, we introduce GSemSplat, a framework that learns open-vocabulary semantic representations linked to 3D Gaussians without the need for per-scene optimization, dense image collections or calibration. To ensure effective and reliable learning of semantic features in 3D space, we employ a dual-feature approach that leverages both region-specific and context-aware semantic features as supervision in the 2D space. This allows us to capitalize on their complementary strengths. Experimental results on the ScanNet++ dataset demonstrate the effectiveness and superiority of our approach compared to the traditional scene-specific method. We hope our work will inspire more research into generalizable 3D understanding.
TIV-Diffusion: Towards Object-Centric Movement for Text-driven Image to Video Generation
Dec 13, 2024



Text-driven Image to Video Generation (TI2V) aims to generate controllable video given the first frame and corresponding textual description. The primary challenges of this task lie in two parts: (i) how to identify the target objects and ensure the consistency between the movement trajectory and the textual description. (ii) how to improve the subjective quality of generated videos. To tackle the above challenges, we propose a new diffusion-based TI2V framework, termed TIV-Diffusion, via object-centric textual-visual alignment, intending to achieve precise control and high-quality video generation based on textual-described motion for different objects. Concretely, we enable our TIV-Diffuion model to perceive the textual-described objects and their motion trajectory by incorporating the fused textual and visual knowledge through scale-offset modulation. Moreover, to mitigate the problems of object disappearance and misaligned objects and motion, we introduce an object-centric textual-visual alignment module, which reduces the risk of misaligned objects/motion by decoupling the objects in the reference image and aligning textual features with each object individually. Based on the above innovations, our TIV-Diffusion achieves state-of-the-art high-quality video generation compared with existing TI2V methods.
Compositional 3D-aware Video Generation with LLM Director
Aug 31, 2024



Significant progress has been made in text-to-video generation through the use of powerful generative models and large-scale internet data. However, substantial challenges remain in precisely controlling individual concepts within the generated video, such as the motion and appearance of specific characters and the movement of viewpoints. In this work, we propose a novel paradigm that generates each concept in 3D representation separately and then composes them with priors from Large Language Models (LLM) and 2D diffusion models. Specifically, given an input textual prompt, our scheme consists of three stages: 1) We leverage LLM as the director to first decompose the complex query into several sub-prompts that indicate individual concepts within the video~(\textit{e.g.}, scene, objects, motions), then we let LLM to invoke pre-trained expert models to obtain corresponding 3D representations of concepts. 2) To compose these representations, we prompt multi-modal LLM to produce coarse guidance on the scales and coordinates of trajectories for the objects. 3) To make the generated frames adhere to natural image distribution, we further leverage 2D diffusion priors and use Score Distillation Sampling to refine the composition. Extensive experiments demonstrate that our method can generate high-fidelity videos from text with diverse motion and flexible control over each concept. Project page: \url{https://aka.ms/c3v}.
UCIP: A Universal Framework for Compressed Image Super-Resolution using Dynamic Prompt
Jul 18, 2024



Compressed Image Super-resolution (CSR) aims to simultaneously super-resolve the compressed images and tackle the challenging hybrid distortions caused by compression. However, existing works on CSR usually focuses on a single compression codec, i.e., JPEG, ignoring the diverse traditional or learning-based codecs in the practical application, e.g., HEVC, VVC, HIFIC, etc. In this work, we propose the first universal CSR framework, dubbed UCIP, with dynamic prompt learning, intending to jointly support the CSR distortions of any compression codecs/modes. Particularly, an efficient dynamic prompt strategy is proposed to mine the content/spatial-aware task-adaptive contextual information for the universal CSR task, using only a small amount of prompts with spatial size 1x1. To simplify contextual information mining, we introduce the novel MLP-like framework backbone for our UCIP by adapting the Active Token Mixer (ATM) to CSR tasks for the first time, where the global information modeling is only taken in horizontal and vertical directions with offset prediction. We also build an all-in-one benchmark dataset for the CSR task by collecting the datasets with the popular 6 diverse traditional and learning-based codecs, including JPEG, HEVC, VVC, HIFIC, etc., resulting in 23 common degradations. Extensive experiments have shown the consistent and excellent performance of our UCIP on universal CSR tasks. The project can be found in https://lixinustc.github.io/UCIP.github.io
GaussianSR: 3D Gaussian Super-Resolution with 2D Diffusion Priors
Jun 14, 2024



Achieving high-resolution novel view synthesis (HRNVS) from low-resolution input views is a challenging task due to the lack of high-resolution data. Previous methods optimize high-resolution Neural Radiance Field (NeRF) from low-resolution input views but suffer from slow rendering speed. In this work, we base our method on 3D Gaussian Splatting (3DGS) due to its capability of producing high-quality images at a faster rendering speed. To alleviate the shortage of data for higher-resolution synthesis, we propose to leverage off-the-shelf 2D diffusion priors by distilling the 2D knowledge into 3D with Score Distillation Sampling (SDS). Nevertheless, applying SDS directly to Gaussian-based 3D super-resolution leads to undesirable and redundant 3D Gaussian primitives, due to the randomness brought by generative priors. To mitigate this issue, we introduce two simple yet effective techniques to reduce stochastic disturbances introduced by SDS. Specifically, we 1) shrink the range of diffusion timestep in SDS with an annealing strategy; 2) randomly discard redundant Gaussian primitives during densification. Extensive experiments have demonstrated that our proposed GaussainSR can attain high-quality results for HRNVS with only low-resolution inputs on both synthetic and real-world datasets. Project page: https://chchnii.github.io/GaussianSR/
Is Vanilla MLP in Neural Radiance Field Enough for Few-shot View Synthesis?
Mar 10, 2024



Neural Radiance Field (NeRF) has achieved superior performance for novel view synthesis by modeling the scene with a Multi-Layer Perception (MLP) and a volume rendering procedure, however, when fewer known views are given (i.e., few-shot view synthesis), the model is prone to overfit the given views. To handle this issue, previous efforts have been made towards leveraging learned priors or introducing additional regularizations. In contrast, in this paper, we for the first time provide an orthogonal method from the perspective of network structure. Given the observation that trivially reducing the number of model parameters alleviates the overfitting issue, but at the cost of missing details, we propose the multi-input MLP (mi-MLP) that incorporates the inputs (i.e., location and viewing direction) of the vanilla MLP into each layer to prevent the overfitting issue without harming detailed synthesis. To further reduce the artifacts, we propose to model colors and volume density separately and present two regularization terms. Extensive experiments on multiple datasets demonstrate that: 1) although the proposed mi-MLP is easy to implement, it is surprisingly effective as it boosts the PSNR of the baseline from $14.73$ to $24.23$. 2) the overall framework achieves state-of-the-art results on a wide range of benchmarks. We will release the code upon publication.
SeD: Semantic-Aware Discriminator for Image Super-Resolution
Feb 29, 2024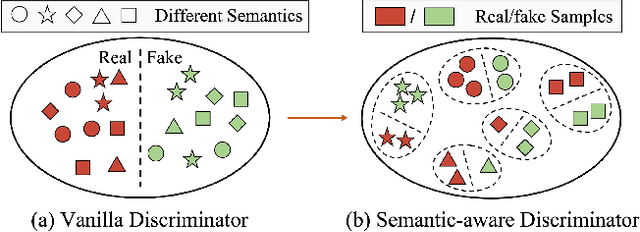
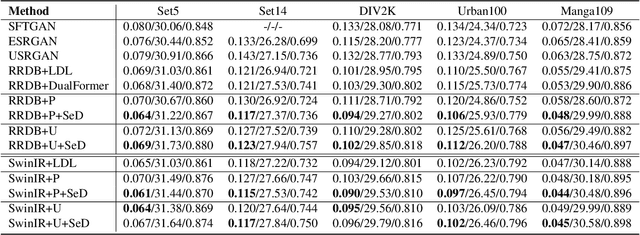
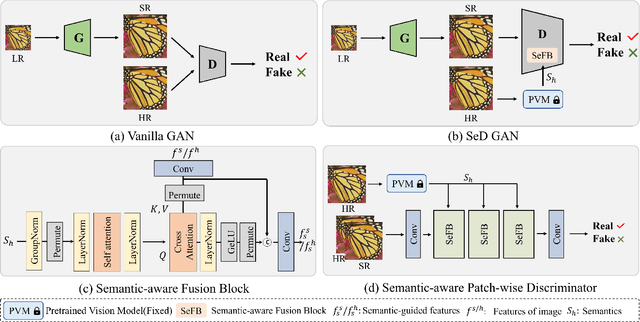
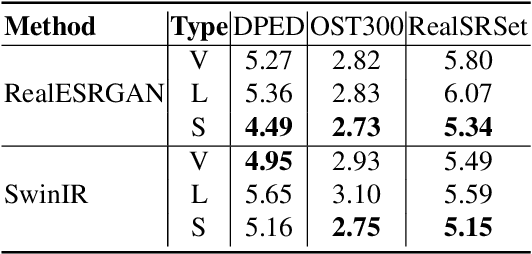
Generative Adversarial Networks (GANs) have been widely used to recover vivid textures in image super-resolution (SR) tasks. In particular, one discriminator is utilized to enable the SR network to learn the distribution of real-world high-quality images in an adversarial training manner. However, the distribution learning is overly coarse-grained, which is susceptible to virtual textures and causes counter-intuitive generation results. To mitigate this, we propose the simple and effective Semantic-aware Discriminator (denoted as SeD), which encourages the SR network to learn the fine-grained distributions by introducing the semantics of images as a condition. Concretely, we aim to excavate the semantics of images from a well-trained semantic extractor. Under different semantics, the discriminator is able to distinguish the real-fake images individually and adaptively, which guides the SR network to learn the more fine-grained semantic-aware textures. To obtain accurate and abundant semantics, we take full advantage of recently popular pretrained vision models (PVMs) with extensive datasets, and then incorporate its semantic features into the discriminator through a well-designed spatial cross-attention module. In this way, our proposed semantic-aware discriminator empowered the SR network to produce more photo-realistic and pleasing images. Extensive experiments on two typical tasks, i.e., SR and Real SR have demonstrated the effectiveness of our proposed methods.
CMC: Few-shot Novel View Synthesis via Cross-view Multiplane Consistency
Feb 26, 2024



Neural Radiance Field (NeRF) has shown impressive results in novel view synthesis, particularly in Virtual Reality (VR) and Augmented Reality (AR), thanks to its ability to represent scenes continuously. However, when just a few input view images are available, NeRF tends to overfit the given views and thus make the estimated depths of pixels share almost the same value. Unlike previous methods that conduct regularization by introducing complex priors or additional supervisions, we propose a simple yet effective method that explicitly builds depth-aware consistency across input views to tackle this challenge. Our key insight is that by forcing the same spatial points to be sampled repeatedly in different input views, we are able to strengthen the interactions between views and therefore alleviate the overfitting problem. To achieve this, we build the neural networks on layered representations (\textit{i.e.}, multiplane images), and the sampling point can thus be resampled on multiple discrete planes. Furthermore, to regularize the unseen target views, we constrain the rendered colors and depths from different input views to be the same. Although simple, extensive experiments demonstrate that our proposed method can achieve better synthesis quality over state-of-the-art methods.
MiNL: Micro-images based Neural Representation for Light Fields
Sep 17, 2022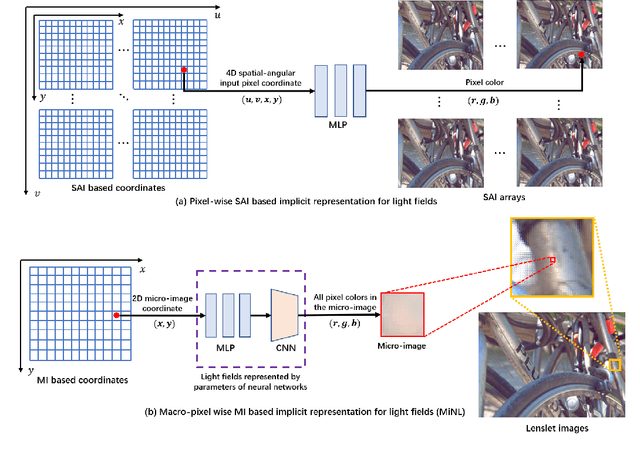
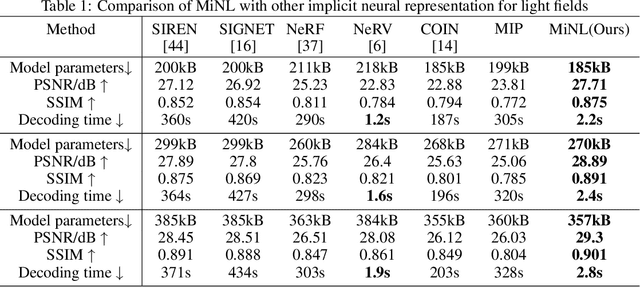
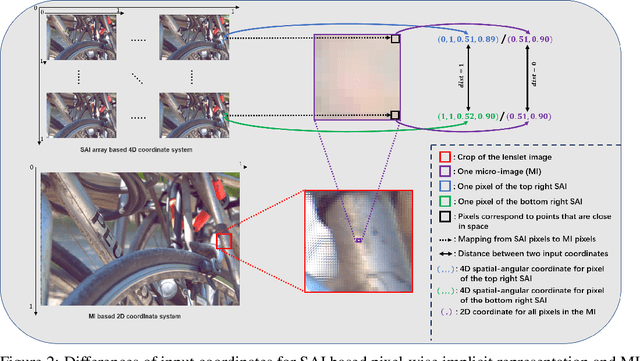
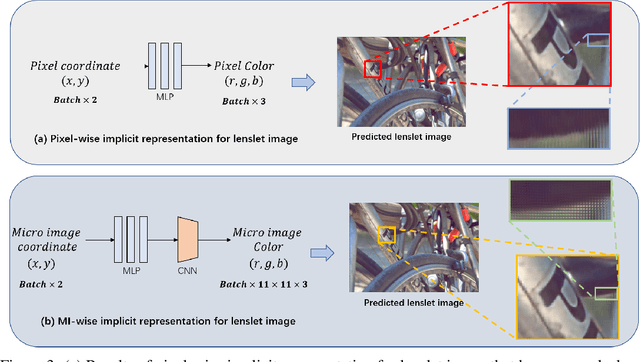
Traditional representations for light fields can be separated into two types: explicit representation and implicit representation. Unlike explicit representation that represents light fields as Sub-Aperture Images (SAIs) based arrays or Micro-Images (MIs) based lenslet images, implicit representation treats light fields as neural networks, which is inherently a continuous representation in contrast to discrete explicit representation. However, at present almost all the implicit representations for light fields utilize SAIs to train an MLP to learn a pixel-wise mapping from 4D spatial-angular coordinate to pixel colors, which is neither compact nor of low complexity. Instead, in this paper we propose MiNL, a novel MI-wise implicit neural representation for light fields that train an MLP + CNN to learn a mapping from 2D MI coordinates to MI colors. Given the micro-image's coordinate, MiNL outputs the corresponding micro-image's RGB values. Light field encoding in MiNL is just training a neural network to regress the micro-images and the decoding process is a simple feedforward operation. Compared with common pixel-wise implicit representation, MiNL is more compact and efficient that has faster decoding speed (\textbf{$\times$80$\sim$180} speed-up) as well as better visual quality (\textbf{1$\sim$4dB} PSNR improvement on average).