 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHairLRM: Strand-based Hair Modeling via Large Reconstruction Models
Jun 13, 2026The fundamental limitation of traditional strand-based modeling is not simply data scarcity, but the ill-posedness of inferring complex 3D fields from 2D imagery without structural constraints. This unconstrained regression leads to catastrophic failures in resolving both global occlusion (e.g., in ponytails) and local directionality (e.g., in curls), resulting in over-smoothed, plausible-but-incorrect geometries. To resolve this, we integrate the strong geometric priors of Large Reconstruction Models (LRMs) into the strand generation pipeline. Using the LRM mesh as a structural anchor, we employ a novel Dual Orientation AutoEncoder to lift coarse geometry into high-fidelity strands. By resolving vector field singularities through latent-space optimization and surface-guided refinement, our method effectively disentangles complex topological structures, setting a new benchmark for robustness and accuracy in hair reconstruction.
RescueBench: Can Embodied Agents Save Lives in the Wild ?
Jun 01, 2026Search-and-rescue (SAR) requires embodied agents to explore unfamiliar environments under multimodal uncertainty, perform multi-stage interactions, and retrieve spatial memory over long horizons. Existing benchmarks typically evaluate these capabilities in isolation, leaving unclear how failures compound when they must be composed in realistic workflows. We introduce RescueBench, a photo-realistic diagnostic benchmark that instantiates SAR as a four-stage pipeline: multimodal exploration, target rescue, memory-guided return, and final handoff. By combining sequential task composition with stage-level evaluation, RescueBench enables analysis of how exploration and memory failures propagate through embodied rescue workflows. It contains five progressive difficulty levels that vary in environmental complexity, clue ambiguity, and spatial hierarchy, along with an automatic episode generation and annotation pipeline for scalable evaluation and training. We evaluate seven baselines, an oracle reference, and human players, showing that no baselines complete the full task at the greatest difficulty. Stage-level diagnosis identifies autonomous exploration as the dominant failure mode and spatial memory as a second, independent bottleneck, suggesting that these limitations are not resolved by current topological visual-language navigation or map-based methods. Code is available in https://github.com/wukui-muc/RescueBench
AdaTracker: Learning Adaptive In-Context Policy for Cross-Embodiment Active Visual Tracking
Apr 22, 2026Realizing active visual tracking with a single unified model across diverse robots is challenging, as the physical constraints and motion dynamics vary drastically from one platform to another. Existing approaches typically train separate models for each embodiment, leading to poor scalability and limited generalization. To address this, we propose AdaTracker, an adaptive in-context policy learning framework that robustly tracks targets on diverse robot morphologies. Our key insight is to explicitly model embodiment-specific constraints through an Embodiment Context Encoder, which infers embodiment-specific constraints from history. This contextual representation dynamically modulates a Context-Aware Policy, enabling it to infer optimal control actions for unseen embodiments in a zero-shot manner. To enhance robustness, we introduce two auxiliary objectives to ensure accurate context identification and temporal consistency. Experiments in both simulation and the real world demonstrate that AdaTracker significantly outperforms state-of-the-art methods in cross-embodiment generalization, sample efficiency, and zero-shot adaptation.
Bridging Linguistic Gaps: Cross-Lingual Mapping in Pre-Training and Dataset for Enhanced Multilingual LLM Performance
Apr 12, 2026Multilingual Large Language Models (LLMs) struggle with cross-lingual tasks due to data imbalances between high-resource and low-resource languages, as well as monolingual bias in pre-training. Existing methods, such as bilingual fine-tuning and contrastive alignment, can improve cross-lingual performance, but they often require extensive parallel data or suffer from instability. To address these challenges, we introduce a Cross-Lingual Mapping Task during the pre-training phase, which enhances cross-lingual alignment without compromising monolingual fluency. Our approach bi-directionally maps languages within the LLM embedding space, improving both language generation and comprehension. We further propose a Language Alignment Coefficient to robustly quantify cross-lingual consistency, even in limited-data scenarios. Experimental results on machine translation (MT), cross-lingual natural language understanding (CLNLU), and cross-lingual question answering (CLQA) show that our model achieves gains of up to 11.9 BLEU points in MT, 6.72 points in CLQA BERTScore-Precision, and more than 5% in CLNLU accuracy over strong multilingual baselines. These findings highlight the potential of incorporating cross-lingual objectives into pre-training to improve multilingual LLMs.
Real-time Neural Six-way Lightmaps
Apr 04, 2026Participating media are a pervasive and intriguing visual effect in virtual environments. Unfortunately, rendering such phenomena in real-time is notoriously difficult due to the computational expense of estimating the volume rendering equation. While the six-way lightmaps technique has been widely used in video games to render smoke with a camera-oriented billboard and approximate lighting effects using six precomputed lightmaps, achieving a balance between realism and efficiency, it is limited to pre-simulated animation sequences and is ignorant of camera movement. In this work, we propose a neural six-way lightmaps method to strike a long-sought balance between dynamics and visual realism. Our approach first generates a guiding map from the camera view using ray marching with a large sampling distance to approximate smoke scattering and silhouette. Then, given a guiding map, we train a neural network to predict the corresponding six-way lightmaps. The resulting lightmaps can be seamlessly used in existing game engine pipelines. This approach supports visually appealing rendering effects while enabling real-time user interactivity, including smoke-obstacle interaction, camera movement, and light change. By conducting a series of comprehensive benchmarks, we demonstrate that our method is well-suited for real-time applications, such as games and VR/AR.
Pay for Hints, Not Answers: LLM Shepherding for Cost-Efficient Inference
Jan 29, 2026Large Language Models (LLMs) deliver state-of-the-art performance on complex reasoning tasks, but their inference costs limit deployment at scale. Small Language Models (SLMs) offer dramatic cost savings yet lag substantially in accuracy. Existing approaches - routing and cascading - treat the LLM as an all-or-nothing resource: either the query bypasses the LLM entirely, or the LLM generates a complete response at full cost. We introduce LLM Shepherding, a framework that requests only a short prefix (a hint) from the LLM and provides it to SLM. This simple mechanism is surprisingly effective for math and coding tasks: even hints comprising 10-30% of the full LLM response improve SLM accuracy significantly. Shepherding generalizes both routing and cascading, and it achieves lower cost under oracle decision-making. We develop a two-stage predictor that jointly determines whether a hint is needed and how many tokens to request. On the widely-used mathematical reasoning (GSM8K, CNK12) and code generation (HumanEval, MBPP) benchmarks, Shepherding reduces costs by 42-94% relative to LLM-only inference. Compared to state-of-the-art routing and cascading baselines, shepherding delivers up to 2.8x cost reduction while matching accuracy. To our knowledge, this is the first work to exploit token-level budget control for SLM-LLM collaboration.
Birth of a Painting: Differentiable Brushstroke Reconstruction
Nov 17, 2025Painting embodies a unique form of visual storytelling, where the creation process is as significant as the final artwork. Although recent advances in generative models have enabled visually compelling painting synthesis, most existing methods focus solely on final image generation or patch-based process simulation, lacking explicit stroke structure and failing to produce smooth, realistic shading. In this work, we present a differentiable stroke reconstruction framework that unifies painting, stylized texturing, and smudging to faithfully reproduce the human painting-smudging loop. Given an input image, our framework first optimizes single- and dual-color Bezier strokes through a parallel differentiable paint renderer, followed by a style generation module that synthesizes geometry-conditioned textures across diverse painting styles. We further introduce a differentiable smudge operator to enable natural color blending and shading. Coupled with a coarse-to-fine optimization strategy, our method jointly optimizes stroke geometry, color, and texture under geometric and semantic guidance. Extensive experiments on oil, watercolor, ink, and digital paintings demonstrate that our approach produces realistic and expressive stroke reconstructions, smooth tonal transitions, and richly stylized appearances, offering a unified model for expressive digital painting creation. See our project page for more demos: https://yingjiang96.github.io/DiffPaintWebsite/.
CaberNet: Causal Representation Learning for Cross-Domain HVAC Energy Prediction
Nov 10, 2025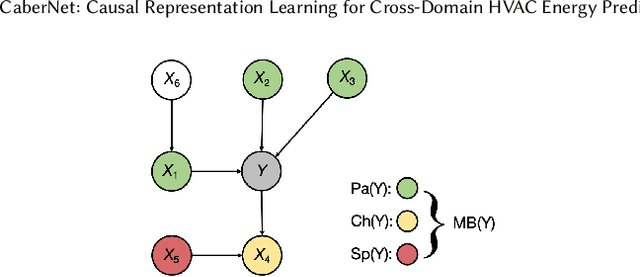



Cross-domain HVAC energy prediction is essential for scalable building energy management, particularly because collecting extensive labeled data for every new building is both costly and impractical. Yet, this task remains highly challenging due to the scarcity and heterogeneity of data across different buildings, climate zones, and seasonal patterns. In particular, buildings situated in distinct climatic regions introduce variability that often leads existing methods to overfit to spurious correlations, rely heavily on expert intervention, or compromise on data diversity. To address these limitations, we propose CaberNet, a causal and interpretable deep sequence model that learns invariant (Markov blanket) representations for robust cross-domain prediction. In a purely data-driven fashion and without requiring any prior knowledge, CaberNet integrates i) a global feature gate trained with a self-supervised Bernoulli regularization to distinguish superior causal features from inferior ones, and ii) a domain-wise training scheme that balances domain contributions, minimizes cross-domain loss variance, and promotes latent factor independence. We evaluate CaberNet on real-world datasets collected from three buildings located in three climatically diverse cities, and it consistently outperforms all baselines, achieving a 22.9\% reduction in normalized mean squared error (NMSE) compared to the best benchmark. Our code is available at https://github.com/rickzky1001/CaberNet-CRL.
TrackVLA++: Unleashing Reasoning and Memory Capabilities in VLA Models for Embodied Visual Tracking
Oct 08, 2025Embodied Visual Tracking (EVT) is a fundamental ability that underpins practical applications, such as companion robots, guidance robots and service assistants, where continuously following moving targets is essential. Recent advances have enabled language-guided tracking in complex and unstructured scenes. However, existing approaches lack explicit spatial reasoning and effective temporal memory, causing failures under severe occlusions or in the presence of similar-looking distractors. To address these challenges, we present TrackVLA++, a novel Vision-Language-Action (VLA) model that enhances embodied visual tracking with two key modules, a spatial reasoning mechanism and a Target Identification Memory (TIM). The reasoning module introduces a Chain-of-Thought paradigm, termed Polar-CoT, which infers the target's relative position and encodes it as a compact polar-coordinate token for action prediction. Guided by these spatial priors, the TIM employs a gated update strategy to preserve long-horizon target memory, ensuring spatiotemporal consistency and mitigating target loss during extended occlusions. Extensive experiments show that TrackVLA++ achieves state-of-the-art performance on public benchmarks across both egocentric and multi-camera settings. On the challenging EVT-Bench DT split, TrackVLA++ surpasses the previous leading approach by 5.1 and 12, respectively. Furthermore, TrackVLA++ exhibits strong zero-shot generalization, enabling robust real-world tracking in dynamic and occluded scenarios.
Handle-based Mesh Deformation Guided By Vision Language Model
Jun 05, 2025Mesh deformation is a fundamental tool in 3D content manipulation. Despite extensive prior research, existing approaches often suffer from low output quality, require significant manual tuning, or depend on data-intensive training. To address these limitations, we introduce a training-free, handle-based mesh deformation method. % Our core idea is to leverage a Vision-Language Model (VLM) to interpret and manipulate a handle-based interface through prompt engineering. We begin by applying cone singularity detection to identify a sparse set of potential handles. The VLM is then prompted to select both the deformable sub-parts of the mesh and the handles that best align with user instructions. Subsequently, we query the desired deformed positions of the selected handles in screen space. To reduce uncertainty inherent in VLM predictions, we aggregate the results from multiple camera views using a novel multi-view voting scheme. % Across a suite of benchmarks, our method produces deformations that align more closely with user intent, as measured by CLIP and GPTEval3D scores, while introducing low distortion -- quantified via membrane energy. In summary, our approach is training-free, highly automated, and consistently delivers high-quality mesh deformations.