 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecovering Parametric Scenes from Very Few Time-of-Flight Pixels
Sep 19, 2025



We aim to recover the geometry of 3D parametric scenes using very few depth measurements from low-cost, commercially available time-of-flight sensors. These sensors offer very low spatial resolution (i.e., a single pixel), but image a wide field-of-view per pixel and capture detailed time-of-flight data in the form of time-resolved photon counts. This time-of-flight data encodes rich scene information and thus enables recovery of simple scenes from sparse measurements. We investigate the feasibility of using a distributed set of few measurements (e.g., as few as 15 pixels) to recover the geometry of simple parametric scenes with a strong prior, such as estimating the 6D pose of a known object. To achieve this, we design a method that utilizes both feed-forward prediction to infer scene parameters, and differentiable rendering within an analysis-by-synthesis framework to refine the scene parameter estimate. We develop hardware prototypes and demonstrate that our method effectively recovers object pose given an untextured 3D model in both simulations and controlled real-world captures, and show promising initial results for other parametric scenes. We additionally conduct experiments to explore the limits and capabilities of our imaging solution.
TimeLoc: A Unified End-to-End Framework for Precise Timestamp Localization in Long Videos
Mar 09, 2025Temporal localization in untrimmed videos, which aims to identify specific timestamps, is crucial for video understanding but remains challenging. This task encompasses several subtasks, including temporal action localization, temporal video grounding, moment retrieval, and generic event boundary detection. Existing methods in each subfield are typically designed for specific tasks and lack generalizability across domains. In this paper, we propose TimeLoc, a unified end-to-end framework for timestamp localization that can handle multiple tasks. First, our approach employs a simple yet effective one-stage localization model that supports text queries as input and multiple actions as output. Second, we jointly train the video encoder and localization model in an end-to-end manner. To efficiently process long videos, we introduce temporal chunking, enabling the handling of videos with over 30k frames. Third, we find that fine-tuning pre-trained text encoders with a multi-stage training strategy further enhances text-conditioned localization. TimeLoc achieves state-of-the-art results across multiple benchmarks: +1.3% and +1.9% mAP over previous best methods on THUMOS14 and EPIC-Kitchens-100, +1.1% on Kinetics-GEBD, +2.94% mAP on QVHighlights, and significant improvements in temporal video grounding (+11.5% on TACoS and +6.7% on Charades-STA under R1@0.5). Our code and checkpoints will be released at https://github.com/sming256/TimeLoc.
Political-LLM: Large Language Models in Political Science
Dec 09, 2024



In recent years, large language models (LLMs) have been widely adopted in political science tasks such as election prediction, sentiment analysis, policy impact assessment, and misinformation detection. Meanwhile, the need to systematically understand how LLMs can further revolutionize the field also becomes urgent. In this work, we--a multidisciplinary team of researchers spanning computer science and political science--present the first principled framework termed Political-LLM to advance the comprehensive understanding of integrating LLMs into computational political science. Specifically, we first introduce a fundamental taxonomy classifying the existing explorations into two perspectives: political science and computational methodologies. In particular, from the political science perspective, we highlight the role of LLMs in automating predictive and generative tasks, simulating behavior dynamics, and improving causal inference through tools like counterfactual generation; from a computational perspective, we introduce advancements in data preparation, fine-tuning, and evaluation methods for LLMs that are tailored to political contexts. We identify key challenges and future directions, emphasizing the development of domain-specific datasets, addressing issues of bias and fairness, incorporating human expertise, and redefining evaluation criteria to align with the unique requirements of computational political science. Political-LLM seeks to serve as a guidebook for researchers to foster an informed, ethical, and impactful use of Artificial Intelligence in political science. Our online resource is available at: http://political-llm.org/.
Harnessing Temporal Causality for Advanced Temporal Action Detection
Jul 26, 2024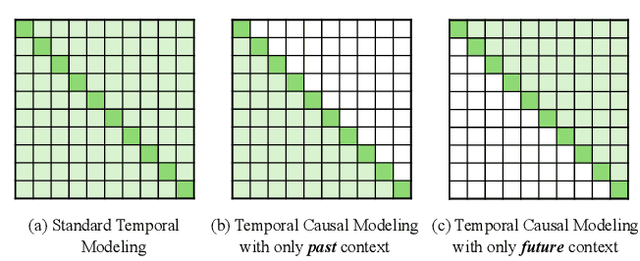

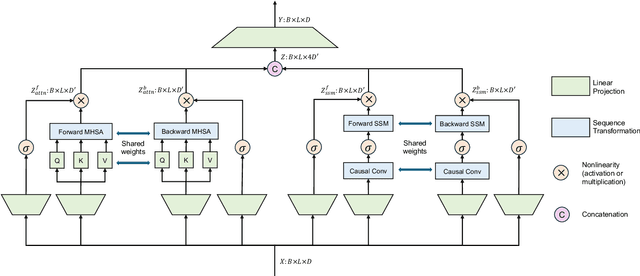

As a fundamental task in long-form video understanding, temporal action detection (TAD) aims to capture inherent temporal relations in untrimmed videos and identify candidate actions with precise boundaries. Over the years, various networks, including convolutions, graphs, and transformers, have been explored for effective temporal modeling for TAD. However, these modules typically treat past and future information equally, overlooking the crucial fact that changes in action boundaries are essentially causal events. Inspired by this insight, we propose leveraging the temporal causality of actions to enhance TAD representation by restricting the model's access to only past or future context. We introduce CausalTAD, which combines causal attention and causal Mamba to achieve state-of-the-art performance on multiple benchmarks. Notably, with CausalTAD, we ranked 1st in the Action Recognition, Action Detection, and Audio-Based Interaction Detection tracks at the EPIC-Kitchens Challenge 2024, as well as 1st in the Moment Queries track at the Ego4D Challenge 2024. Our code is available at https://github.com/sming256/OpenTAD/.
Ctrl-X: Controlling Structure and Appearance for Text-To-Image Generation Without Guidance
Jun 11, 2024



Recent controllable generation approaches such as FreeControl and Diffusion Self-guidance bring fine-grained spatial and appearance control to text-to-image (T2I) diffusion models without training auxiliary modules. However, these methods optimize the latent embedding for each type of score function with longer diffusion steps, making the generation process time-consuming and limiting their flexibility and use. This work presents Ctrl-X, a simple framework for T2I diffusion controlling structure and appearance without additional training or guidance. Ctrl-X designs feed-forward structure control to enable the structure alignment with a structure image and semantic-aware appearance transfer to facilitate the appearance transfer from a user-input image. Extensive qualitative and quantitative experiments illustrate the superior performance of Ctrl-X on various condition inputs and model checkpoints. In particular, Ctrl-X supports novel structure and appearance control with arbitrary condition images of any modality, exhibits superior image quality and appearance transfer compared to existing works, and provides instant plug-and-play functionality to any T2I and text-to-video (T2V) diffusion model. See our project page for an overview of the results: https://genforce.github.io/ctrl-x
SnAG: Scalable and Accurate Video Grounding
Apr 05, 2024Temporal grounding of text descriptions in videos is a central problem in vision-language learning and video understanding. Existing methods often prioritize accuracy over scalability -- they have been optimized for grounding only a few text queries within short videos, and fail to scale up to long videos with hundreds of queries. In this paper, we study the effect of cross-modal fusion on the scalability of video grounding models. Our analysis establishes late fusion as a more cost-effective fusion scheme for long-form videos with many text queries. Moreover, it leads us to a novel, video-centric sampling scheme for efficient training. Based on these findings, we present SnAG, a simple baseline for scalable and accurate video grounding. Without bells and whistles, SnAG is 43% more accurate and 1.5x faster than CONE, a state of the art for long-form video grounding on the challenging MAD dataset, while achieving highly competitive results on short videos.
Towards 3D Vision with Low-Cost Single-Photon Cameras
Mar 29, 2024We present a method for reconstructing 3D shape of arbitrary Lambertian objects based on measurements by miniature, energy-efficient, low-cost single-photon cameras. These cameras, operating as time resolved image sensors, illuminate the scene with a very fast pulse of diffuse light and record the shape of that pulse as it returns back from the scene at a high temporal resolution. We propose to model this image formation process, account for its non-idealities, and adapt neural rendering to reconstruct 3D geometry from a set of spatially distributed sensors with known poses. We show that our approach can successfully recover complex 3D shapes from simulated data. We further demonstrate 3D object reconstruction from real-world captures, utilizing measurements from a commodity proximity sensor. Our work draws a connection between image-based modeling and active range scanning and is a step towards 3D vision with single-photon cameras.
Towards Few-Shot Adaptation of Foundation Models via Multitask Finetuning
Feb 22, 2024Foundation models have emerged as a powerful tool for many AI problems. Despite the tremendous success of foundation models, effective adaptation to new tasks, particularly those with limited labels, remains an open question and lacks theoretical understanding. An emerging solution with recent success in vision and NLP involves finetuning a foundation model on a selection of relevant tasks, before its adaptation to a target task with limited labeled samples. In this paper, we study the theoretical justification of this multitask finetuning approach. Our theoretical analysis reveals that with a diverse set of related tasks, this multitask finetuning leads to reduced error in the target task, in comparison to directly adapting the same pretrained model. We quantify the relationship between finetuning tasks and target tasks by diversity and consistency metrics, and further propose a practical task selection algorithm. We substantiate our theoretical claims with extensive empirical evidence. Further, we present results affirming our task selection algorithm adeptly chooses related finetuning tasks, providing advantages to the model performance on target tasks. We believe our study shed new light on the effective adaptation of foundation models to new tasks that lack abundant labels. Our code is available at https://github.com/OliverXUZY/Foudation-Model_Multitask.
FreeControl: Training-Free Spatial Control of Any Text-to-Image Diffusion Model with Any Condition
Dec 12, 2023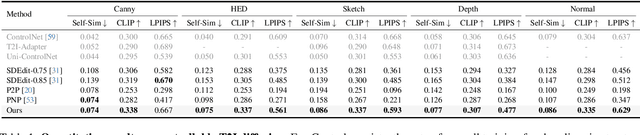
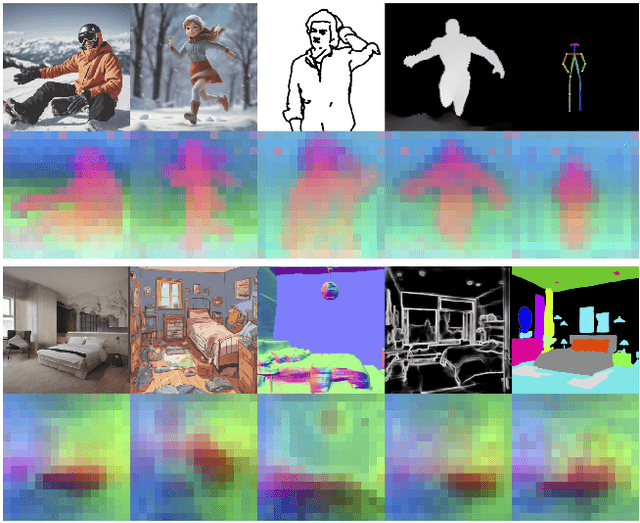
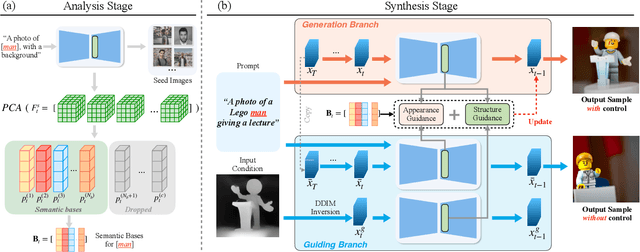

Recent approaches such as ControlNet offer users fine-grained spatial control over text-to-image (T2I) diffusion models. However, auxiliary modules have to be trained for each type of spatial condition, model architecture, and checkpoint, putting them at odds with the diverse intents and preferences a human designer would like to convey to the AI models during the content creation process. In this work, we present FreeControl, a training-free approach for controllable T2I generation that supports multiple conditions, architectures, and checkpoints simultaneously. FreeControl designs structure guidance to facilitate the structure alignment with a guidance image, and appearance guidance to enable the appearance sharing between images generated using the same seed. Extensive qualitative and quantitative experiments demonstrate the superior performance of FreeControl across a variety of pre-trained T2I models. In particular, FreeControl facilitates convenient training-free control over many different architectures and checkpoints, allows the challenging input conditions on which most of the existing training-free methods fail, and achieves competitive synthesis quality with training-based approaches.
Towards 4D Human Video Stylization
Dec 07, 2023We present a first step towards 4D (3D and time) human video stylization, which addresses style transfer, novel view synthesis and human animation within a unified framework. While numerous video stylization methods have been developed, they are often restricted to rendering images in specific viewpoints of the input video, lacking the capability to generalize to novel views and novel poses in dynamic scenes. To overcome these limitations, we leverage Neural Radiance Fields (NeRFs) to represent videos, conducting stylization in the rendered feature space. Our innovative approach involves the simultaneous representation of both the human subject and the surrounding scene using two NeRFs. This dual representation facilitates the animation of human subjects across various poses and novel viewpoints. Specifically, we introduce a novel geometry-guided tri-plane representation, significantly enhancing feature representation robustness compared to direct tri-plane optimization. Following the video reconstruction, stylization is performed within the NeRFs' rendered feature space. Extensive experiments demonstrate that the proposed method strikes a superior balance between stylized textures and temporal coherence, surpassing existing approaches. Furthermore, our framework uniquely extends its capabilities to accommodate novel poses and viewpoints, making it a versatile tool for creative human video stylization.