 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Robust Rubric Rewards
May 28, 2026While Reinforcement Learning with Verifiable Rewards (RLVR) is effective for deterministically checkable tasks, many vision-language tasks are partially verifiable, demanding multi-criteria supervision (e.g., perceptual details, reasoning steps, and constraints). Rubrics provide a natural interface for this fine-grained supervision, but their effectiveness depends on the execution accuracy during online RL. We propose Reinforcement Learning with Robust Rubric Rewards ($\text{RLR}^3$), extending RLVR from task-level verification to criterion-level verification. $\text{RLR}^3$ routes instance-specific rubrics through two execution paths: an LLM-as-an-extractor paired with a deterministic verifier, or an LLM-as-a-Judge for non-verifiable criteria. To ensure faithful scoring, $\text{RLR}^3$ introduce a minimal exposure strategy that masks ground truths from extractors and images from judges. Furthermore, $\text{RLR}^3$ employs hierarchical aggregation to prioritize essential criteria over additional criteria, and mitigates score saturation within rollout groups. Evaluated on Qwen3-VL-30B-A3B across 15 benchmarks, $\text{RLR}^3$ consistently outperforms RLVR, yielding a 4.7-point improvement over the base model and exceeding the official instruct-to-thinking model gap. Controlled audits confirm our deterministic verification and minimal exposure significantly reduce exploitable false positives.
Visual Preference Optimization with Rubric Rewards
Apr 14, 2026The effectiveness of Direct Preference Optimization (DPO) depends on preference data that reflect the quality differences that matter in multimodal tasks. Existing pipelines often rely on off-policy perturbations or coarse outcome-based signals, which are not well suited to fine-grained visual reasoning. We propose rDPO, a preference optimization framework based on instance-specific rubrics. For each image-instruction pair, we create a checklist-style rubric of essential and additional criteria to score responses from any possible policies. The instruction-rubric pool is built offline and reused during the construction of on-policy data. On public reward modeling benchmarks, rubric-based prompting massively improves a 30B-A3B judge and brings it close to GPT-5.4. On public downstream benchmarks, rubric-based filtering raises the macro average to 82.69, whereas outcome-based filtering drops it to 75.82 from 81.14. When evaluating scalability on a comprehensive benchmark, rDPO achieves 61.01, markedly outperforming the style-constrained baseline (52.36) and surpassing the 59.48 base model. Together, these results show that visual preference optimization benefits from combining on-policy data construction with instance-specific criterion-level feedback.
URaG: Unified Retrieval and Generation in Multimodal LLMs for Efficient Long Document Understanding
Nov 13, 2025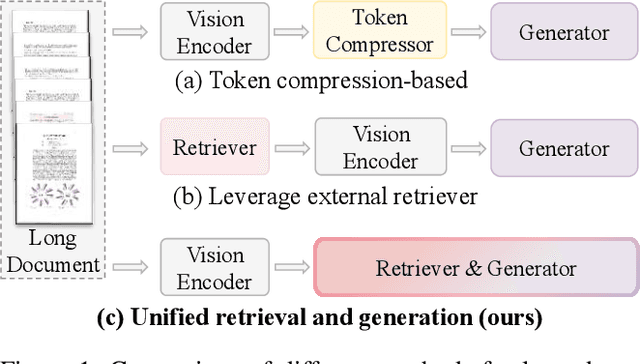
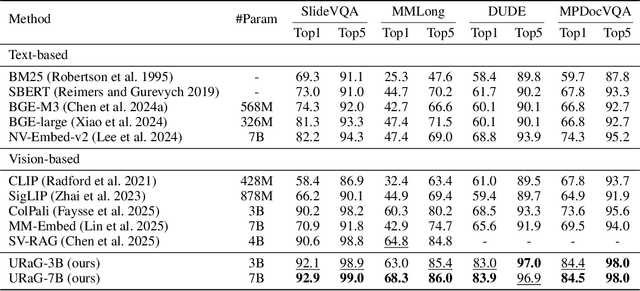
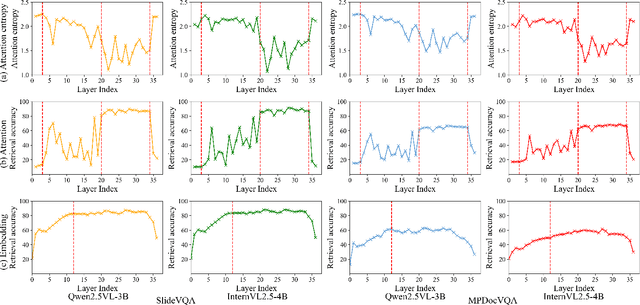
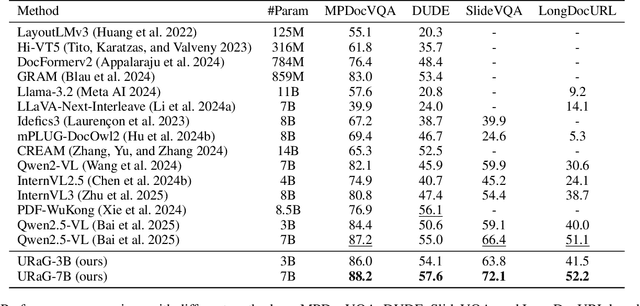
Recent multimodal large language models (MLLMs) still struggle with long document understanding due to two fundamental challenges: information interference from abundant irrelevant content, and the quadratic computational cost of Transformer-based architectures. Existing approaches primarily fall into two categories: token compression, which sacrifices fine-grained details; and introducing external retrievers, which increase system complexity and prevent end-to-end optimization. To address these issues, we conduct an in-depth analysis and observe that MLLMs exhibit a human-like coarse-to-fine reasoning pattern: early Transformer layers attend broadly across the document, while deeper layers focus on relevant evidence pages. Motivated by this insight, we posit that the inherent evidence localization capabilities of MLLMs can be explicitly leveraged to perform retrieval during the reasoning process, facilitating efficient long document understanding. To this end, we propose URaG, a simple-yet-effective framework that Unifies Retrieval and Generation within a single MLLM. URaG introduces a lightweight cross-modal retrieval module that converts the early Transformer layers into an efficient evidence selector, identifying and preserving the most relevant pages while discarding irrelevant content. This design enables the deeper layers to concentrate computational resources on pertinent information, improving both accuracy and efficiency. Extensive experiments demonstrate that URaG achieves state-of-the-art performance while reducing computational overhead by 44-56%. The code is available at https://github.com/shi-yx/URaG.
OCR-Reasoning Benchmark: Unveiling the True Capabilities of MLLMs in Complex Text-Rich Image Reasoning
May 22, 2025Recent advancements in multimodal slow-thinking systems have demonstrated remarkable performance across diverse visual reasoning tasks. However, their capabilities in text-rich image reasoning tasks remain understudied due to the lack of a systematic benchmark. To address this gap, we propose OCR-Reasoning, a comprehensive benchmark designed to systematically assess Multimodal Large Language Models on text-rich image reasoning tasks. The benchmark comprises 1,069 human-annotated examples spanning 6 core reasoning abilities and 18 practical reasoning tasks in text-rich visual scenarios. Furthermore, unlike other text-rich image understanding benchmarks that only annotate the final answers, OCR-Reasoning also annotates the reasoning process simultaneously. With the annotated reasoning process and the final answers, OCR-Reasoning evaluates not only the final answers generated by models but also their reasoning processes, enabling a holistic analysis of their problem-solving abilities. Leveraging this benchmark, we conducted a comprehensive evaluation of state-of-the-art MLLMs. Our results demonstrate the limitations of existing methodologies. Notably, even state-of-the-art MLLMs exhibit substantial difficulties, with none achieving accuracy surpassing 50\% across OCR-Reasoning, indicating that the challenges of text-rich image reasoning are an urgent issue to be addressed. The benchmark and evaluation scripts are available at https://github.com/SCUT-DLVCLab/OCR-Reasoning.
Beyond Token Compression: A Training-Free Reduction Framework for Efficient Visual Processing in MLLMs
Jan 31, 2025



Multimodal Large Language Models (MLLMs) are typically based on decoder-only or cross-attention architectures. While decoder-only MLLMs outperform their cross-attention counterparts, they require significantly higher computational resources due to extensive self-attention and FFN operations on visual tokens. This raises the question: can we eliminate these expensive operations while maintaining the performance? To this end, we present a novel analysis framework to investigate the necessity of these costly operations in decoder-only MLLMs. Our framework introduces two key innovations: (1) Hollow Attention, which limits visual token interactions to local attention while maintaining visual-text associations, and (2) Probe-Activated Dynamic FFN, which selectively activates FFN parameters for visual tokens. Both methods do not require fine-tuning, which significantly enhances analysis efficiency. To assess the impact of applying these reductions across different proportions of layers, we developed a greedy search method that significantly narrows the search space. Experiments on state-of-the-art MLLMs reveal that applying our reductions to approximately half of the layers not only maintains but sometimes improves model performance, indicating significant computational redundancy in current architectures. Additionally, our method is orthogonal to existing token compression techniques, allowing for further combination to achieve greater computational reduction. Our findings may provide valuable insights for the design of more efficient future MLLMs. Our code will be publicly available at https://github.com/L-Hugh/Beyond-Token-Compression.
Predicting the Original Appearance of Damaged Historical Documents
Dec 16, 2024



Historical documents encompass a wealth of cultural treasures but suffer from severe damages including character missing, paper damage, and ink erosion over time. However, existing document processing methods primarily focus on binarization, enhancement, etc., neglecting the repair of these damages. To this end, we present a new task, termed Historical Document Repair (HDR), which aims to predict the original appearance of damaged historical documents. To fill the gap in this field, we propose a large-scale dataset HDR28K and a diffusion-based network DiffHDR for historical document repair. Specifically, HDR28K contains 28,552 damaged-repaired image pairs with character-level annotations and multi-style degradations. Moreover, DiffHDR augments the vanilla diffusion framework with semantic and spatial information and a meticulously designed character perceptual loss for contextual and visual coherence. Experimental results demonstrate that the proposed DiffHDR trained using HDR28K significantly surpasses existing approaches and exhibits remarkable performance in handling real damaged documents. Notably, DiffHDR can also be extended to document editing and text block generation, showcasing its high flexibility and generalization capacity. We believe this study could pioneer a new direction of document processing and contribute to the inheritance of invaluable cultures and civilizations. The dataset and code is available at https://github.com/yeungchenwa/HDR.
* Accepted to AAAI 2025; Github Page: https://github.com/yeungchenwa/HDR
TongGu: Mastering Classical Chinese Understanding with Knowledge-Grounded Large Language Models
Jul 04, 2024Classical Chinese is a gateway to the rich heritage and wisdom of ancient China, yet its complexities pose formidable comprehension barriers for most modern people without specialized knowledge. While Large Language Models (LLMs) have shown remarkable capabilities in Natural Language Processing (NLP), they struggle with Classical Chinese Understanding (CCU), especially in data-demanding and knowledge-intensive tasks. In response to this dilemma, we propose \textbf{TongGu} (mean understanding ancient and modern), the first CCU-specific LLM, underpinned by three core contributions. First, we construct a two-stage instruction-tuning dataset ACCN-INS derived from rich classical Chinese corpora, aiming to unlock the full CCU potential of LLMs. Second, we propose Redundancy-Aware Tuning (RAT) to prevent catastrophic forgetting, enabling TongGu to acquire new capabilities while preserving its foundational knowledge. Third, we present a CCU Retrieval-Augmented Generation (CCU-RAG) technique to reduce hallucinations based on knowledge-grounding. Extensive experiments across 24 diverse CCU tasks validate TongGu's superior ability, underscoring the effectiveness of RAT and CCU-RAG. The model and dataset will be public available.
C$^{3}$Bench: A Comprehensive Classical Chinese Understanding Benchmark for Large Language Models
May 28, 2024Classical Chinese Understanding (CCU) holds significant value in preserving and exploration of the outstanding traditional Chinese culture. Recently, researchers have attempted to leverage the potential of Large Language Models (LLMs) for CCU by capitalizing on their remarkable comprehension and semantic capabilities. However, no comprehensive benchmark is available to assess the CCU capabilities of LLMs. To fill this gap, this paper introduces C$^{3}$bench, a Comprehensive Classical Chinese understanding benchmark, which comprises 50,000 text pairs for five primary CCU tasks, including classification, retrieval, named entity recognition, punctuation, and translation. Furthermore, the data in C$^{3}$bench originates from ten different domains, covering most of the categories in classical Chinese. Leveraging the proposed C$^{3}$bench, we extensively evaluate the quantitative performance of 15 representative LLMs on all five CCU tasks. Our results not only establish a public leaderboard of LLMs' CCU capabilities but also gain some findings. Specifically, existing LLMs are struggle with CCU tasks and still inferior to supervised models. Additionally, the results indicate that CCU is a task that requires special attention. We believe this study could provide a standard benchmark, comprehensive baselines, and valuable insights for the future advancement of LLM-based CCU research. The evaluation pipeline and dataset are available at \url{https://github.com/SCUT-DLVCLab/C3bench}.
DocRes: A Generalist Model Toward Unifying Document Image Restoration Tasks
May 07, 2024



Document image restoration is a crucial aspect of Document AI systems, as the quality of document images significantly influences the overall performance. Prevailing methods address distinct restoration tasks independently, leading to intricate systems and the incapability to harness the potential synergies of multi-task learning. To overcome this challenge, we propose DocRes, a generalist model that unifies five document image restoration tasks including dewarping, deshadowing, appearance enhancement, deblurring, and binarization. To instruct DocRes to perform various restoration tasks, we propose a novel visual prompt approach called Dynamic Task-Specific Prompt (DTSPrompt). The DTSPrompt for different tasks comprises distinct prior features, which are additional characteristics extracted from the input image. Beyond its role as a cue for task-specific execution, DTSPrompt can also serve as supplementary information to enhance the model's performance. Moreover, DTSPrompt is more flexible than prior visual prompt approaches as it can be seamlessly applied and adapted to inputs with high and variable resolutions. Experimental results demonstrate that DocRes achieves competitive or superior performance compared to existing state-of-the-art task-specific models. This underscores the potential of DocRes across a broader spectrum of document image restoration tasks. The source code is publicly available at https://github.com/ZZZHANG-jx/DocRes
HierCode: A Lightweight Hierarchical Codebook for Zero-shot Chinese Text Recognition
Mar 20, 2024

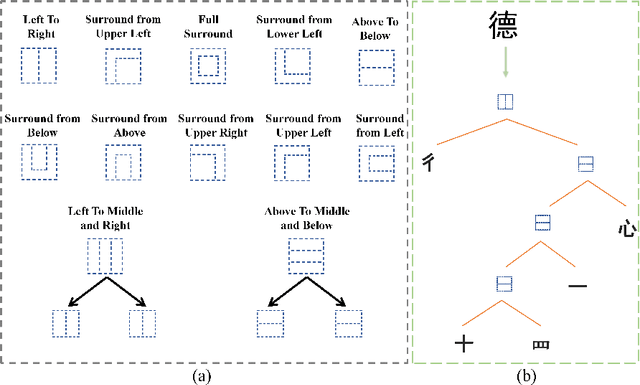

Text recognition, especially for complex scripts like Chinese, faces unique challenges due to its intricate character structures and vast vocabulary. Traditional one-hot encoding methods struggle with the representation of hierarchical radicals, recognition of Out-Of-Vocabulary (OOV) characters, and on-device deployment due to their computational intensity. To address these challenges, we propose HierCode, a novel and lightweight codebook that exploits the innate hierarchical nature of Chinese characters. HierCode employs a multi-hot encoding strategy, leveraging hierarchical binary tree encoding and prototype learning to create distinctive, informative representations for each character. This approach not only facilitates zero-shot recognition of OOV characters by utilizing shared radicals and structures but also excels in line-level recognition tasks by computing similarity with visual features, a notable advantage over existing methods. Extensive experiments across diverse benchmarks, including handwritten, scene, document, web, and ancient text, have showcased HierCode's superiority for both conventional and zero-shot Chinese character or text recognition, exhibiting state-of-the-art performance with significantly fewer parameters and fast inference speed.