 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Diffusion: Enhancing Image Generation by Unlocking Cross-Sample Collaboration
Dec 11, 2025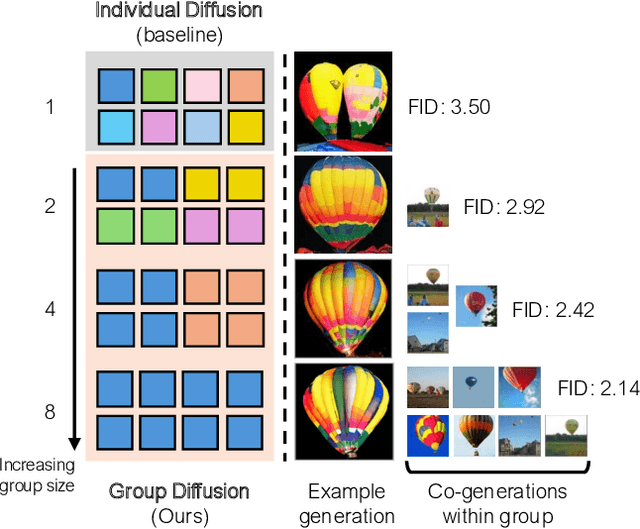
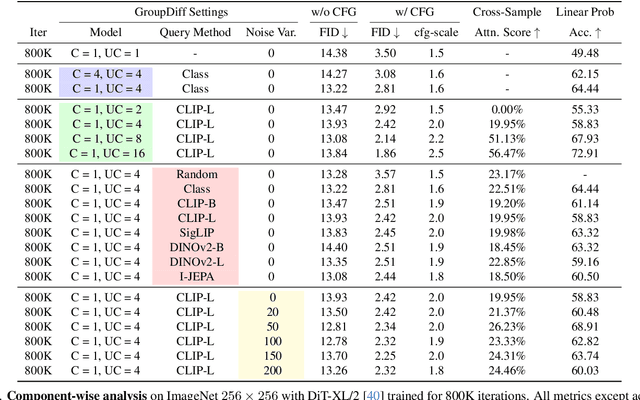

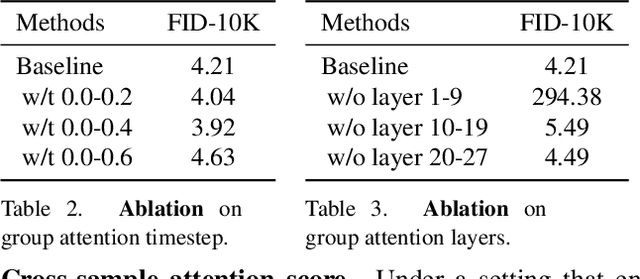
In this work, we explore an untapped signal in diffusion model inference. While all previous methods generate images independently at inference, we instead ask if samples can be generated collaboratively. We propose Group Diffusion, unlocking the attention mechanism to be shared across images, rather than limited to just the patches within an image. This enables images to be jointly denoised at inference time, learning both intra and inter-image correspondence. We observe a clear scaling effect - larger group sizes yield stronger cross-sample attention and better generation quality. Furthermore, we introduce a qualitative measure to capture this behavior and show that its strength closely correlates with FID. Built on standard diffusion transformers, our GroupDiff achieves up to 32.2% FID improvement on ImageNet-256x256. Our work reveals cross-sample inference as an effective, previously unexplored mechanism for generative modeling.
Relational Visual Similarity
Dec 08, 2025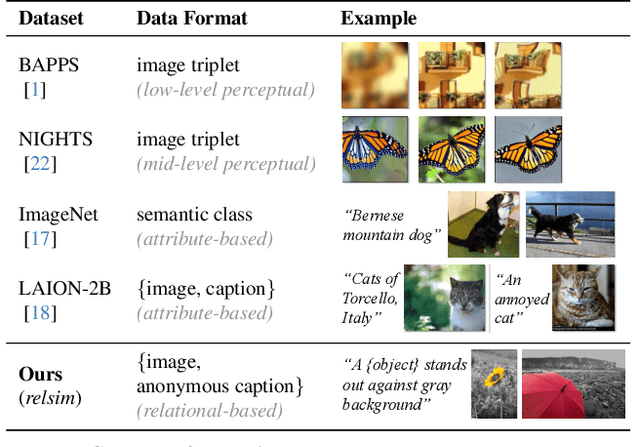
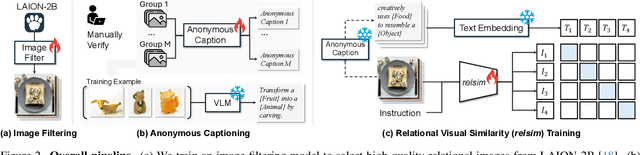
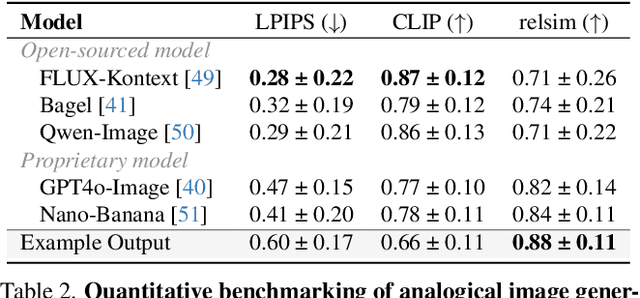

Humans do not just see attribute similarity -- we also see relational similarity. An apple is like a peach because both are reddish fruit, but the Earth is also like a peach: its crust, mantle, and core correspond to the peach's skin, flesh, and pit. This ability to perceive and recognize relational similarity, is arguable by cognitive scientist to be what distinguishes humans from other species. Yet, all widely used visual similarity metrics today (e.g., LPIPS, CLIP, DINO) focus solely on perceptual attribute similarity and fail to capture the rich, often surprising relational similarities that humans perceive. How can we go beyond the visible content of an image to capture its relational properties? How can we bring images with the same relational logic closer together in representation space? To answer these questions, we first formulate relational image similarity as a measurable problem: two images are relationally similar when their internal relations or functions among visual elements correspond, even if their visual attributes differ. We then curate 114k image-caption dataset in which the captions are anonymized -- describing the underlying relational logic of the scene rather than its surface content. Using this dataset, we finetune a Vision-Language model to measure the relational similarity between images. This model serves as the first step toward connecting images by their underlying relational structure rather than their visible appearance. Our study shows that while relational similarity has a lot of real-world applications, existing image similarity models fail to capture it -- revealing a critical gap in visual computing.
Dreamland: Controllable World Creation with Simulator and Generative Models
Jun 09, 2025Large-scale video generative models can synthesize diverse and realistic visual content for dynamic world creation, but they often lack element-wise controllability, hindering their use in editing scenes and training embodied AI agents. We propose Dreamland, a hybrid world generation framework combining the granular control of a physics-based simulator and the photorealistic content output of large-scale pretrained generative models. In particular, we design a layered world abstraction that encodes both pixel-level and object-level semantics and geometry as an intermediate representation to bridge the simulator and the generative model. This approach enhances controllability, minimizes adaptation cost through early alignment with real-world distributions, and supports off-the-shelf use of existing and future pretrained generative models. We further construct a D3Sim dataset to facilitate the training and evaluation of hybrid generation pipelines. Experiments demonstrate that Dreamland outperforms existing baselines with 50.8% improved image quality, 17.9% stronger controllability, and has great potential to enhance embodied agent training. Code and data will be made available.
X-Fusion: Introducing New Modality to Frozen Large Language Models
Apr 29, 2025We propose X-Fusion, a framework that extends pretrained Large Language Models (LLMs) for multimodal tasks while preserving their language capabilities. X-Fusion employs a dual-tower design with modality-specific weights, keeping the LLM's parameters frozen while integrating vision-specific information for both understanding and generation. Our experiments demonstrate that X-Fusion consistently outperforms alternative architectures on both image-to-text and text-to-image tasks. We find that incorporating understanding-focused data improves generation quality, reducing image data noise enhances overall performance, and feature alignment accelerates convergence for smaller models but has minimal impact on larger ones. Our findings provide valuable insights into building efficient unified multimodal models.
SimGen: Simulator-conditioned Driving Scene Generation
Jun 13, 2024
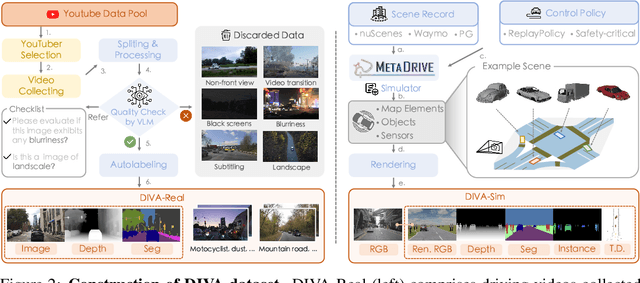
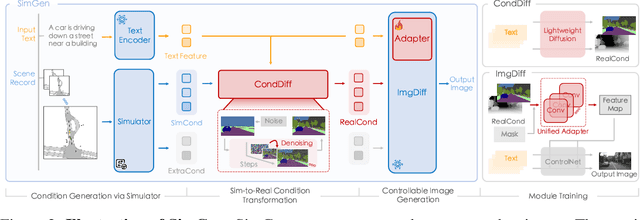

Controllable synthetic data generation can substantially lower the annotation cost of training data in autonomous driving research and development. Prior works use diffusion models to generate driving images conditioned on the 3D object layout. However, those models are trained on small-scale datasets like nuScenes, which lack appearance and layout diversity. Moreover, the trained models can only generate images based on the real-world layout data from the validation set of the same dataset, where overfitting might happen. In this work, we introduce a simulator-conditioned scene generation framework called SimGen that can learn to generate diverse driving scenes by mixing data from the simulator and the real world. It uses a novel cascade diffusion pipeline to address challenging sim-to-real gaps and multi-condition conflicts. A driving video dataset DIVA is collected to enhance the generative diversity of SimGen, which contains over 147.5 hours of real-world driving videos from 73 locations worldwide and simulated driving data from the MetaDrive simulator. SimGen achieves superior generation quality and diversity while preserving controllability based on the text prompt and the layout pulled from a simulator. We further demonstrate the improvements brought by SimGen for synthetic data augmentation on the BEV detection and segmentation task and showcase its capability in safety-critical data generation. Code, data, and models will be made available.
Ctrl-X: Controlling Structure and Appearance for Text-To-Image Generation Without Guidance
Jun 11, 2024



Recent controllable generation approaches such as FreeControl and Diffusion Self-guidance bring fine-grained spatial and appearance control to text-to-image (T2I) diffusion models without training auxiliary modules. However, these methods optimize the latent embedding for each type of score function with longer diffusion steps, making the generation process time-consuming and limiting their flexibility and use. This work presents Ctrl-X, a simple framework for T2I diffusion controlling structure and appearance without additional training or guidance. Ctrl-X designs feed-forward structure control to enable the structure alignment with a structure image and semantic-aware appearance transfer to facilitate the appearance transfer from a user-input image. Extensive qualitative and quantitative experiments illustrate the superior performance of Ctrl-X on various condition inputs and model checkpoints. In particular, Ctrl-X supports novel structure and appearance control with arbitrary condition images of any modality, exhibits superior image quality and appearance transfer compared to existing works, and provides instant plug-and-play functionality to any T2I and text-to-video (T2V) diffusion model. See our project page for an overview of the results: https://genforce.github.io/ctrl-x
SnAG: Scalable and Accurate Video Grounding
Apr 05, 2024Temporal grounding of text descriptions in videos is a central problem in vision-language learning and video understanding. Existing methods often prioritize accuracy over scalability -- they have been optimized for grounding only a few text queries within short videos, and fail to scale up to long videos with hundreds of queries. In this paper, we study the effect of cross-modal fusion on the scalability of video grounding models. Our analysis establishes late fusion as a more cost-effective fusion scheme for long-form videos with many text queries. Moreover, it leads us to a novel, video-centric sampling scheme for efficient training. Based on these findings, we present SnAG, a simple baseline for scalable and accurate video grounding. Without bells and whistles, SnAG is 43% more accurate and 1.5x faster than CONE, a state of the art for long-form video grounding on the challenging MAD dataset, while achieving highly competitive results on short videos.
FreeControl: Training-Free Spatial Control of Any Text-to-Image Diffusion Model with Any Condition
Dec 12, 2023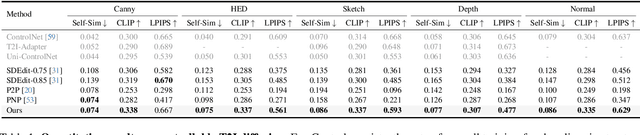
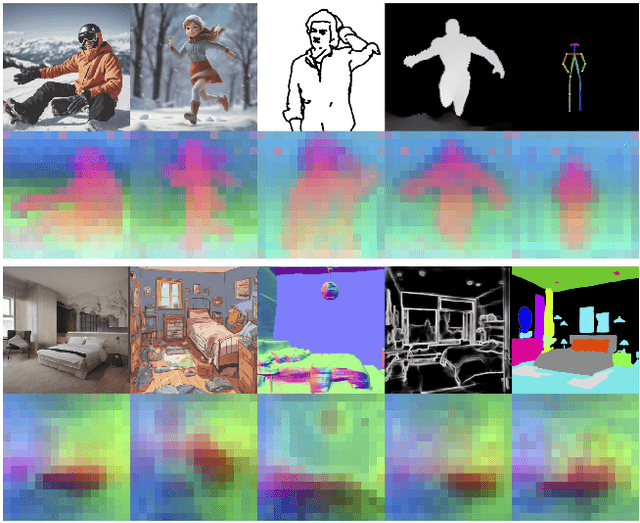
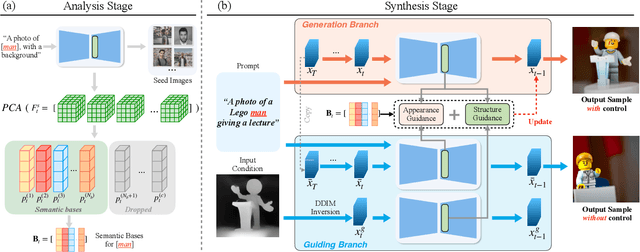

Recent approaches such as ControlNet offer users fine-grained spatial control over text-to-image (T2I) diffusion models. However, auxiliary modules have to be trained for each type of spatial condition, model architecture, and checkpoint, putting them at odds with the diverse intents and preferences a human designer would like to convey to the AI models during the content creation process. In this work, we present FreeControl, a training-free approach for controllable T2I generation that supports multiple conditions, architectures, and checkpoints simultaneously. FreeControl designs structure guidance to facilitate the structure alignment with a guidance image, and appearance guidance to enable the appearance sharing between images generated using the same seed. Extensive qualitative and quantitative experiments demonstrate the superior performance of FreeControl across a variety of pre-trained T2I models. In particular, FreeControl facilitates convenient training-free control over many different architectures and checkpoints, allows the challenging input conditions on which most of the existing training-free methods fail, and achieves competitive synthesis quality with training-based approaches.
Where a Strong Backbone Meets Strong Features -- ActionFormer for Ego4D Moment Queries Challenge
Nov 16, 2022

This report describes our submission to the Ego4D Moment Queries Challenge 2022. Our submission builds on ActionFormer, the state-of-the-art backbone for temporal action localization, and a trio of strong video features from SlowFast, Omnivore and EgoVLP. Our solution is ranked 2nd on the public leaderboard with 21.76% average mAP on the test set, which is nearly three times higher than the official baseline. Further, we obtain 42.54% Recall@1x at tIoU=0.5 on the test set, outperforming the top-ranked solution by a significant margin of 1.41 absolute percentage points. Our code is available at https://github.com/happyharrycn/actionformer_release.
A Simple Transformer-Based Model for Ego4D Natural Language Queries Challenge
Nov 16, 2022This report describes Badgers@UW-Madison, our submission to the Ego4D Natural Language Queries (NLQ) Challenge. Our solution inherits the point-based event representation from our prior work on temporal action localization, and develops a Transformer-based model for video grounding. Further, our solution integrates several strong video features including SlowFast, Omnivore and EgoVLP. Without bells and whistles, our submission based on a single model achieves 12.64% Mean R@1 and is ranked 2nd on the public leaderboard. Meanwhile, our method garners 28.45% (18.03%) R@5 at tIoU=0.3 (0.5), surpassing the top-ranked solution by up to 5.5 absolute percentage points.