 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry Reinforced Efficient Attention Tuning Equipped with Normals for Robust Stereo Matching
Apr 10, 2026Despite remarkable advances in image-driven stereo matching over the past decade, Synthetic-to-Realistic Zero-Shot (Syn-to-Real) generalization remains an open challenge. This suboptimal generalization performance mainly stems from cross-domain shifts and ill-posed ambiguities inherent in image textures, particularly in occluded, textureless, repetitive, and non-Lambertian (specular/transparent) regions. To improve Syn-to-Real generalization, we propose GREATEN, a framework that incorporates surface normals as domain-invariant, object-intrinsic, and discriminative geometric cues to compensate for the limitations of image textures. The proposed framework consists of three key components. First, a Gated Contextual-Geometric Fusion (GCGF) module adaptively suppresses unreliable contextual cues in image features and fuses the filtered image features with normal-driven geometric features to construct domain-invariant and discriminative contextual-geometric representations. Second, a Specular-Transparent Augmentation (STA) strategy improves the robustness of GCGF against misleading visual cues in non-Lambertian regions. Third, sparse attention designs preserve the fine-grained global feature extraction capability of GREAT-Stereo for handling occlusion and texture-related ambiguities while substantially reducing computational overhead, including Sparse Spatial (SSA), Sparse Dual-Matching (SDMA), and Simple Volume (SVA) attentions. Trained exclusively on synthetic data such as SceneFlow, GREATEN-IGEV achieves outstanding Syn-to-Real performance. Specifically, it reduces errors by 30% on ETH3D, 8.5% on the non-Lambertian Booster, and 14.1% on KITTI-2015, compared to FoundationStereo, Monster-Stereo, and DEFOM-Stereo, respectively. In addition, GREATEN-IGEV runs 19.2% faster than GREAT-IGEV and supports high-resolution (3K) inference on Middlebury with disparity ranges up to 768.
Global Regulation and Excitation via Attention Tuning for Stereo Matching
Sep 19, 2025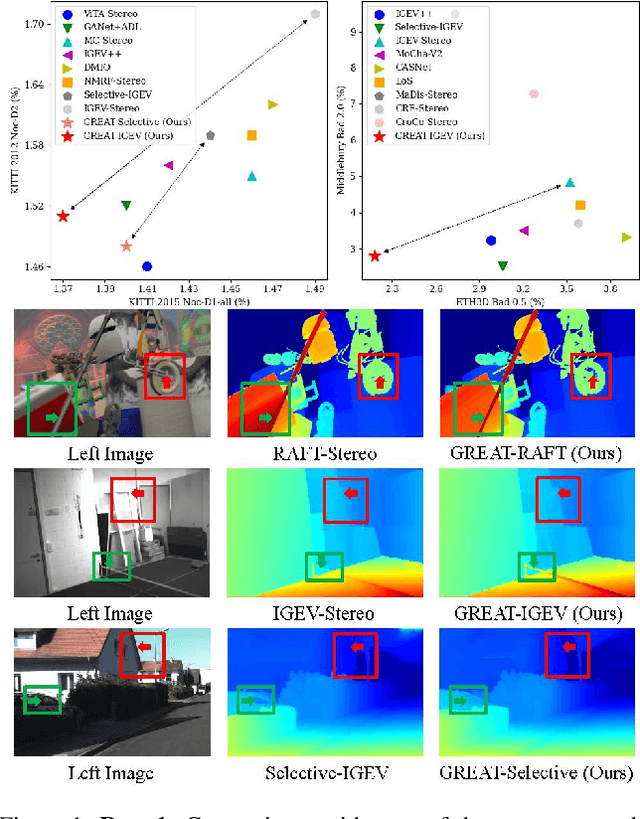
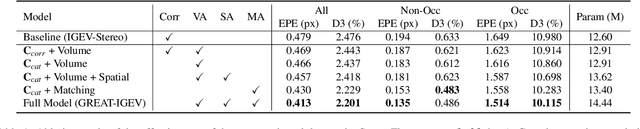
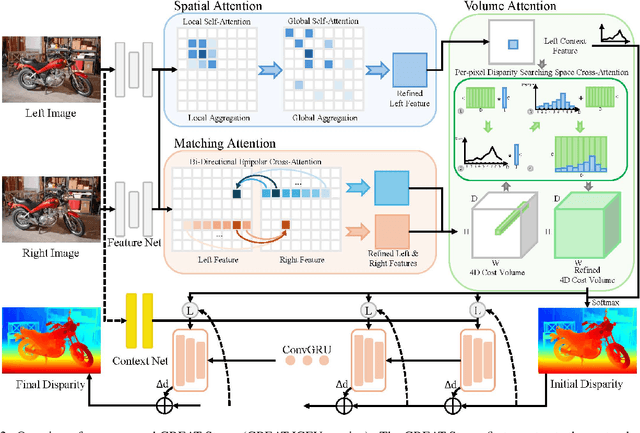
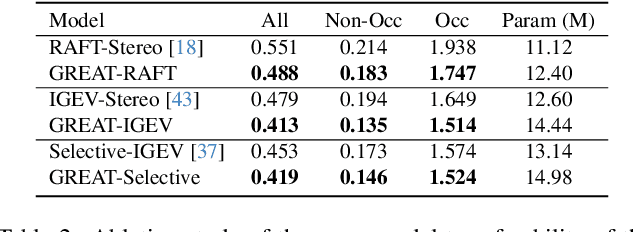
Stereo matching achieves significant progress with iterative algorithms like RAFT-Stereo and IGEV-Stereo. However, these methods struggle in ill-posed regions with occlusions, textureless, or repetitive patterns, due to a lack of global context and geometric information for effective iterative refinement. To enable the existing iterative approaches to incorporate global context, we propose the Global Regulation and Excitation via Attention Tuning (GREAT) framework which encompasses three attention modules. Specifically, Spatial Attention (SA) captures the global context within the spatial dimension, Matching Attention (MA) extracts global context along epipolar lines, and Volume Attention (VA) works in conjunction with SA and MA to construct a more robust cost-volume excited by global context and geometric details. To verify the universality and effectiveness of this framework, we integrate it into several representative iterative stereo-matching methods and validate it through extensive experiments, collectively denoted as GREAT-Stereo. This framework demonstrates superior performance in challenging ill-posed regions. Applied to IGEV-Stereo, among all published methods, our GREAT-IGEV ranks first on the Scene Flow test set, KITTI 2015, and ETH3D leaderboards, and achieves second on the Middlebury benchmark. Code is available at https://github.com/JarvisLee0423/GREAT-Stereo.
CoT-VLM4Tar: Chain-of-Thought Guided Vision-Language Models for Traffic Anomaly Resolution
Mar 03, 2025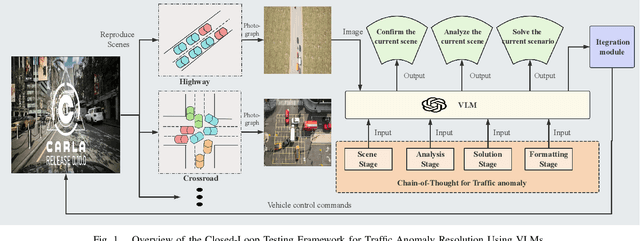
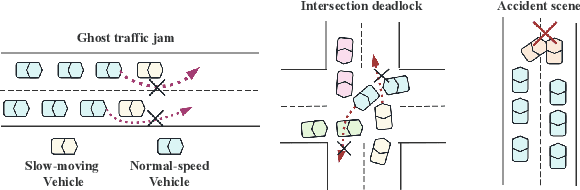
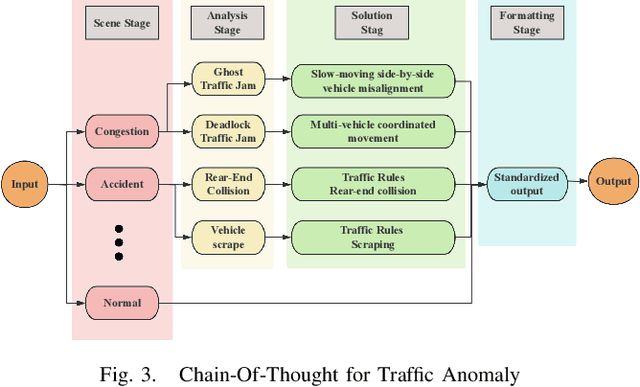
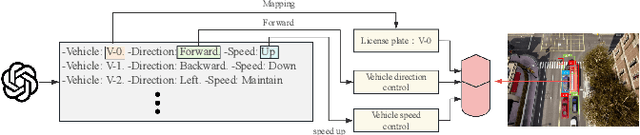
With the acceleration of urbanization, modern urban traffic systems are becoming increasingly complex, leading to frequent traffic anomalies. These anomalies encompass not only common traffic jams but also more challenging issues such as phantom traffic jams, intersection deadlocks, and accident liability analysis, which severely impact traffic flow, vehicular safety, and overall transportation efficiency. Currently, existing solutions primarily rely on manual intervention by traffic police or artificial intelligence-based detection systems. However, these methods often suffer from response delays and inconsistent management due to inadequate resources, while AI detection systems, despite enhancing efficiency to some extent, still struggle to handle complex traffic anomalies in a real-time and precise manner. To address these issues, we propose CoT-VLM4Tar: (Chain of Thought Visual-Language Model for Traffic Anomaly Resolution), this innovative approach introduces a new chain-of-thought to guide the VLM in analyzing, reasoning, and generating solutions for traffic anomalies with greater reasonable and effective solution, and to evaluate the performance and effectiveness of our method, we developed a closed-loop testing framework based on the CARLA simulator. Furthermore, to ensure seamless integration of the solutions generated by the VLM with the CARLA simulator, we implement an itegration module that converts these solutions into executable commands. Our results demonstrate the effectiveness of VLM in the resolution of real-time traffic anomalies, providing a proof-of-concept for its integration into autonomous traffic management systems.
CoDynTrust: Robust Asynchronous Collaborative Perception via Dynamic Feature Trust Modulus
Feb 12, 2025



Collaborative perception, fusing information from multiple agents, can extend perception range so as to improve perception performance. However, temporal asynchrony in real-world environments, caused by communication delays, clock misalignment, or sampling configuration differences, can lead to information mismatches. If this is not well handled, then the collaborative performance is patchy, and what's worse safety accidents may occur. To tackle this challenge, we propose CoDynTrust, an uncertainty-encoded asynchronous fusion perception framework that is robust to the information mismatches caused by temporal asynchrony. CoDynTrust generates dynamic feature trust modulus (DFTM) for each region of interest by modeling aleatoric and epistemic uncertainty as well as selectively suppressing or retaining single-vehicle features, thereby mitigating information mismatches. We then design a multi-scale fusion module to handle multi-scale feature maps processed by DFTM. Compared to existing works that also consider asynchronous collaborative perception, CoDynTrust combats various low-quality information in temporally asynchronous scenarios and allows uncertainty to be propagated to downstream tasks such as planning and control. Experimental results demonstrate that CoDynTrust significantly reduces performance degradation caused by temporal asynchrony across multiple datasets, achieving state-of-the-art detection performance even with temporal asynchrony. The code is available at https://github.com/CrazyShout/CoDynTrust.
BehaviorGPT: Smart Agent Simulation for Autonomous Driving with Next-Patch Prediction
May 27, 2024



Simulating realistic interactions among traffic agents is crucial for efficiently validating the safety of autonomous driving systems. Existing leading simulators primarily use an encoder-decoder structure to encode the historical trajectories for future simulation. However, such a paradigm complicates the model architecture, and the manual separation of history and future trajectories leads to low data utilization. To address these challenges, we propose Behavior Generative Pre-trained Transformers (BehaviorGPT), a decoder-only, autoregressive architecture designed to simulate the sequential motion of multiple agents. Crucially, our approach discards the traditional separation between "history" and "future," treating each time step as the "current" one, resulting in a simpler, more parameter- and data-efficient design that scales seamlessly with data and computation. Additionally, we introduce the Next-Patch Prediction Paradigm (NP3), which enables models to reason at the patch level of trajectories and capture long-range spatial-temporal interactions. BehaviorGPT ranks first across several metrics on the Waymo Sim Agents Benchmark, demonstrating its exceptional performance in multi-agent and agent-map interactions. We outperformed state-of-the-art models with a realism score of 0.741 and improved the minADE metric to 1.540, with an approximately 91.6% reduction in model parameters.
Recognizing Conditional Causal Relationships about Emotions and Their Corresponding Conditions
Nov 28, 2023The study of causal relationships between emotions and causes in texts has recently received much attention. Most works focus on extracting causally related clauses from documents. However, none of these works has considered that the causal relationships among the extracted emotion and cause clauses can only be valid under some specific context clauses. To highlight the context in such special causal relationships, we propose a new task to determine whether or not an input pair of emotion and cause has a valid causal relationship under different contexts and extract the specific context clauses that participate in the causal relationship. Since the task is new for which no existing dataset is available, we conduct manual annotation on a benchmark dataset to obtain the labels for our tasks and the annotations of each context clause's type that can also be used in some other applications. We adopt negative sampling to construct the final dataset to balance the number of documents with and without causal relationships. Based on the constructed dataset, we propose an end-to-end multi-task framework, where we design two novel and general modules to handle the two goals of our task. Specifically, we propose a context masking module to extract the context clauses participating in the causal relationships. We propose a prediction aggregation module to fine-tune the prediction results according to whether the input emotion and causes depend on specific context clauses. Results of extensive comparative experiments and ablation studies demonstrate the effectiveness and generality of our proposed framework.
Exploring OCR Capabilities of GPT-4V : A Quantitative and In-depth Evaluation
Oct 29, 2023



This paper presents a comprehensive evaluation of the Optical Character Recognition (OCR) capabilities of the recently released GPT-4V(ision), a Large Multimodal Model (LMM). We assess the model's performance across a range of OCR tasks, including scene text recognition, handwritten text recognition, handwritten mathematical expression recognition, table structure recognition, and information extraction from visually-rich document. The evaluation reveals that GPT-4V performs well in recognizing and understanding Latin contents, but struggles with multilingual scenarios and complex tasks. Specifically, it showed limitations when dealing with non-Latin languages and complex tasks such as handwriting mathematical expression recognition, table structure recognition, and end-to-end semantic entity recognition and pair extraction from document image. Based on these observations, we affirm the necessity and continued research value of specialized OCR models. In general, despite its versatility in handling diverse OCR tasks, GPT-4V does not outperform existing state-of-the-art OCR models. How to fully utilize pre-trained general-purpose LMMs such as GPT-4V for OCR downstream tasks remains an open problem. The study offers a critical reference for future research in OCR with LMMs. Evaluation pipeline and results are available at https://github.com/SCUT-DLVCLab/GPT-4V_OCR.
TOFG: A Unified and Fine-Grained Environment Representation in Autonomous Driving
May 31, 2023



In autonomous driving, an accurate understanding of environment, e.g., the vehicle-to-vehicle and vehicle-to-lane interactions, plays a critical role in many driving tasks such as trajectory prediction and motion planning. Environment information comes from high-definition (HD) map and historical trajectories of vehicles. Due to the heterogeneity of the map data and trajectory data, many data-driven models for trajectory prediction and motion planning extract vehicle-to-vehicle and vehicle-to-lane interactions in a separate and sequential manner. However, such a manner may capture biased interpretation of interactions, causing lower prediction and planning accuracy. Moreover, separate extraction leads to a complicated model structure and hence the overall efficiency and scalability are sacrificed. To address the above issues, we propose an environment representation, Temporal Occupancy Flow Graph (TOFG). Specifically, the occupancy flow-based representation unifies the map information and vehicle trajectories into a homogeneous data format and enables a consistent prediction. The temporal dependencies among vehicles can help capture the change of occupancy flow timely to further promote model performance. To demonstrate that TOFG is capable of simplifying the model architecture, we incorporate TOFG with a simple graph attention (GAT) based neural network and propose TOFG-GAT, which can be used for both trajectory prediction and motion planning. Experiment results show that TOFG-GAT achieves better or competitive performance than all the SOTA baselines with less training time.
MDL-based Compressing Sequential Rules
Dec 20, 2022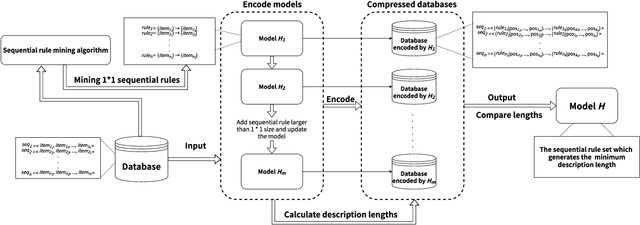
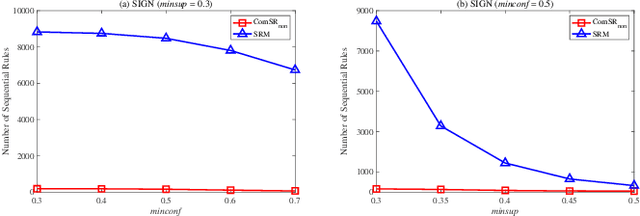

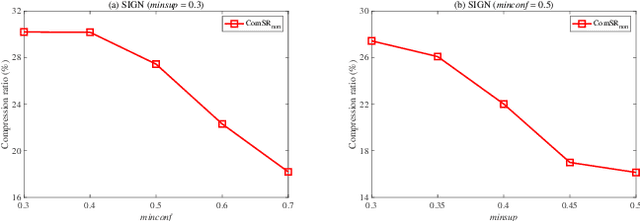
Nowadays, with the rapid development of the Internet, the era of big data has come. The Internet generates huge amounts of data every day. However, extracting meaningful information from massive data is like looking for a needle in a haystack. Data mining techniques can provide various feasible methods to solve this problem. At present, many sequential rule mining (SRM) algorithms are presented to find sequential rules in databases with sequential characteristics. These rules help people extract a lot of meaningful information from massive amounts of data. How can we achieve compression of mined results and reduce data size to save storage space and transmission time? Until now, there has been little research on the compression of SRM. In this paper, combined with the Minimum Description Length (MDL) principle and under the two metrics (support and confidence), we introduce the problem of compression of SRM and also propose a solution named ComSR for MDL-based compressing of sequential rules based on the designed sequential rule coding scheme. To our knowledge, we are the first to use sequential rules to encode an entire database. A heuristic method is proposed to find a set of compact and meaningful sequential rules as much as possible. ComSR has two trade-off algorithms, ComSR_non and ComSR_ful, based on whether the database can be completely compressed. Experiments done on a real dataset with different thresholds show that a set of compact and meaningful sequential rules can be found. This shows that the proposed method works.
A Generative Car-following Model Conditioned On Driving Styles
Dec 10, 2021
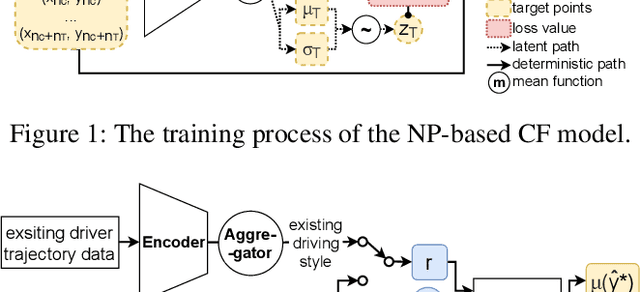
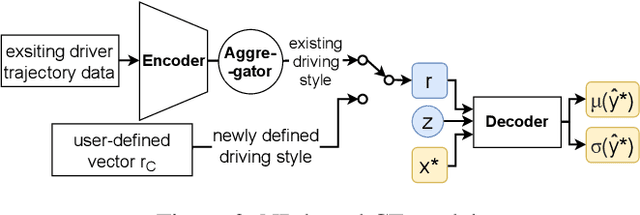
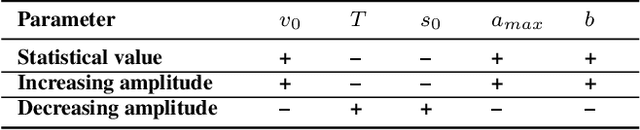
Car-following (CF) modeling, an essential component in simulating human CF behaviors, has attracted increasing research interest in the past decades. This paper pushes the state of the art by proposing a novel generative hybrid CF model, which achieves high accuracy in characterizing dynamic human CF behaviors and is able to generate realistic human CF behaviors for any given observed or even unobserved driving style. Specifically, the ability of accurately capturing human CF behaviors is ensured by designing and calibrating an Intelligent Driver Model (IDM) with time-varying parameters. The reason behind is that such time-varying parameters can express both the inter-driver heterogeneity, i.e., diverse driving styles of different drivers, and the intra-driver heterogeneity, i.e., changing driving styles of the same driver. The ability of generating realistic human CF behaviors of any given observed driving style is achieved by applying a neural process (NP) based model. The ability of inferring CF behaviors of unobserved driving styles is supported by exploring the relationship between the calibrated time-varying IDM parameters and an intermediate variable of NP. To demonstrate the effectiveness of our proposed models, we conduct extensive experiments and comparisons, including CF model parameter calibration, CF behavior prediction, and trajectory simulation for different driving styles.