 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavGSim: High-Fidelity Gaussian Splatting Simulator for Large-Scale Navigation
Mar 16, 2026Simulating realistic environments for robots is widely recognized as a critical challenge in robot learning, particularly in terms of rendering and physical simulation. This challenge becomes even more pronounced in navigation tasks, where trajectories often extend across multiple rooms or entire floors. In this work, we present NavGSim, a Gaussian Splatting-based simulator designed to generate high-fidelity, large-scale navigation environments. Built upon a hierarchical 3D Gaussian Splatting framework, NavGSim enables photorealistic rendering in expansive scenes spanning hundreds of square meters. To simulate navigation collisions, we introduce a Gaussian Splatting-based slice technique that directly extracts navigable areas from reconstructed Gaussians. Additionally, for ease of use, we provide comprehensive NavGSim APIs supporting multi-GPU development, including tools for custom scene reconstruction, robot configuration, policy training, and evaluation. To evaluate NavGSim's effectiveness, we train a Vision-Language-Action (VLA) model using trajectories collected from NavGSim and assess its performance in both simulated and real-world environments. Our results demonstrate that NavGSim significantly enhances the VLA model's scene understanding, enabling the policy to handle diverse navigation queries effectively.
SPAN-Nav: Generalized Spatial Awareness for Versatile Vision-Language Navigation
Mar 10, 2026Recent embodied navigation approaches leveraging Vision-Language Models (VLMs) demonstrate strong generalization in versatile Vision-Language Navigation (VLN). However, reliable path planning in complex environments remains challenging due to insufficient spatial awareness. In this work, we introduce SPAN-Nav, an end-to-end foundation model designed to infuse embodied navigation with universal 3D spatial awareness using RGB video streams. SPAN-Nav extracts spatial priors across diverse scenes through an occupancy prediction task on extensive indoor and outdoor environments. To mitigate the computational burden, we introduce a compact representation for spatial priors, finding that a single token is sufficient to encapsulate the coarse-grained cues essential for navigation tasks. Furthermore, inspired by the Chain-of-Thought (CoT) mechanism, SPAN-Nav utilizes this single spatial token to explicitly inject spatial cues into action reasoning through an end-to end framework. Leveraging multi-task co-training, SPAN-Nav captures task-adaptive cues from generalized spatial priors, enabling robust spatial awareness to generalize even to the task lacking explicit spatial supervision. To support comprehensive spatial learning, we present a massive dataset of 4.2 million occupancy annotations that covers both indoor and outdoor scenes across multi-type navigation tasks. SPAN-Nav achieves state-of-the-art performance across three benchmarks spanning diverse scenarios and varied navigation tasks. Finally, real-world experiments validate the robust generalization and practical reliability of our approach across complex physical scenarios.
Emerging Extrinsic Dexterity in Cluttered Scenes via Dynamics-aware Policy Learning
Mar 10, 2026Extrinsic dexterity leverages environmental contact to overcome the limitations of prehensile manipulation. However, achieving such dexterity in cluttered scenes remains challenging and underexplored, as it requires selectively exploiting contact among multiple interacting objects with inherently coupled dynamics. Existing approaches lack explicit modeling of such complex dynamics and therefore fall short in non-prehensile manipulation in cluttered environments, which in turn limits their practical applicability in real-world environments. In this paper, we introduce a Dynamics-Aware Policy Learning (DAPL) framework that can facilitate policy learning with a learned representation of contact-induced object dynamics in cluttered environments. This representation is learned through explicit world modeling and used to condition reinforcement learning, enabling extrinsic dexterity to emerge without hand-crafted contact heuristics or complex reward shaping. We evaluate our approach in both simulation and the real world. Our method outperforms prehensile manipulation, human teleoperation, and prior representation-based policies by over 25% in success rate on unseen simulated cluttered scenes with varying densities. The real-world success rate reaches around 50% across 10 cluttered scenes, while a practical grocery deployment further demonstrates robust sim-to-real transfer and applicability.
SimRecon: SimReady Compositional Scene Reconstruction from Real Videos
Mar 03, 2026Compositional scene reconstruction seeks to create object-centric representations rather than holistic scenes from real-world videos, which is natively applicable for simulation and interaction. Conventional compositional reconstruction approaches primarily emphasize on visual appearance and show limited generalization ability to real-world scenarios. In this paper, we propose SimRecon, a framework that realizes a "Perception-Generation-Simulation" pipeline towards cluttered scene reconstruction, which first conducts scene-level semantic reconstruction from video input, then performs single-object generation, and finally assembles these assets in the simulator. However, naively combining these three stages leads to visual infidelity of generated assets and physical implausibility of the final scene, a problem particularly severe for complex scenes. Thus, we further propose two bridging modules between the three stages to address this problem. To be specific, for the transition from Perception to Generation, critical for visual fidelity, we introduce Active Viewpoint Optimization, which actively searches in 3D space to acquire optimal projected images as conditions for single-object completion. Moreover, for the transition from Generation to Simulation, essential for physical plausibility, we propose a Scene Graph Synthesizer, which guides the construction from scratch in 3D simulators, mirroring the native, constructive principle of the real world. Extensive experiments on the ScanNet dataset validate our method's superior performance over previous state-of-the-art approaches.
LDA-1B: Scaling Latent Dynamics Action Model via Universal Embodied Data Ingestion
Feb 12, 2026Recent robot foundation models largely rely on large-scale behavior cloning, which imitates expert actions but discards transferable dynamics knowledge embedded in heterogeneous embodied data. While the Unified World Model (UWM) formulation has the potential to leverage such diverse data, existing instantiations struggle to scale to foundation-level due to coarse data usage and fragmented datasets. We introduce LDA-1B, a robot foundation model that scales through universal embodied data ingestion by jointly learning dynamics, policy, and visual forecasting, assigning distinct roles to data of varying quality. To support this regime at scale, we assemble and standardize EI-30k, an embodied interaction dataset comprising over 30k hours of human and robot trajectories in a unified format. Scalable dynamics learning over such heterogeneous data is enabled by prediction in a structured DINO latent space, which avoids redundant pixel-space appearance modeling. Complementing this representation, LDA-1B employs a multi-modal diffusion transformer to handle asynchronous vision and action streams, enabling stable training at the 1B-parameter scale. Experiments in simulation and the real world show LDA-1B outperforms prior methods (e.g., $π_{0.5}$) by up to 21\%, 48\%, and 23\% on contact-rich, dexterous, and long-horizon tasks, respectively. Notably, LDA-1B enables data-efficient fine-tuning, gaining 10\% by leveraging 30\% low-quality trajectories typically harmful and discarded.
Any3D-VLA: Enhancing VLA Robustness via Diverse Point Clouds
Jan 31, 2026Existing Vision-Language-Action (VLA) models typically take 2D images as visual input, which limits their spatial understanding in complex scenes. How can we incorporate 3D information to enhance VLA capabilities? We conduct a pilot study across different observation spaces and visual representations. The results show that explicitly lifting visual input into point clouds yields representations that better complement their corresponding 2D representations. To address the challenges of (1) scarce 3D data and (2) the domain gap induced by cross-environment differences and depth-scale biases, we propose Any3D-VLA. It unifies the simulator, sensor, and model-estimated point clouds within a training pipeline, constructs diverse inputs, and learns domain-agnostic 3D representations that are fused with the corresponding 2D representations. Simulation and real-world experiments demonstrate Any3D-VLA's advantages in improving performance and mitigating the domain gap. Our project homepage is available at https://xianzhefan.github.io/Any3D-VLA.github.io.
StereoVLA: Enhancing Vision-Language-Action Models with Stereo Vision
Dec 26, 2025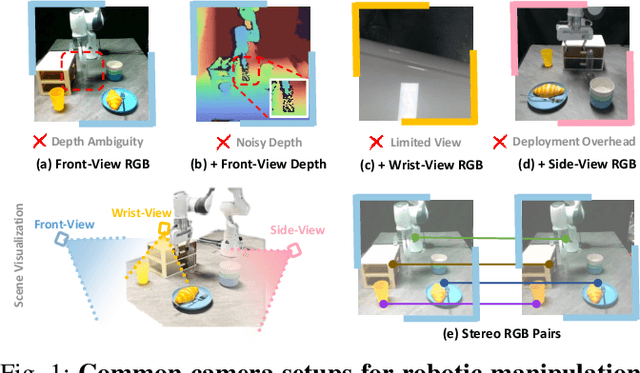
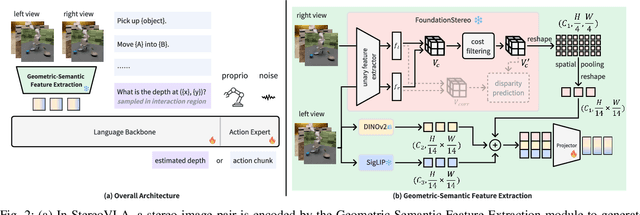
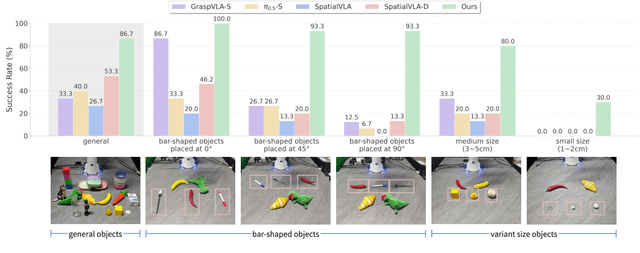
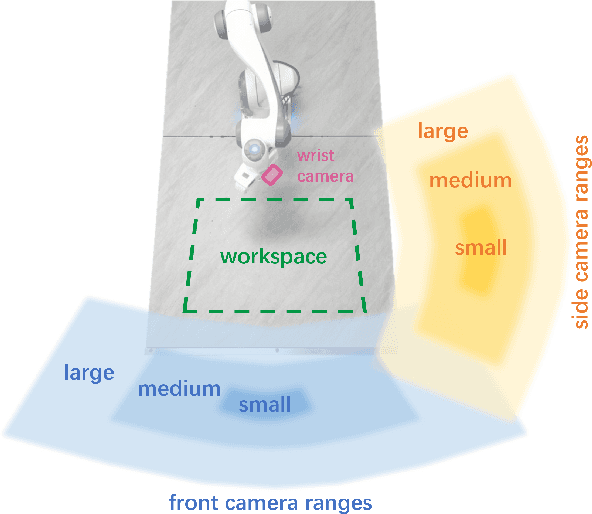
Stereo cameras closely mimic human binocular vision, providing rich spatial cues critical for precise robotic manipulation. Despite their advantage, the adoption of stereo vision in vision-language-action models (VLAs) remains underexplored. In this work, we present StereoVLA, a VLA model that leverages rich geometric cues from stereo vision. We propose a novel Geometric-Semantic Feature Extraction module that utilizes vision foundation models to extract and fuse two key features: 1) geometric features from subtle stereo-view differences for spatial perception; 2) semantic-rich features from the monocular view for instruction following. Additionally, we propose an auxiliary Interaction-Region Depth Estimation task to further enhance spatial perception and accelerate model convergence. Extensive experiments show that our approach outperforms baselines by a large margin in diverse tasks under the stereo setting and demonstrates strong robustness to camera pose variations.
TrackVLA++: Unleashing Reasoning and Memory Capabilities in VLA Models for Embodied Visual Tracking
Oct 08, 2025Embodied Visual Tracking (EVT) is a fundamental ability that underpins practical applications, such as companion robots, guidance robots and service assistants, where continuously following moving targets is essential. Recent advances have enabled language-guided tracking in complex and unstructured scenes. However, existing approaches lack explicit spatial reasoning and effective temporal memory, causing failures under severe occlusions or in the presence of similar-looking distractors. To address these challenges, we present TrackVLA++, a novel Vision-Language-Action (VLA) model that enhances embodied visual tracking with two key modules, a spatial reasoning mechanism and a Target Identification Memory (TIM). The reasoning module introduces a Chain-of-Thought paradigm, termed Polar-CoT, which infers the target's relative position and encodes it as a compact polar-coordinate token for action prediction. Guided by these spatial priors, the TIM employs a gated update strategy to preserve long-horizon target memory, ensuring spatiotemporal consistency and mitigating target loss during extended occlusions. Extensive experiments show that TrackVLA++ achieves state-of-the-art performance on public benchmarks across both egocentric and multi-camera settings. On the challenging EVT-Bench DT split, TrackVLA++ surpasses the previous leading approach by 5.1 and 12, respectively. Furthermore, TrackVLA++ exhibits strong zero-shot generalization, enabling robust real-world tracking in dynamic and occluded scenarios.
DexVLG: Dexterous Vision-Language-Grasp Model at Scale
Jul 03, 2025As large models gain traction, vision-language-action (VLA) systems are enabling robots to tackle increasingly complex tasks. However, limited by the difficulty of data collection, progress has mainly focused on controlling simple gripper end-effectors. There is little research on functional grasping with large models for human-like dexterous hands. In this paper, we introduce DexVLG, a large Vision-Language-Grasp model for Dexterous grasp pose prediction aligned with language instructions using single-view RGBD input. To accomplish this, we generate a dataset of 170 million dexterous grasp poses mapped to semantic parts across 174,000 objects in simulation, paired with detailed part-level captions. This large-scale dataset, named DexGraspNet 3.0, is used to train a VLM and flow-matching-based pose head capable of producing instruction-aligned grasp poses for tabletop objects. To assess DexVLG's performance, we create benchmarks in physics-based simulations and conduct real-world experiments. Extensive testing demonstrates DexVLG's strong zero-shot generalization capabilities-achieving over 76% zero-shot execution success rate and state-of-the-art part-grasp accuracy in simulation-and successful part-aligned grasps on physical objects in real-world scenarios.
TrackVLA: Embodied Visual Tracking in the Wild
May 29, 2025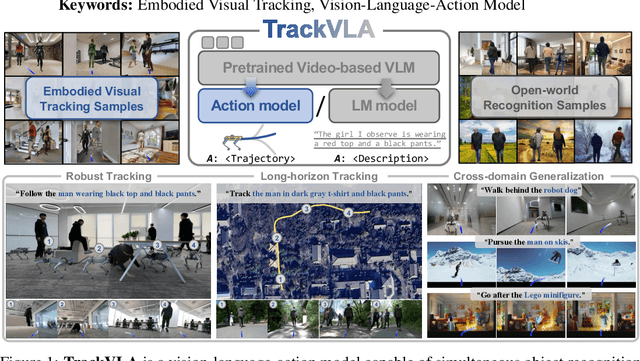

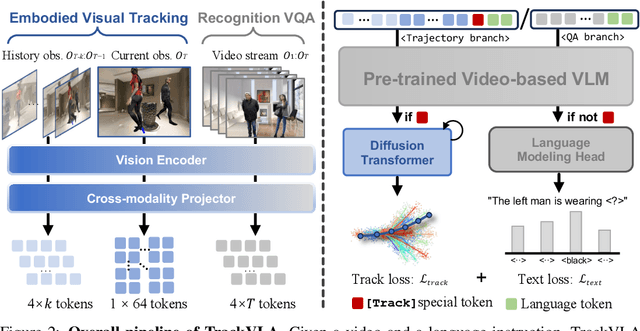
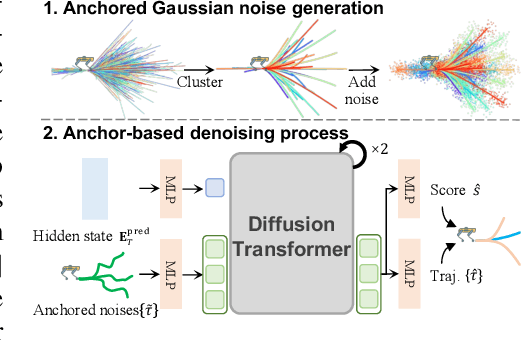
Embodied visual tracking is a fundamental skill in Embodied AI, enabling an agent to follow a specific target in dynamic environments using only egocentric vision. This task is inherently challenging as it requires both accurate target recognition and effective trajectory planning under conditions of severe occlusion and high scene dynamics. Existing approaches typically address this challenge through a modular separation of recognition and planning. In this work, we propose TrackVLA, a Vision-Language-Action (VLA) model that learns the synergy between object recognition and trajectory planning. Leveraging a shared LLM backbone, we employ a language modeling head for recognition and an anchor-based diffusion model for trajectory planning. To train TrackVLA, we construct an Embodied Visual Tracking Benchmark (EVT-Bench) and collect diverse difficulty levels of recognition samples, resulting in a dataset of 1.7 million samples. Through extensive experiments in both synthetic and real-world environments, TrackVLA demonstrates SOTA performance and strong generalizability. It significantly outperforms existing methods on public benchmarks in a zero-shot manner while remaining robust to high dynamics and occlusion in real-world scenarios at 10 FPS inference speed. Our project page is: https://pku-epic.github.io/TrackVLA-web.