 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeD: Semantic-Aware Discriminator for Image Super-Resolution
Paper and Code
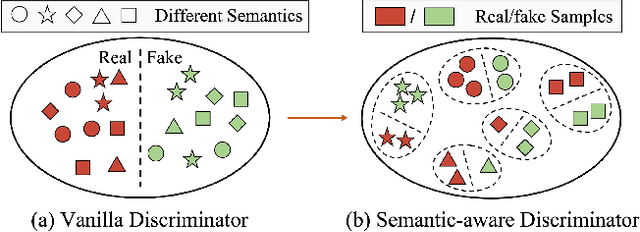
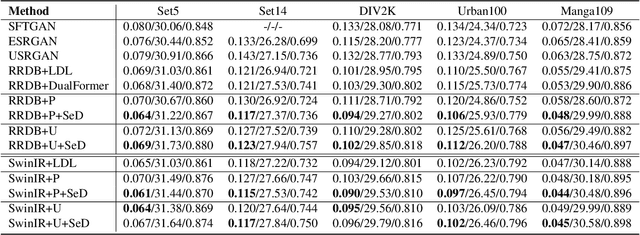
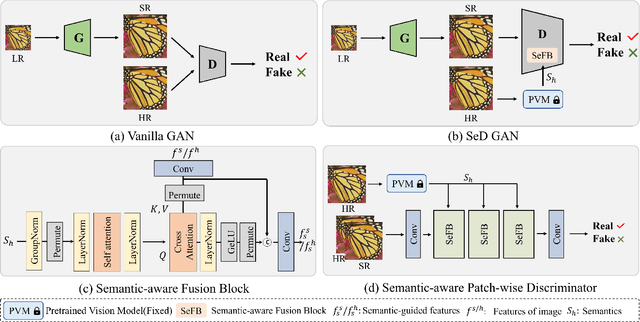
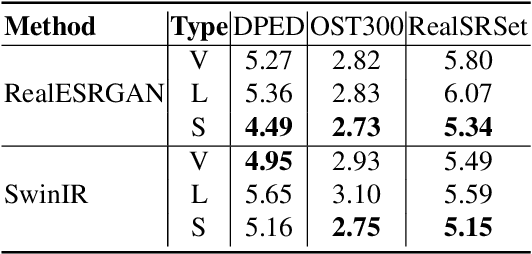
Generative Adversarial Networks (GANs) have been widely used to recover vivid textures in image super-resolution (SR) tasks. In particular, one discriminator is utilized to enable the SR network to learn the distribution of real-world high-quality images in an adversarial training manner. However, the distribution learning is overly coarse-grained, which is susceptible to virtual textures and causes counter-intuitive generation results. To mitigate this, we propose the simple and effective Semantic-aware Discriminator (denoted as SeD), which encourages the SR network to learn the fine-grained distributions by introducing the semantics of images as a condition. Concretely, we aim to excavate the semantics of images from a well-trained semantic extractor. Under different semantics, the discriminator is able to distinguish the real-fake images individually and adaptively, which guides the SR network to learn the more fine-grained semantic-aware textures. To obtain accurate and abundant semantics, we take full advantage of recently popular pretrained vision models (PVMs) with extensive datasets, and then incorporate its semantic features into the discriminator through a well-designed spatial cross-attention module. In this way, our proposed semantic-aware discriminator empowered the SR network to produce more photo-realistic and pleasing images. Extensive experiments on two typical tasks, i.e., SR and Real SR have demonstrated the effectiveness of our proposed methods.