 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Acceleration for Document Parsing Vision-Language Model with Hierarchical Speculative Decoding
Feb 13, 2026Document parsing is a fundamental task in multimodal understanding, supporting a wide range of downstream applications such as information extraction and intelligent document analysis. Benefiting from strong semantic modeling and robust generalization, VLM-based end-to-end approaches have emerged as the mainstream paradigm in recent years. However, these models often suffer from substantial inference latency, as they must auto-regressively generate long token sequences when processing long-form documents. In this work, motivated by the extremely long outputs and complex layout structures commonly found in document parsing, we propose a training-free and highly efficient acceleration method. Inspired by speculative decoding, we employ a lightweight document parsing pipeline as a draft model to predict batches of future tokens, while the more accurate VLM verifies these draft predictions in parallel. Moreover, we further exploit the layout-structured nature of documents by partitioning each page into independent regions, enabling parallel decoding of each region using the same draft-verify strategy. The final predictions are then assembled according to the natural reading order. Experimental results demonstrate the effectiveness of our approach: on the general-purpose OmniDocBench, our method provides a 2.42x lossless acceleration for the dots.ocr model, and achieves up to 4.89x acceleration on long-document parsing tasks. We will release our code to facilitate reproducibility and future research.
Beyond Token Compression: A Training-Free Reduction Framework for Efficient Visual Processing in MLLMs
Jan 31, 2025



Multimodal Large Language Models (MLLMs) are typically based on decoder-only or cross-attention architectures. While decoder-only MLLMs outperform their cross-attention counterparts, they require significantly higher computational resources due to extensive self-attention and FFN operations on visual tokens. This raises the question: can we eliminate these expensive operations while maintaining the performance? To this end, we present a novel analysis framework to investigate the necessity of these costly operations in decoder-only MLLMs. Our framework introduces two key innovations: (1) Hollow Attention, which limits visual token interactions to local attention while maintaining visual-text associations, and (2) Probe-Activated Dynamic FFN, which selectively activates FFN parameters for visual tokens. Both methods do not require fine-tuning, which significantly enhances analysis efficiency. To assess the impact of applying these reductions across different proportions of layers, we developed a greedy search method that significantly narrows the search space. Experiments on state-of-the-art MLLMs reveal that applying our reductions to approximately half of the layers not only maintains but sometimes improves model performance, indicating significant computational redundancy in current architectures. Additionally, our method is orthogonal to existing token compression techniques, allowing for further combination to achieve greater computational reduction. Our findings may provide valuable insights for the design of more efficient future MLLMs. Our code will be publicly available at https://github.com/L-Hugh/Beyond-Token-Compression.
DocLayLLM: An Efficient and Effective Multi-modal Extension of Large Language Models for Text-rich Document Understanding
Aug 27, 2024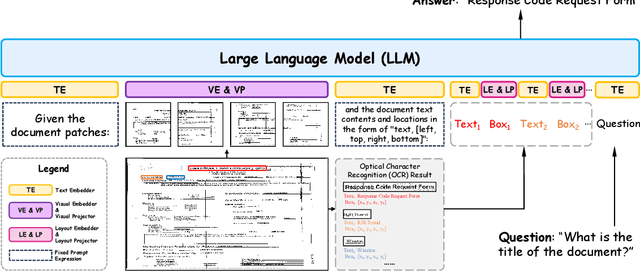


Text-rich document understanding (TDU) refers to analyzing and comprehending documents containing substantial textual content. With the rapid evolution of large language models (LLMs), they have been widely leveraged for TDU due to their remarkable versatility and generalization. In this paper, we introduce DocLayLLM, an efficient and effective multi-modal extension of LLMs specifically designed for TDU. By integrating visual patch tokens and 2D positional tokens into LLMs and encoding the document content using the LLMs themselves, we fully take advantage of the document comprehension capability of LLMs and enhance their perception of OCR information. We have also deeply considered the role of the chain-of-thought (CoT) and innovatively proposed the techniques of CoT Pre-training and CoT Annealing. Our DocLayLLM can achieve remarkable performances with lightweight training settings, showcasing its efficiency and effectiveness. Experimental results demonstrate that our DocLayLLM surpasses existing OCR-dependent methods and also outperforms OCR-free competitors.
PEneo: Unifying Line Extraction, Line Grouping, and Entity Linking for End-to-end Document Pair Extraction
Jan 07, 2024



Document pair extraction aims to identify key and value entities as well as their relationships from visually-rich documents. Most existing methods divide it into two separate tasks: semantic entity recognition (SER) and relation extraction (RE). However, simply concatenating SER and RE serially can lead to severe error propagation, and it fails to handle cases like multi-line entities in real scenarios. To address these issues, this paper introduces a novel framework, PEneo (Pair Extraction new decoder option), which performs document pair extraction in a unified pipeline, incorporating three concurrent sub-tasks: line extraction, line grouping, and entity linking. This approach alleviates the error accumulation problem and can handle the case of multi-line entities. Furthermore, to better evaluate the model's performance and to facilitate future research on pair extraction, we introduce RFUND, a re-annotated version of the commonly used FUNSD and XFUND datasets, to make them more accurate and cover realistic situations. Experiments on various benchmarks demonstrate PEneo's superiority over previous pipelines, boosting the performance by a large margin (e.g., 19.89%-22.91% F1 score on RFUND-EN) when combined with various backbones like LiLT and LayoutLMv3, showing its effectiveness and generality. Codes and the new annotations will be open to the public.
Exploring OCR Capabilities of GPT-4V : A Quantitative and In-depth Evaluation
Oct 29, 2023



This paper presents a comprehensive evaluation of the Optical Character Recognition (OCR) capabilities of the recently released GPT-4V(ision), a Large Multimodal Model (LMM). We assess the model's performance across a range of OCR tasks, including scene text recognition, handwritten text recognition, handwritten mathematical expression recognition, table structure recognition, and information extraction from visually-rich document. The evaluation reveals that GPT-4V performs well in recognizing and understanding Latin contents, but struggles with multilingual scenarios and complex tasks. Specifically, it showed limitations when dealing with non-Latin languages and complex tasks such as handwriting mathematical expression recognition, table structure recognition, and end-to-end semantic entity recognition and pair extraction from document image. Based on these observations, we affirm the necessity and continued research value of specialized OCR models. In general, despite its versatility in handling diverse OCR tasks, GPT-4V does not outperform existing state-of-the-art OCR models. How to fully utilize pre-trained general-purpose LMMs such as GPT-4V for OCR downstream tasks remains an open problem. The study offers a critical reference for future research in OCR with LMMs. Evaluation pipeline and results are available at https://github.com/SCUT-DLVCLab/GPT-4V_OCR.