 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Intellectual Property in Graph-Based Machine Learning as a Service: Attacks and Defenses
Aug 27, 2025Graph-structured data, which captures non-Euclidean relationships and interactions between entities, is growing in scale and complexity. As a result, training state-of-the-art graph machine learning (GML) models have become increasingly resource-intensive, turning these models and data into invaluable Intellectual Property (IP). To address the resource-intensive nature of model training, graph-based Machine-Learning-as-a-Service (GMLaaS) has emerged as an efficient solution by leveraging third-party cloud services for model development and management. However, deploying such models in GMLaaS also exposes them to potential threats from attackers. Specifically, while the APIs within a GMLaaS system provide interfaces for users to query the model and receive outputs, they also allow attackers to exploit and steal model functionalities or sensitive training data, posing severe threats to the safety of these GML models and the underlying graph data. To address these challenges, this survey systematically introduces the first taxonomy of threats and defenses at the level of both GML model and graph-structured data. Such a tailored taxonomy facilitates an in-depth understanding of GML IP protection. Furthermore, we present a systematic evaluation framework to assess the effectiveness of IP protection methods, introduce a curated set of benchmark datasets across various domains, and discuss their application scopes and future challenges. Finally, we establish an open-sourced versatile library named PyGIP, which evaluates various attack and defense techniques in GMLaaS scenarios and facilitates the implementation of existing benchmark methods. The library resource can be accessed at: https://labrai.github.io/PyGIP. We believe this survey will play a fundamental role in intellectual property protection for GML and provide practical recipes for the GML community.
A Systematic Survey of Model Extraction Attacks and Defenses: State-of-the-Art and Perspectives
Aug 20, 2025



Machine learning (ML) models have significantly grown in complexity and utility, driving advances across multiple domains. However, substantial computational resources and specialized expertise have historically restricted their wide adoption. Machine-Learning-as-a-Service (MLaaS) platforms have addressed these barriers by providing scalable, convenient, and affordable access to sophisticated ML models through user-friendly APIs. While this accessibility promotes widespread use of advanced ML capabilities, it also introduces vulnerabilities exploited through Model Extraction Attacks (MEAs). Recent studies have demonstrated that adversaries can systematically replicate a target model's functionality by interacting with publicly exposed interfaces, posing threats to intellectual property, privacy, and system security. In this paper, we offer a comprehensive survey of MEAs and corresponding defense strategies. We propose a novel taxonomy that classifies MEAs according to attack mechanisms, defense approaches, and computing environments. Our analysis covers various attack techniques, evaluates their effectiveness, and highlights challenges faced by existing defenses, particularly the critical trade-off between preserving model utility and ensuring security. We further assess MEAs within different computing paradigms and discuss their technical, ethical, legal, and societal implications, along with promising directions for future research. This systematic survey aims to serve as a valuable reference for researchers, practitioners, and policymakers engaged in AI security and privacy. Additionally, we maintain an online repository continuously updated with related literature at https://github.com/kzhao5/ModelExtractionPapers.
A Survey of Model Extraction Attacks and Defenses in Distributed Computing Environments
Feb 22, 2025Model Extraction Attacks (MEAs) threaten modern machine learning systems by enabling adversaries to steal models, exposing intellectual property and training data. With the increasing deployment of machine learning models in distributed computing environments, including cloud, edge, and federated learning settings, each paradigm introduces distinct vulnerabilities and challenges. Without a unified perspective on MEAs across these distributed environments, organizations risk fragmented defenses, inadequate risk assessments, and substantial economic and privacy losses. This survey is motivated by the urgent need to understand how the unique characteristics of cloud, edge, and federated deployments shape attack vectors and defense requirements. We systematically examine the evolution of attack methodologies and defense mechanisms across these environments, demonstrating how environmental factors influence security strategies in critical sectors such as autonomous vehicles, healthcare, and financial services. By synthesizing recent advances in MEAs research and discussing the limitations of current evaluation practices, this survey provides essential insights for developing robust and adaptive defense strategies. Our comprehensive approach highlights the importance of integrating protective measures across the entire distributed computing landscape to ensure the secure deployment of machine learning models.
Political-LLM: Large Language Models in Political Science
Dec 09, 2024



In recent years, large language models (LLMs) have been widely adopted in political science tasks such as election prediction, sentiment analysis, policy impact assessment, and misinformation detection. Meanwhile, the need to systematically understand how LLMs can further revolutionize the field also becomes urgent. In this work, we--a multidisciplinary team of researchers spanning computer science and political science--present the first principled framework termed Political-LLM to advance the comprehensive understanding of integrating LLMs into computational political science. Specifically, we first introduce a fundamental taxonomy classifying the existing explorations into two perspectives: political science and computational methodologies. In particular, from the political science perspective, we highlight the role of LLMs in automating predictive and generative tasks, simulating behavior dynamics, and improving causal inference through tools like counterfactual generation; from a computational perspective, we introduce advancements in data preparation, fine-tuning, and evaluation methods for LLMs that are tailored to political contexts. We identify key challenges and future directions, emphasizing the development of domain-specific datasets, addressing issues of bias and fairness, incorporating human expertise, and redefining evaluation criteria to align with the unique requirements of computational political science. Political-LLM seeks to serve as a guidebook for researchers to foster an informed, ethical, and impactful use of Artificial Intelligence in political science. Our online resource is available at: http://political-llm.org/.
NEAT: Nonlinear Parameter-efficient Adaptation of Pre-trained Models
Oct 02, 2024



Fine-tuning pre-trained models is crucial for adapting large models to downstream tasks, often delivering state-of-the-art performance. However, fine-tuning all model parameters is resource-intensive and laborious, leading to the emergence of parameter-efficient fine-tuning (PEFT) methods. One widely adopted PEFT technique, Low-Rank Adaptation (LoRA), freezes the pre-trained model weights and introduces two low-rank matrices whose ranks are significantly smaller than the dimensions of the original weight matrices. This enables efficient fine-tuning by adjusting only a small number of parameters. Despite its efficiency, LoRA approximates weight updates using low-rank decomposition, which struggles to capture complex, non-linear components and efficient optimization trajectories. As a result, LoRA-based methods often exhibit a significant performance gap compared to full fine-tuning. Closing this gap requires higher ranks, which increases the number of parameters. To address these limitations, we propose a nonlinear parameter-efficient adaptation method (NEAT). NEAT introduces a lightweight neural network that takes pre-trained weights as input and learns a nonlinear transformation to approximate cumulative weight updates. These updates can be interpreted as functions of the corresponding pre-trained weights. The nonlinear approximation directly models the cumulative updates, effectively capturing complex and non-linear structures in the weight updates. Our theoretical analysis demonstrates taht NEAT can be more efficient than LoRA while having equal or greater expressivity. Extensive evaluations across four benchmarks and over twenty datasets demonstrate that NEAT significantly outperforms baselines in both vision and text tasks.
STG-Mamba: Spatial-Temporal Graph Learning via Selective State Space Model
Mar 31, 2024



Spatial-Temporal Graph (STG) data is characterized as dynamic, heterogenous, and non-stationary, leading to the continuous challenge of spatial-temporal graph learning. In the past few years, various GNN-based methods have been proposed to solely focus on mimicking the relationships among node individuals of the STG network, ignoring the significance of modeling the intrinsic features that exist in STG system over time. In contrast, modern Selective State Space Models (SSSMs) present a new approach which treat STG Network as a system, and meticulously explore the STG system's dynamic state evolution across temporal dimension. In this work, we introduce Spatial-Temporal Graph Mamba (STG-Mamba) as the first exploration of leveraging the powerful selective state space models for STG learning by treating STG Network as a system, and employing the Graph Selective State Space Block (GS3B) to precisely characterize the dynamic evolution of STG networks. STG-Mamba is formulated as an Encoder-Decoder architecture, which takes GS3B as the basic module, for efficient sequential data modeling. Furthermore, to strengthen GNN's ability of modeling STG data under the setting of SSSMs, we propose Kalman Filtering Graph Neural Networks (KFGN) for adaptive graph structure upgrading. KFGN smoothly fits in the context of selective state space evolution, and at the same time keeps linear complexity. Extensive empirical studies are conducted on three benchmark STG forecasting datasets, demonstrating the performance superiority and computational efficiency of STG-Mamba. It not only surpasses existing state-of-the-art methods in terms of STG forecasting performance, but also effectively alleviate the computational bottleneck of large-scale graph networks in reducing the computational cost of FLOPs and test inference time.
Data-Centric Evolution in Autonomous Driving: A Comprehensive Survey of Big Data System, Data Mining, and Closed-Loop Technologies
Jan 26, 2024The aspiration of the next generation's autonomous driving (AD) technology relies on the dedicated integration and interaction among intelligent perception, prediction, planning, and low-level control. There has been a huge bottleneck regarding the upper bound of autonomous driving algorithm performance, a consensus from academia and industry believes that the key to surmount the bottleneck lies in data-centric autonomous driving technology. Recent advancement in AD simulation, closed-loop model training, and AD big data engine have gained some valuable experience. However, there is a lack of systematic knowledge and deep understanding regarding how to build efficient data-centric AD technology for AD algorithm self-evolution and better AD big data accumulation. To fill in the identified research gaps, this article will closely focus on reviewing the state-of-the-art data-driven autonomous driving technologies, with an emphasis on the comprehensive taxonomy of autonomous driving datasets characterized by milestone generations, key features, data acquisition settings, etc. Furthermore, we provide a systematic review of the existing benchmark closed-loop AD big data pipelines from the industrial frontier, including the procedure of closed-loop frameworks, key technologies, and empirical studies. Finally, the future directions, potential applications, limitations and concerns are discussed to arouse efforts from both academia and industry for promoting the further development of autonomous driving. The project repository is available at: https://github.com/LincanLi98/Awesome-Data-Centric-Autonomous-Driving.
STS-CCL: Spatial-Temporal Synchronous Contextual Contrastive Learning for Urban Traffic Forecasting
Jul 05, 2023Efficiently capturing the complex spatiotemporal representations from large-scale unlabeled traffic data remains to be a challenging task. In considering of the dilemma, this work employs the advanced contrastive learning and proposes a novel Spatial-Temporal Synchronous Contextual Contrastive Learning (STS-CCL) model. First, we elaborate the basic and strong augmentation methods for spatiotemporal graph data, which not only perturb the data in terms of graph structure and temporal characteristics, but also employ a learning-based dynamic graph view generator for adaptive augmentation. Second, we introduce a Spatial-Temporal Synchronous Contrastive Module (STS-CM) to simultaneously capture the decent spatial-temporal dependencies and realize graph-level contrasting. To further discriminate node individuals in negative filtering, a Semantic Contextual Contrastive method is designed based on semantic features and spatial heterogeneity, achieving node-level contrastive learning along with negative filtering. Finally, we present a hard mutual-view contrastive training scheme and extend the classic contrastive loss to an integrated objective function, yielding better performance. Extensive experiments and evaluations demonstrate that building a predictor upon STS-CCL contrastive learning model gains superior performance than existing traffic forecasting benchmarks. The proposed STS-CCL is highly suitable for large datasets with only a few labeled data and other spatiotemporal tasks with data scarcity issue.
Reinforcement Learning-Based Joint Self-Optimisation Method for the Fuzzy Logic Handover Algorithm in 5G HetNets
Jun 17, 2020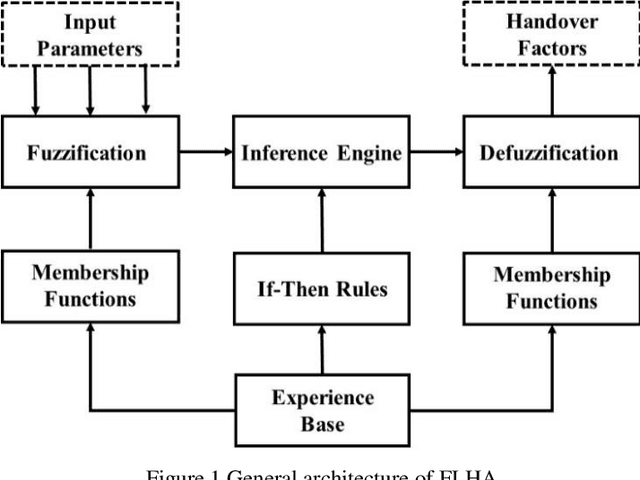

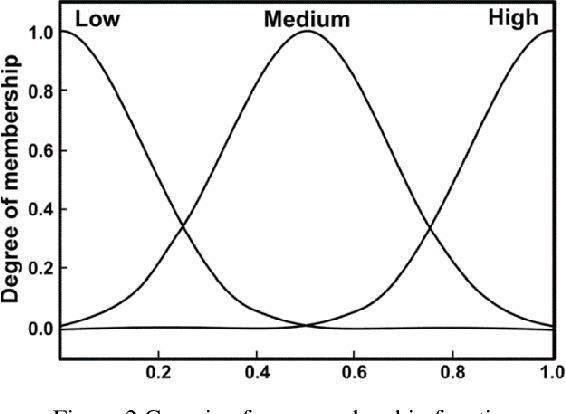

5G heterogeneous networks (HetNets) can provide higher network coverage and system capacity to the user by deploying massive small base stations (BSs) within the 4G macro system. However, the large-scale deployment of small BSs significantly increases the complexity and workload of network maintenance and optimisation. The current handover (HO) triggering mechanism A3 event was designed only for mobility management in the macro system. Directly implementing A3 in 5G-HetNets may degrade the user mobility robustness. Motivated by the concept of self-organisation networks (SON), this study developed a self-optimised triggering mechanism to enable automated network maintenance and enhance user mobility robustness in 5G-HetNets. The proposed method integrates the advantages of subtractive clustering and Q-learning frameworks into the conventional fuzzy logic-based HO algorithm (FLHA). Subtractive clustering is first adopted to generate a membership function (MF) for the FLHA to enable FLHA with the self-configuration feature. Subsequently, Q-learning is utilised to learn the optimal HO policy from the environment as fuzzy rules that empower the FLHA with a self-optimisation function. The FLHA with SON functionality also overcomes the limitations of the conventional FLHA that must rely heavily on professional experience to design. The simulation results show that the proposed self-optimised FLHA can effectively generate MF and fuzzy rules for the FLHA. By comparing with conventional triggering mechanisms, the proposed approach can decrease the HO, ping-pong HO, and HO failure ratios by approximately 91%, 49%, and 97.5% while improving network throughput and latency by 8% and 35%, respectively.