 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior-Guided Multi-Omic Transformers for Single-Cell Gene Regulatory Network Inference
May 30, 2026Gene regulatory networks (GRNs) capture transcription factor-target interactions and are central to understanding cell-state regulation and disease. Reconstructing GRNs from paired single-cell transcriptomic and chromatin accessibility data is promising but challenging: scATAC is extremely sparse, and most methods rely on fixed peak-to-gene links and weak supervision. We present EpiAwareNet, a prior-guided multi-omic Transformer framework that reconstructs GRNs from paired single-cell data using only lightweight biological priors. In Stage 1, EpiAwareNet learns joint gene-peak representations with a gene-peak cross-attention module, enabling data-driven, gene-specific aggregation of accessibility signals rather than hard-coded peak-to-gene assignments. In Stage 2, EpiAwareNet incorporates a bulk-derived GRN prior as noisy positive edges to provide weak supervision under label scarcity, refining regulatory scores while remaining robust to prior noise. In our experiments, EpiAwareNet improves GRN reconstruction over representative single- and multi-omic baselines and yields GRNs with greater biological plausibility, such as improved recovery of known regulatory interactions, suggesting that lightweight biological priors from bulk data can effectively guide single-cell GRN inference when combined with adaptive cross-modal representation learning. Code and data will be available at https://github.com/tianyang-x/EpiAwareNet_pub.
RUBRIC-ARROW: Alternating Pointwise Rubric Reward Modeling for LLM Post-training in Non-verifiable Domains
May 27, 2026Pointwise reward modeling offers critical signals for LLM post-training, yet struggles with absolute scoring in subjective, non-verifiable settings. Rubric-based methods address this by decomposing evaluation into explicit criteria, but existing approaches typically depend on frontier LLMs and suffer from ties caused by hard Boolean aggregation. We present RUBRIC-ARROW, an alternating framework that jointly trains a rubric generator and a rubric-conditioned judge, with its RL stage using only pairwise preference data. Our method couples a probability-based scoring rule that reduces ties with phase-specific preference-based rewards and an alternating GRPO scheme that together train the pointwise evaluator. Extensive experiments show that RUBRIC-ARROW achieves competitive reward-modeling accuracy and yields consistent gains for downstream policy post-training.
LegalDrill: Diagnosis-Driven Synthesis for Legal Reasoning in Small Language Models
Apr 26, 2026Small language models (SLMs) are promising for real-world deployment due to their efficiency and low operational cost. However, their limited capacity struggles with high-stakes legal reasoning tasks that require coherent statute interpretation and logically consistent deduction. Furthermore, training SLMs for such tasks demands high-quality, concise reasoning trajectories, which are prohibitively expensive to manually collect and difficult to curate via standard rejection sampling, lacking granularity beyond final verdicts. To address these challenges, we propose {LegalDrill}, a diagnosis-driven synthesis framework that extracts and iteratively refines reasoning trajectories from a capable teacher via fine-grained prompting, then a self-reflective verification is employed to adaptively select the most effective data for the SLM student. The resulting data empower SLM training through supervised fine-tuning and direct preference optimization. Extensive experiments on several legal benchmarks demonstrate that {LegalDrill} significantly bolsters the legal reasoning capabilities of representative SLMs while bypassing the need for scarce expert annotations, paving a scalable path toward practical legal reasoning systems.
Alternating Reinforcement Learning for Rubric-Based Reward Modeling in Non-Verifiable LLM Post-Training
Feb 02, 2026Standard reward models typically predict scalar scores that fail to capture the multifaceted nature of response quality in non-verifiable domains, such as creative writing or open-ended instruction following. To address this limitation, we propose Rubric-ARM, a framework that jointly optimizes a rubric generator and a judge using reinforcement learning from preference feedback. Unlike existing methods that rely on static rubrics or disjoint training pipelines, our approach treats rubric generation as a latent action learned to maximize judgment accuracy. We introduce an alternating optimization strategy to mitigate the non-stationarity of simultaneous updates, providing theoretical analysis that demonstrates how this schedule reduces gradient variance during training. Extensive experiments show that Rubric-ARM achieves state-of-the-art performance among baselines on multiple benchmarks and significantly improves downstream policy alignment in both offline and online reinforcement learning settings.
OpenRubrics: Towards Scalable Synthetic Rubric Generation for Reward Modeling and LLM Alignment
Oct 09, 2025



Reward modeling lies at the core of reinforcement learning from human feedback (RLHF), yet most existing reward models rely on scalar or pairwise judgments that fail to capture the multifaceted nature of human preferences. Recent studies have explored rubrics-as-rewards (RaR) that uses structured natural language criteria that capture multiple dimensions of response quality. However, producing rubrics that are both reliable and scalable remains a key challenge. In this work, we introduce OpenRubrics, a diverse, large-scale collection of (prompt, rubric) pairs for training rubric-generation and rubric-based reward models. To elicit discriminative and comprehensive evaluation signals, we introduce Contrastive Rubric Generation (CRG), which derives both hard rules (explicit constraints) and principles (implicit qualities) by contrasting preferred and rejected responses. We further improve reliability by enforcing preference-label consistency via rejection sampling to remove noisy rubrics. Across multiple reward-modeling benchmarks, our rubric-based reward model, Rubric-RM, surpasses strong size-matched baselines by 6.8%. These gains transfer to policy models on instruction-following and biomedical benchmarks. Our results show that rubrics provide scalable alignment signals that narrow the gap between costly human evaluation and automated reward modeling, enabling a new principle-driven paradigm for LLM alignment.
ScaleLong: A Multi-Timescale Benchmark for Long Video Understanding
May 29, 2025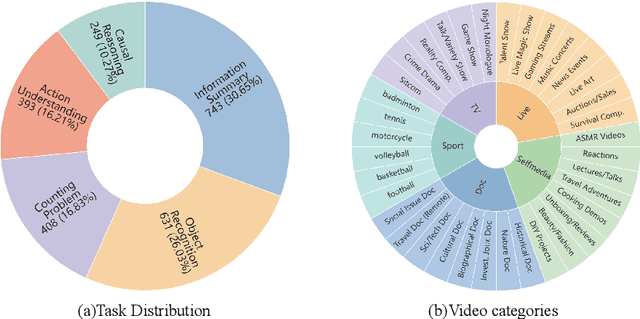



Although long-video understanding demands that models capture hierarchical temporal information -- from clip (seconds) and shot (tens of seconds) to event (minutes) and story (hours) -- existing benchmarks either neglect this multi-scale design or scatter scale-specific questions across different videos, preventing direct comparison of model performance across timescales on the same content. To address this, we introduce ScaleLong, the first benchmark to disentangle these factors by embedding questions targeting four hierarchical timescales -- clip (seconds), shot (tens of seconds), event (minutes), and story (hours) -- all within the same video content. This within-content multi-timescale questioning design enables direct comparison of model performance across timescales on identical videos. ScaleLong features 269 long videos (avg.\ 86\,min) from 5 main categories and 36 sub-categories, with 4--8 carefully designed questions, including at least one question for each timescale. Evaluating 23 MLLMs reveals a U-shaped performance curve, with higher accuracy at the shortest and longest timescales and a dip at intermediate levels. Furthermore, ablation studies show that increased visual token capacity consistently enhances reasoning across all timescales. ScaleLong offers a fine-grained, multi-timescale benchmark for advancing MLLM capabilities in long-video understanding. The code and dataset are available https://github.com/multimodal-art-projection/ScaleLong.
NEAT: Nonlinear Parameter-efficient Adaptation of Pre-trained Models
Oct 02, 2024



Fine-tuning pre-trained models is crucial for adapting large models to downstream tasks, often delivering state-of-the-art performance. However, fine-tuning all model parameters is resource-intensive and laborious, leading to the emergence of parameter-efficient fine-tuning (PEFT) methods. One widely adopted PEFT technique, Low-Rank Adaptation (LoRA), freezes the pre-trained model weights and introduces two low-rank matrices whose ranks are significantly smaller than the dimensions of the original weight matrices. This enables efficient fine-tuning by adjusting only a small number of parameters. Despite its efficiency, LoRA approximates weight updates using low-rank decomposition, which struggles to capture complex, non-linear components and efficient optimization trajectories. As a result, LoRA-based methods often exhibit a significant performance gap compared to full fine-tuning. Closing this gap requires higher ranks, which increases the number of parameters. To address these limitations, we propose a nonlinear parameter-efficient adaptation method (NEAT). NEAT introduces a lightweight neural network that takes pre-trained weights as input and learns a nonlinear transformation to approximate cumulative weight updates. These updates can be interpreted as functions of the corresponding pre-trained weights. The nonlinear approximation directly models the cumulative updates, effectively capturing complex and non-linear structures in the weight updates. Our theoretical analysis demonstrates taht NEAT can be more efficient than LoRA while having equal or greater expressivity. Extensive evaluations across four benchmarks and over twenty datasets demonstrate that NEAT significantly outperforms baselines in both vision and text tasks.
Counterfactual Fairness by Combining Factual and Counterfactual Predictions
Sep 03, 2024



In high-stake domains such as healthcare and hiring, the role of machine learning (ML) in decision-making raises significant fairness concerns. This work focuses on Counterfactual Fairness (CF), which posits that an ML model's outcome on any individual should remain unchanged if they had belonged to a different demographic group. Previous works have proposed methods that guarantee CF. Notwithstanding, their effects on the model's predictive performance remains largely unclear. To fill in this gap, we provide a theoretical study on the inherent trade-off between CF and predictive performance in a model-agnostic manner. We first propose a simple but effective method to cast an optimal but potentially unfair predictor into a fair one without losing the optimality. By analyzing its excess risk in order to achieve CF, we quantify this inherent trade-off. Further analysis on our method's performance with access to only incomplete causal knowledge is also conducted. Built upon it, we propose a performant algorithm that can be applied in such scenarios. Experiments on both synthetic and semi-synthetic datasets demonstrate the validity of our analysis and methods.
FIARSE: Model-Heterogeneous Federated Learning via Importance-Aware Submodel Extraction
Jul 28, 2024
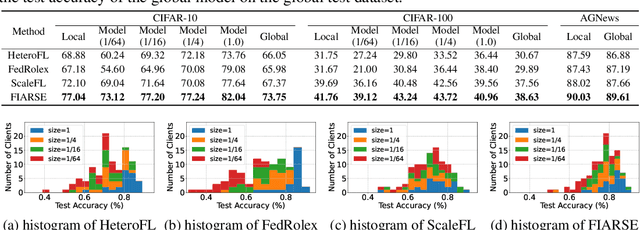
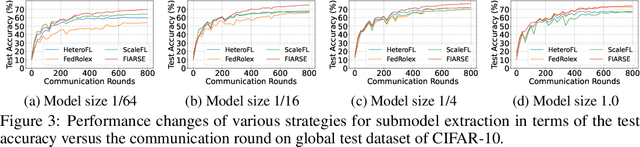

In federated learning (FL), accommodating clients' varied computational capacities poses a challenge, often limiting the participation of those with constrained resources in global model training. To address this issue, the concept of model heterogeneity through submodel extraction has emerged, offering a tailored solution that aligns the model's complexity with each client's computational capacity. In this work, we propose Federated Importance-Aware Submodel Extraction (FIARSE), a novel approach that dynamically adjusts submodels based on the importance of model parameters, thereby overcoming the limitations of previous static and dynamic submodel extraction methods. Compared to existing works, the proposed method offers a theoretical foundation for the submodel extraction and eliminates the need for additional information beyond the model parameters themselves to determine parameter importance, significantly reducing the overhead on clients. Extensive experiments are conducted on various datasets to showcase superior performance of the proposed FIARSE.
RoseLoRA: Row and Column-wise Sparse Low-rank Adaptation of Pre-trained Language Model for Knowledge Editing and Fine-tuning
Jun 16, 2024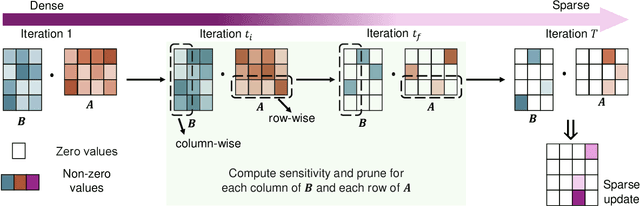
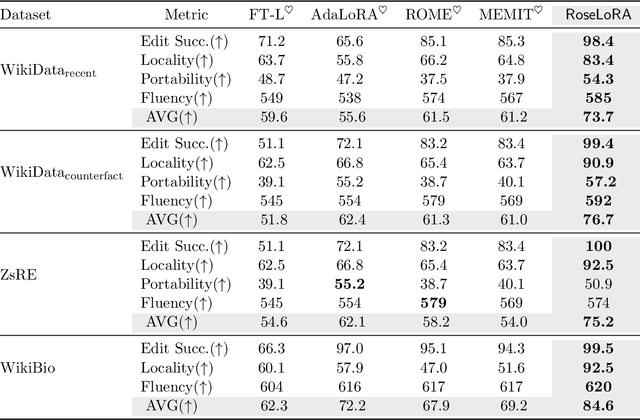
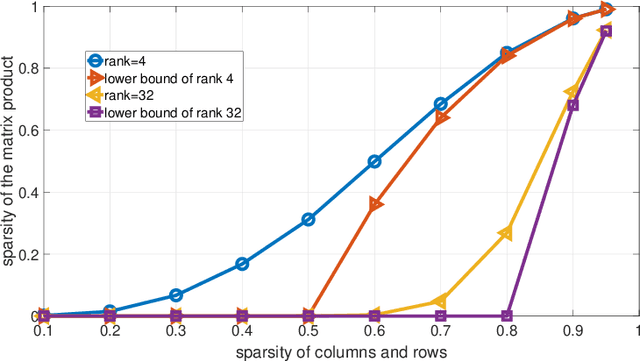
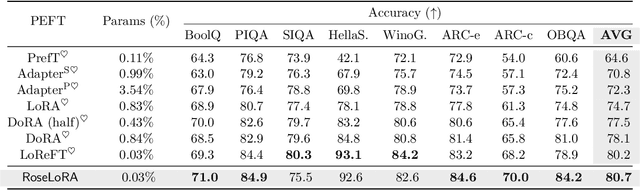
Pre-trained language models, trained on large-scale corpora, demonstrate strong generalizability across various NLP tasks. Fine-tuning these models for specific tasks typically involves updating all parameters, which is resource-intensive. Parameter-efficient fine-tuning (PEFT) methods, such as the popular LoRA family, introduce low-rank matrices to learn only a few parameters efficiently. However, during inference, the product of these matrices updates all pre-trained parameters, complicating tasks like knowledge editing that require selective updates. We propose a novel PEFT method, which conducts \textbf{r}ow and c\textbf{o}lumn-wise spar\textbf{se} \textbf{lo}w-\textbf{r}ank \textbf{a}daptation (RoseLoRA), to address this challenge. RoseLoRA identifies and updates only the most important parameters for a specific task, maintaining efficiency while preserving other model knowledge. By adding a sparsity constraint on the product of low-rank matrices and converting it to row and column-wise sparsity, we ensure efficient and precise model updates. Our theoretical analysis guarantees the lower bound of the sparsity with respective to the matrix product. Extensive experiments on five benchmarks across twenty datasets demonstrate that RoseLoRA outperforms baselines in both general fine-tuning and knowledge editing tasks.