 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeURaG: Unified Retrieval and Generation in Multimodal LLMs for Efficient Long Document Understanding
Nov 13, 2025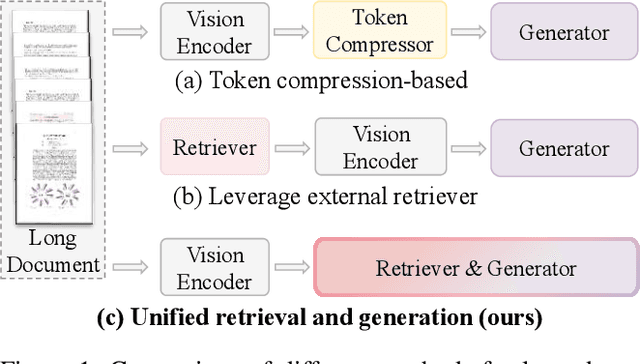
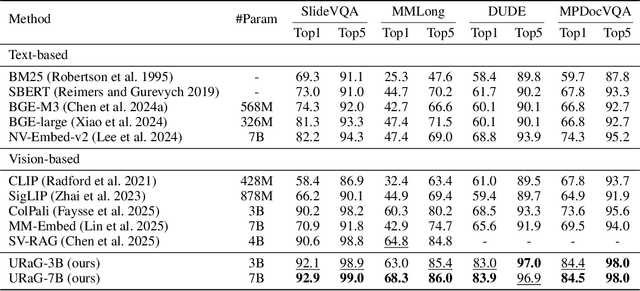
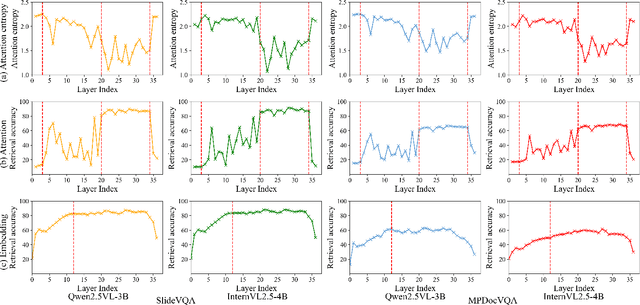
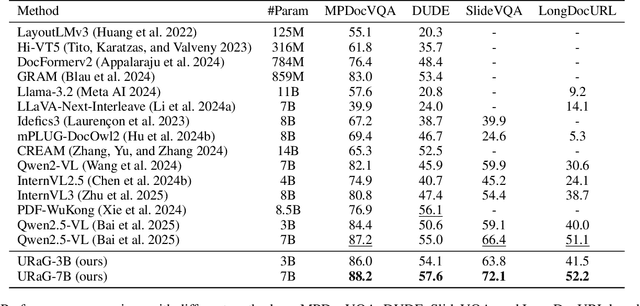
Recent multimodal large language models (MLLMs) still struggle with long document understanding due to two fundamental challenges: information interference from abundant irrelevant content, and the quadratic computational cost of Transformer-based architectures. Existing approaches primarily fall into two categories: token compression, which sacrifices fine-grained details; and introducing external retrievers, which increase system complexity and prevent end-to-end optimization. To address these issues, we conduct an in-depth analysis and observe that MLLMs exhibit a human-like coarse-to-fine reasoning pattern: early Transformer layers attend broadly across the document, while deeper layers focus on relevant evidence pages. Motivated by this insight, we posit that the inherent evidence localization capabilities of MLLMs can be explicitly leveraged to perform retrieval during the reasoning process, facilitating efficient long document understanding. To this end, we propose URaG, a simple-yet-effective framework that Unifies Retrieval and Generation within a single MLLM. URaG introduces a lightweight cross-modal retrieval module that converts the early Transformer layers into an efficient evidence selector, identifying and preserving the most relevant pages while discarding irrelevant content. This design enables the deeper layers to concentrate computational resources on pertinent information, improving both accuracy and efficiency. Extensive experiments demonstrate that URaG achieves state-of-the-art performance while reducing computational overhead by 44-56%. The code is available at https://github.com/shi-yx/URaG.
MegaHan97K: A Large-Scale Dataset for Mega-Category Chinese Character Recognition with over 97K Categories
Jun 05, 2025Foundational to the Chinese language and culture, Chinese characters encompass extraordinarily extensive and ever-expanding categories, with the latest Chinese GB18030-2022 standard containing 87,887 categories. The accurate recognition of this vast number of characters, termed mega-category recognition, presents a formidable yet crucial challenge for cultural heritage preservation and digital applications. Despite significant advances in Optical Character Recognition (OCR), mega-category recognition remains unexplored due to the absence of comprehensive datasets, with the largest existing dataset containing merely 16,151 categories. To bridge this critical gap, we introduce MegaHan97K, a mega-category, large-scale dataset covering an unprecedented 97,455 categories of Chinese characters. Our work offers three major contributions: (1) MegaHan97K is the first dataset to fully support the latest GB18030-2022 standard, providing at least six times more categories than existing datasets; (2) It effectively addresses the long-tail distribution problem by providing balanced samples across all categories through its three distinct subsets: handwritten, historical and synthetic subsets; (3) Comprehensive benchmarking experiments reveal new challenges in mega-category scenarios, including increased storage demands, morphologically similar character recognition, and zero-shot learning difficulties, while also unlocking substantial opportunities for future research. To the best of our knowledge, the MetaHan97K is likely the dataset with the largest classes not only in the field of OCR but may also in the broader domain of pattern recognition. The dataset is available at https://github.com/SCUT-DLVCLab/MegaHan97K.
OCR-Reasoning Benchmark: Unveiling the True Capabilities of MLLMs in Complex Text-Rich Image Reasoning
May 22, 2025Recent advancements in multimodal slow-thinking systems have demonstrated remarkable performance across diverse visual reasoning tasks. However, their capabilities in text-rich image reasoning tasks remain understudied due to the lack of a systematic benchmark. To address this gap, we propose OCR-Reasoning, a comprehensive benchmark designed to systematically assess Multimodal Large Language Models on text-rich image reasoning tasks. The benchmark comprises 1,069 human-annotated examples spanning 6 core reasoning abilities and 18 practical reasoning tasks in text-rich visual scenarios. Furthermore, unlike other text-rich image understanding benchmarks that only annotate the final answers, OCR-Reasoning also annotates the reasoning process simultaneously. With the annotated reasoning process and the final answers, OCR-Reasoning evaluates not only the final answers generated by models but also their reasoning processes, enabling a holistic analysis of their problem-solving abilities. Leveraging this benchmark, we conducted a comprehensive evaluation of state-of-the-art MLLMs. Our results demonstrate the limitations of existing methodologies. Notably, even state-of-the-art MLLMs exhibit substantial difficulties, with none achieving accuracy surpassing 50\% across OCR-Reasoning, indicating that the challenges of text-rich image reasoning are an urgent issue to be addressed. The benchmark and evaluation scripts are available at https://github.com/SCUT-DLVCLab/OCR-Reasoning.
Predicting the Original Appearance of Damaged Historical Documents
Dec 16, 2024



Historical documents encompass a wealth of cultural treasures but suffer from severe damages including character missing, paper damage, and ink erosion over time. However, existing document processing methods primarily focus on binarization, enhancement, etc., neglecting the repair of these damages. To this end, we present a new task, termed Historical Document Repair (HDR), which aims to predict the original appearance of damaged historical documents. To fill the gap in this field, we propose a large-scale dataset HDR28K and a diffusion-based network DiffHDR for historical document repair. Specifically, HDR28K contains 28,552 damaged-repaired image pairs with character-level annotations and multi-style degradations. Moreover, DiffHDR augments the vanilla diffusion framework with semantic and spatial information and a meticulously designed character perceptual loss for contextual and visual coherence. Experimental results demonstrate that the proposed DiffHDR trained using HDR28K significantly surpasses existing approaches and exhibits remarkable performance in handling real damaged documents. Notably, DiffHDR can also be extended to document editing and text block generation, showcasing its high flexibility and generalization capacity. We believe this study could pioneer a new direction of document processing and contribute to the inheritance of invaluable cultures and civilizations. The dataset and code is available at https://github.com/yeungchenwa/HDR.
* Accepted to AAAI 2025; Github Page: https://github.com/yeungchenwa/HDR
TongGu: Mastering Classical Chinese Understanding with Knowledge-Grounded Large Language Models
Jul 04, 2024Classical Chinese is a gateway to the rich heritage and wisdom of ancient China, yet its complexities pose formidable comprehension barriers for most modern people without specialized knowledge. While Large Language Models (LLMs) have shown remarkable capabilities in Natural Language Processing (NLP), they struggle with Classical Chinese Understanding (CCU), especially in data-demanding and knowledge-intensive tasks. In response to this dilemma, we propose \textbf{TongGu} (mean understanding ancient and modern), the first CCU-specific LLM, underpinned by three core contributions. First, we construct a two-stage instruction-tuning dataset ACCN-INS derived from rich classical Chinese corpora, aiming to unlock the full CCU potential of LLMs. Second, we propose Redundancy-Aware Tuning (RAT) to prevent catastrophic forgetting, enabling TongGu to acquire new capabilities while preserving its foundational knowledge. Third, we present a CCU Retrieval-Augmented Generation (CCU-RAG) technique to reduce hallucinations based on knowledge-grounding. Extensive experiments across 24 diverse CCU tasks validate TongGu's superior ability, underscoring the effectiveness of RAT and CCU-RAG. The model and dataset will be public available.
C$^{3}$Bench: A Comprehensive Classical Chinese Understanding Benchmark for Large Language Models
May 28, 2024Classical Chinese Understanding (CCU) holds significant value in preserving and exploration of the outstanding traditional Chinese culture. Recently, researchers have attempted to leverage the potential of Large Language Models (LLMs) for CCU by capitalizing on their remarkable comprehension and semantic capabilities. However, no comprehensive benchmark is available to assess the CCU capabilities of LLMs. To fill this gap, this paper introduces C$^{3}$bench, a Comprehensive Classical Chinese understanding benchmark, which comprises 50,000 text pairs for five primary CCU tasks, including classification, retrieval, named entity recognition, punctuation, and translation. Furthermore, the data in C$^{3}$bench originates from ten different domains, covering most of the categories in classical Chinese. Leveraging the proposed C$^{3}$bench, we extensively evaluate the quantitative performance of 15 representative LLMs on all five CCU tasks. Our results not only establish a public leaderboard of LLMs' CCU capabilities but also gain some findings. Specifically, existing LLMs are struggle with CCU tasks and still inferior to supervised models. Additionally, the results indicate that CCU is a task that requires special attention. We believe this study could provide a standard benchmark, comprehensive baselines, and valuable insights for the future advancement of LLM-based CCU research. The evaluation pipeline and dataset are available at \url{https://github.com/SCUT-DLVCLab/C3bench}.
UPOCR: Towards Unified Pixel-Level OCR Interface
Dec 05, 2023In recent years, the optical character recognition (OCR) field has been proliferating with plentiful cutting-edge approaches for a wide spectrum of tasks. However, these approaches are task-specifically designed with divergent paradigms, architectures, and training strategies, which significantly increases the complexity of research and maintenance and hinders the fast deployment in applications. To this end, we propose UPOCR, a simple-yet-effective generalist model for Unified Pixel-level OCR interface. Specifically, the UPOCR unifies the paradigm of diverse OCR tasks as image-to-image transformation and the architecture as a vision Transformer (ViT)-based encoder-decoder. Learnable task prompts are introduced to push the general feature representations extracted by the encoder toward task-specific spaces, endowing the decoder with task awareness. Moreover, the model training is uniformly aimed at minimizing the discrepancy between the generated and ground-truth images regardless of the inhomogeneity among tasks. Experiments are conducted on three pixel-level OCR tasks including text removal, text segmentation, and tampered text detection. Without bells and whistles, the experimental results showcase that the proposed method can simultaneously achieve state-of-the-art performance on three tasks with a unified single model, which provides valuable strategies and insights for future research on generalist OCR models. Code will be publicly available.
Exploring OCR Capabilities of GPT-4V : A Quantitative and In-depth Evaluation
Oct 29, 2023



This paper presents a comprehensive evaluation of the Optical Character Recognition (OCR) capabilities of the recently released GPT-4V(ision), a Large Multimodal Model (LMM). We assess the model's performance across a range of OCR tasks, including scene text recognition, handwritten text recognition, handwritten mathematical expression recognition, table structure recognition, and information extraction from visually-rich document. The evaluation reveals that GPT-4V performs well in recognizing and understanding Latin contents, but struggles with multilingual scenarios and complex tasks. Specifically, it showed limitations when dealing with non-Latin languages and complex tasks such as handwriting mathematical expression recognition, table structure recognition, and end-to-end semantic entity recognition and pair extraction from document image. Based on these observations, we affirm the necessity and continued research value of specialized OCR models. In general, despite its versatility in handling diverse OCR tasks, GPT-4V does not outperform existing state-of-the-art OCR models. How to fully utilize pre-trained general-purpose LMMs such as GPT-4V for OCR downstream tasks remains an open problem. The study offers a critical reference for future research in OCR with LMMs. Evaluation pipeline and results are available at https://github.com/SCUT-DLVCLab/GPT-4V_OCR.