 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiSCo: Diffusion Sequence Copilots for Shared Autonomy
Mar 24, 2026Shared autonomy combines human user and AI copilot actions to control complex systems such as robotic arms. When a task is challenging, requires high dimensional control, or is subject to corruption, shared autonomy can significantly increase task performance by using a trained copilot to effectively correct user actions in a manner consistent with the user's goals. To significantly improve the performance of shared autonomy, we introduce Diffusion Sequence Copilots (DiSCo): a method of shared autonomy with diffusion policy that plans action sequences consistent with past user actions. DiSCo seeds and inpaints the diffusion process with user-provided actions with hyperparameters to balance conformity to expert actions, alignment with user intent, and perceived responsiveness. We demonstrate that DiSCo substantially improves task performance in simulated driving and robotic arm tasks. Project website: https://sites.google.com/view/disco-shared-autonomy/
Predictive Preference Learning from Human Interventions
Oct 02, 2025Learning from human involvement aims to incorporate the human subject to monitor and correct agent behavior errors. Although most interactive imitation learning methods focus on correcting the agent's action at the current state, they do not adjust its actions in future states, which may be potentially more hazardous. To address this, we introduce Predictive Preference Learning from Human Interventions (PPL), which leverages the implicit preference signals contained in human interventions to inform predictions of future rollouts. The key idea of PPL is to bootstrap each human intervention into L future time steps, called the preference horizon, with the assumption that the agent follows the same action and the human makes the same intervention in the preference horizon. By applying preference optimization on these future states, expert corrections are propagated into the safety-critical regions where the agent is expected to explore, significantly improving learning efficiency and reducing human demonstrations needed. We evaluate our approach with experiments on both autonomous driving and robotic manipulation benchmarks and demonstrate its efficiency and generality. Our theoretical analysis further shows that selecting an appropriate preference horizon L balances coverage of risky states with label correctness, thereby bounding the algorithmic optimality gap. Demo and code are available at: https://metadriverse.github.io/ppl
Adv-BMT: Bidirectional Motion Transformer for Safety-Critical Traffic Scenario Generation
Jun 11, 2025Scenario-based testing is essential for validating the performance of autonomous driving (AD) systems. However, such testing is limited by the scarcity of long-tailed, safety-critical scenarios in existing datasets collected in the real world. To tackle the data issue, we propose the Adv-BMT framework, which augments real-world scenarios with diverse and realistic adversarial interactions. The core component of Adv-BMT is a bidirectional motion transformer (BMT) model to perform inverse traffic motion predictions, which takes agent information in the last time step of the scenario as input, and reconstruct the traffic in the inverse of chronological order until the initial time step. The Adv-BMT framework is a two-staged pipeline: it first conducts adversarial initializations and then inverse motion predictions. Different from previous work, we do not need any collision data for pretraining, and are able to generate realistic and diverse collision interactions. Our experimental results validate the quality of generated collision scenarios by Adv-BMT: training in our augmented dataset would reduce episode collision rates by 20\% compared to previous work.
Robot-Gated Interactive Imitation Learning with Adaptive Intervention Mechanism
Jun 10, 2025Interactive Imitation Learning (IIL) allows agents to acquire desired behaviors through human interventions, but current methods impose high cognitive demands on human supervisors. We propose the Adaptive Intervention Mechanism (AIM), a novel robot-gated IIL algorithm that learns an adaptive criterion for requesting human demonstrations. AIM utilizes a proxy Q-function to mimic the human intervention rule and adjusts intervention requests based on the alignment between agent and human actions. By assigning high Q-values when the agent deviates from the expert and decreasing these values as the agent becomes proficient, the proxy Q-function enables the agent to assess the real-time alignment with the expert and request assistance when needed. Our expert-in-the-loop experiments reveal that AIM significantly reduces expert monitoring efforts in both continuous and discrete control tasks. Compared to the uncertainty-based baseline Thrifty-DAgger, our method achieves a 40% improvement in terms of human take-over cost and learning efficiency. Furthermore, AIM effectively identifies safety-critical states for expert assistance, thereby collecting higher-quality expert demonstrations and reducing overall expert data and environment interactions needed. Code and demo video are available at https://github.com/metadriverse/AIM.
Data-Efficient Learning from Human Interventions for Mobile Robots
Mar 06, 2025



Mobile robots are essential in applications such as autonomous delivery and hospitality services. Applying learning-based methods to address mobile robot tasks has gained popularity due to its robustness and generalizability. Traditional methods such as Imitation Learning (IL) and Reinforcement Learning (RL) offer adaptability but require large datasets, carefully crafted reward functions, and face sim-to-real gaps, making them challenging for efficient and safe real-world deployment. We propose an online human-in-the-loop learning method PVP4Real that combines IL and RL to address these issues. PVP4Real enables efficient real-time policy learning from online human intervention and demonstration, without reward or any pretraining, significantly improving data efficiency and training safety. We validate our method by training two different robots -- a legged quadruped, and a wheeled delivery robot -- in two mobile robot tasks, one of which even uses raw RGBD image as observation. The training finishes within 15 minutes. Our experiments show the promising future of human-in-the-loop learning in addressing the data efficiency issue in real-world robotic tasks. More information is available at: https://metadriverse.github.io/pvp4real/
Learning from Active Human Involvement through Proxy Value Propagation
Feb 05, 2025Learning from active human involvement enables the human subject to actively intervene and demonstrate to the AI agent during training. The interaction and corrective feedback from human brings safety and AI alignment to the learning process. In this work, we propose a new reward-free active human involvement method called Proxy Value Propagation for policy optimization. Our key insight is that a proxy value function can be designed to express human intents, wherein state-action pairs in the human demonstration are labeled with high values, while those agents' actions that are intervened receive low values. Through the TD-learning framework, labeled values of demonstrated state-action pairs are further propagated to other unlabeled data generated from agents' exploration. The proxy value function thus induces a policy that faithfully emulates human behaviors. Human-in-the-loop experiments show the generality and efficiency of our method. With minimal modification to existing reinforcement learning algorithms, our method can learn to solve continuous and discrete control tasks with various human control devices, including the challenging task of driving in Grand Theft Auto V. Demo video and code are available at: https://metadriverse.github.io/pvp
Embodied Scene Understanding for Vision Language Models via MetaVQA
Jan 15, 2025



Vision Language Models (VLMs) demonstrate significant potential as embodied AI agents for various mobility applications. However, a standardized, closed-loop benchmark for evaluating their spatial reasoning and sequential decision-making capabilities is lacking. To address this, we present MetaVQA: a comprehensive benchmark designed to assess and enhance VLMs' understanding of spatial relationships and scene dynamics through Visual Question Answering (VQA) and closed-loop simulations. MetaVQA leverages Set-of-Mark prompting and top-down view ground-truth annotations from nuScenes and Waymo datasets to automatically generate extensive question-answer pairs based on diverse real-world traffic scenarios, ensuring object-centric and context-rich instructions. Our experiments show that fine-tuning VLMs with the MetaVQA dataset significantly improves their spatial reasoning and embodied scene comprehension in safety-critical simulations, evident not only in improved VQA accuracies but also in emerging safety-aware driving maneuvers. In addition, the learning demonstrates strong transferability from simulation to real-world observation. Code and data will be publicly available at https://metadriverse.github.io/metavqa .
Vid2Sim: Realistic and Interactive Simulation from Video for Urban Navigation
Jan 14, 2025Sim-to-real gap has long posed a significant challenge for robot learning in simulation, preventing the deployment of learned models in the real world. Previous work has primarily focused on domain randomization and system identification to mitigate this gap. However, these methods are often limited by the inherent constraints of the simulation and graphics engines. In this work, we propose Vid2Sim, a novel framework that effectively bridges the sim2real gap through a scalable and cost-efficient real2sim pipeline for neural 3D scene reconstruction and simulation. Given a monocular video as input, Vid2Sim can generate photorealistic and physically interactable 3D simulation environments to enable the reinforcement learning of visual navigation agents in complex urban environments. Extensive experiments demonstrate that Vid2Sim significantly improves the performance of urban navigation in the digital twins and real world by 31.2% and 68.3% in success rate compared with agents trained with prior simulation methods.
Improving Agent Behaviors with RL Fine-tuning for Autonomous Driving
Sep 26, 2024



A major challenge in autonomous vehicle research is modeling agent behaviors, which has critical applications including constructing realistic and reliable simulations for off-board evaluation and forecasting traffic agents motion for onboard planning. While supervised learning has shown success in modeling agents across various domains, these models can suffer from distribution shift when deployed at test-time. In this work, we improve the reliability of agent behaviors by closed-loop fine-tuning of behavior models with reinforcement learning. Our method demonstrates improved overall performance, as well as improved targeted metrics such as collision rate, on the Waymo Open Sim Agents challenge. Additionally, we present a novel policy evaluation benchmark to directly assess the ability of simulated agents to measure the quality of autonomous vehicle planners and demonstrate the effectiveness of our approach on this new benchmark.
SimGen: Simulator-conditioned Driving Scene Generation
Jun 13, 2024
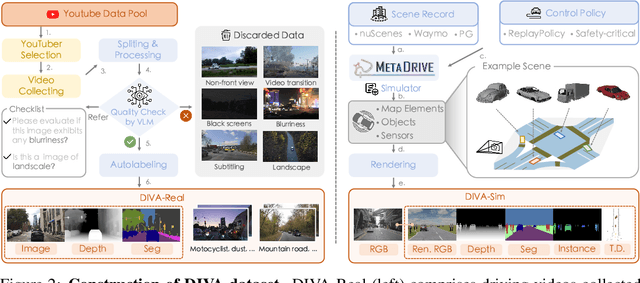
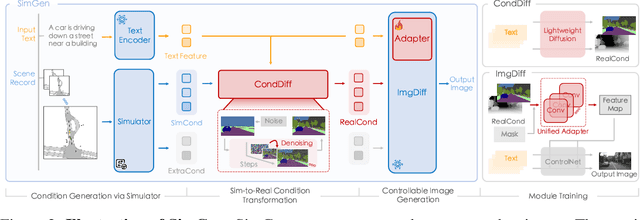

Controllable synthetic data generation can substantially lower the annotation cost of training data in autonomous driving research and development. Prior works use diffusion models to generate driving images conditioned on the 3D object layout. However, those models are trained on small-scale datasets like nuScenes, which lack appearance and layout diversity. Moreover, the trained models can only generate images based on the real-world layout data from the validation set of the same dataset, where overfitting might happen. In this work, we introduce a simulator-conditioned scene generation framework called SimGen that can learn to generate diverse driving scenes by mixing data from the simulator and the real world. It uses a novel cascade diffusion pipeline to address challenging sim-to-real gaps and multi-condition conflicts. A driving video dataset DIVA is collected to enhance the generative diversity of SimGen, which contains over 147.5 hours of real-world driving videos from 73 locations worldwide and simulated driving data from the MetaDrive simulator. SimGen achieves superior generation quality and diversity while preserving controllability based on the text prompt and the layout pulled from a simulator. We further demonstrate the improvements brought by SimGen for synthetic data augmentation on the BEV detection and segmentation task and showcase its capability in safety-critical data generation. Code, data, and models will be made available.