 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePORTool: Tool-Use LLM Training with Rewarded Tree
Oct 29, 2025Current tool-use large language models (LLMs) are trained on static datasets, enabling them to interact with external tools and perform multi-step, tool-integrated reasoning, which produces tool-call trajectories. However, these models imitate how a query is resolved in a generic tool-call routine, thereby failing to explore possible solutions and demonstrating limited performance in an evolved, dynamic tool-call environment. In this work, we propose PORTool, a reinforcement learning (RL) method that encourages a tool-use LLM to explore various trajectories yielding the correct answer. Specifically, this method starts with generating multiple rollouts for a given query, and some of them share the first few tool-call steps, thereby forming a tree-like structure. Next, we assign rewards to each step, based on its ability to produce a correct answer and make successful tool calls. A shared step across different trajectories receives the same reward, while different steps under the same fork receive different rewards. Finally, these step-wise rewards are used to calculate fork-relative advantages, blended with trajectory-relative advantages, to train the LLM for tool use. The experiments utilize 17 tools to address user queries, covering both time-sensitive and time-invariant topics. We conduct ablation studies to systematically justify the necessity and the design robustness of step-wise rewards. Furthermore, we compare the proposed PORTool with other training approaches and demonstrate significant improvements in final accuracy and the number of tool-call steps.
Towards Privacy-Preserving and Heterogeneity-aware Split Federated Learning via Probabilistic Masking
Sep 18, 2025Split Federated Learning (SFL) has emerged as an efficient alternative to traditional Federated Learning (FL) by reducing client-side computation through model partitioning. However, exchanging of intermediate activations and model updates introduces significant privacy risks, especially from data reconstruction attacks that recover original inputs from intermediate representations. Existing defenses using noise injection often degrade model performance. To overcome these challenges, we present PM-SFL, a scalable and privacy-preserving SFL framework that incorporates Probabilistic Mask training to add structured randomness without relying on explicit noise. This mitigates data reconstruction risks while maintaining model utility. To address data heterogeneity, PM-SFL employs personalized mask learning that tailors submodel structures to each client's local data. For system heterogeneity, we introduce a layer-wise knowledge compensation mechanism, enabling clients with varying resources to participate effectively under adaptive model splitting. Theoretical analysis confirms its privacy protection, and experiments on image and wireless sensing tasks demonstrate that PM-SFL consistently improves accuracy, communication efficiency, and robustness to privacy attacks, with particularly strong performance under data and system heterogeneity.
SUV: Scalable Large Language Model Copyright Compliance with Regularized Selective Unlearning
Mar 29, 2025Large Language Models (LLMs) have transformed natural language processing by learning from massive datasets, yet this rapid progress has also drawn legal scrutiny, as the ability to unintentionally generate copyrighted content has already prompted several prominent lawsuits. In this work, we introduce SUV (Selective Unlearning for Verbatim data), a selective unlearning framework designed to prevent LLM from memorizing copyrighted content while preserving its overall utility. In detail, the proposed method constructs a dataset that captures instances of copyrighted infringement cases by the targeted LLM. With the dataset, we unlearn the content from the LLM by means of Direct Preference Optimization (DPO), which replaces the verbatim copyrighted content with plausible and coherent alternatives. Since DPO may hinder the LLM's performance in other unrelated tasks, we integrate gradient projection and Fisher information regularization to mitigate the degradation. We validate our approach using a large-scale dataset of 500 famous books (predominantly copyrighted works) and demonstrate that SUV significantly reduces verbatim memorization with negligible impact on the performance on unrelated tasks. Extensive experiments on both our dataset and public benchmarks confirm the scalability and efficacy of our approach, offering a promising solution for mitigating copyright risks in real-world LLM applications.
Talk to Right Specialists: Routing and Planning in Multi-agent System for Question Answering
Jan 14, 2025



Leveraging large language models (LLMs), an agent can utilize retrieval-augmented generation (RAG) techniques to integrate external knowledge and increase the reliability of its responses. Current RAG-based agents integrate single, domain-specific knowledge sources, limiting their ability and leading to hallucinated or inaccurate responses when addressing cross-domain queries. Integrating multiple knowledge bases into a unified RAG-based agent raises significant challenges, including increased retrieval overhead and data sovereignty when sensitive data is involved. In this work, we propose RopMura, a novel multi-agent system that addresses these limitations by incorporating highly efficient routing and planning mechanisms. RopMura features two key components: a router that intelligently selects the most relevant agents based on knowledge boundaries and a planner that decomposes complex multi-hop queries into manageable steps, allowing for coordinating cross-domain responses. Experimental results demonstrate that RopMura effectively handles both single-hop and multi-hop queries, with the routing mechanism enabling precise answers for single-hop queries and the combined routing and planning mechanisms achieving accurate, multi-step resolutions for complex queries.
FIARSE: Model-Heterogeneous Federated Learning via Importance-Aware Submodel Extraction
Jul 28, 2024
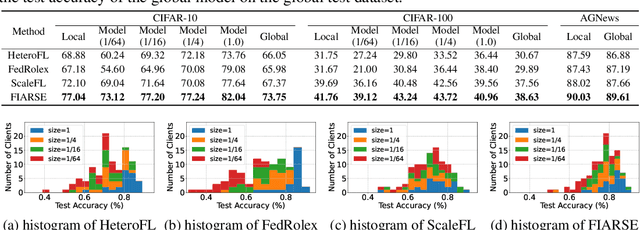
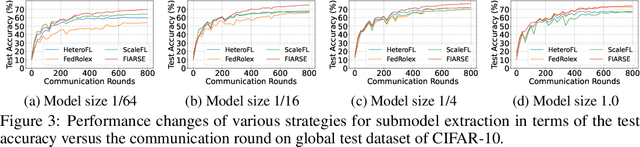

In federated learning (FL), accommodating clients' varied computational capacities poses a challenge, often limiting the participation of those with constrained resources in global model training. To address this issue, the concept of model heterogeneity through submodel extraction has emerged, offering a tailored solution that aligns the model's complexity with each client's computational capacity. In this work, we propose Federated Importance-Aware Submodel Extraction (FIARSE), a novel approach that dynamically adjusts submodels based on the importance of model parameters, thereby overcoming the limitations of previous static and dynamic submodel extraction methods. Compared to existing works, the proposed method offers a theoretical foundation for the submodel extraction and eliminates the need for additional information beyond the model parameters themselves to determine parameter importance, significantly reducing the overhead on clients. Extensive experiments are conducted on various datasets to showcase superior performance of the proposed FIARSE.
On the Client Preference of LLM Fine-tuning in Federated Learning
Jul 03, 2024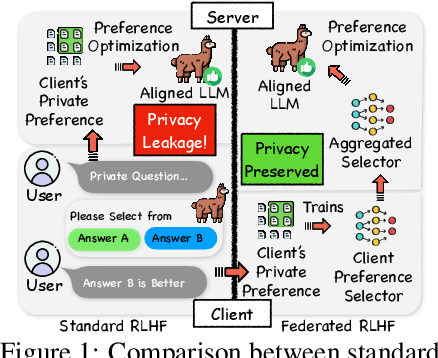
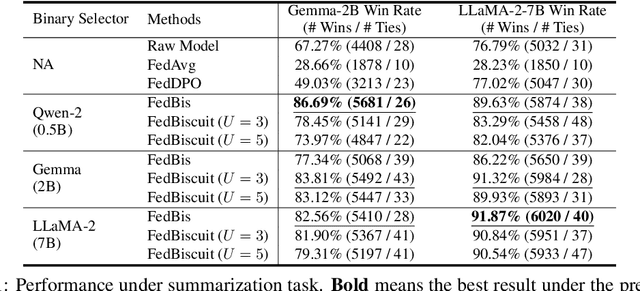
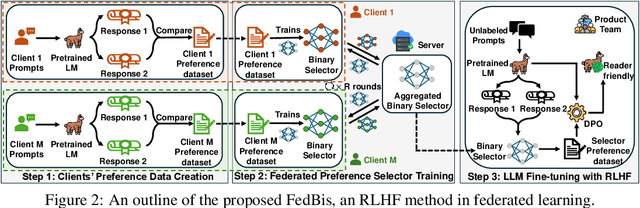
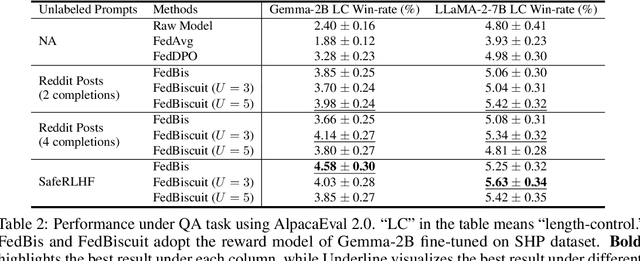
Reinforcement learning with human feedback (RLHF) fine-tunes a pretrained large language model (LLM) using preference datasets, enabling the LLM to generate outputs that align with human preferences. Given the sensitive nature of these preference datasets held by various clients, there is a need to implement RLHF within a federated learning (FL) framework, where clients are reluctant to share their data due to privacy concerns. To address this, we introduce a feasible framework in which clients collaboratively train a binary selector with their preference datasets using our proposed FedBis. With a well-trained selector, we can further enhance the LLM that generates human-preferred completions. Meanwhile, we propose a novel algorithm, FedBiscuit, that trains multiple selectors by organizing clients into balanced and disjoint clusters based on their preferences. Compared to the FedBis, FedBiscuit demonstrates superior performance in simulating human preferences for pairwise completions. Our extensive experiments on federated human preference datasets -- marking the first benchmark to address heterogeneous data partitioning among clients -- demonstrate that FedBiscuit outperforms FedBis and even surpasses traditional centralized training.
FedBiOT: LLM Local Fine-tuning in Federated Learning without Full Model
Jun 25, 2024Large language models (LLMs) show amazing performance on many domain-specific tasks after fine-tuning with some appropriate data. However, many domain-specific data are privately distributed across multiple owners. Thus, this dilemma raises the interest in how to perform LLM fine-tuning in federated learning (FL). However, confronted with limited computation and communication capacities, FL clients struggle to fine-tune an LLM effectively. To this end, we introduce FedBiOT, a resource-efficient LLM fine-tuning approach to FL. Specifically, our method involves the server generating a compressed LLM and aligning its performance with the full model. Subsequently, the clients fine-tune a lightweight yet important part of the compressed model, referred to as an adapter. Notice that as the server has no access to the private data owned by the clients, the data used for alignment by the server has a different distribution from the one used for fine-tuning by clients. We formulate the problem into a bi-level optimization problem to minimize the negative effect of data discrepancy and derive the updating rules for the server and clients. We conduct extensive experiments on LLaMA-2, empirically showing that the adapter has exceptional performance when reintegrated into the global LLM. The results also indicate that the proposed FedBiOT significantly reduces resource consumption compared to existing benchmarks, all while achieving comparable performance levels.
SHIELD: Evaluation and Defense Strategies for Copyright Compliance in LLM Text Generation
Jun 18, 2024



Large Language Models (LLMs) have transformed machine learning but raised significant legal concerns due to their potential to produce text that infringes on copyrights, resulting in several high-profile lawsuits. The legal landscape is struggling to keep pace with these rapid advancements, with ongoing debates about whether generated text might plagiarize copyrighted materials. Current LLMs may infringe on copyrights or overly restrict non-copyrighted texts, leading to these challenges: (i) the need for a comprehensive evaluation benchmark to assess copyright compliance from multiple aspects; (ii) evaluating robustness against safeguard bypassing attacks; and (iii) developing effective defenses targeted against the generation of copyrighted text. To tackle these challenges, we introduce a curated dataset to evaluate methods, test attack strategies, and propose lightweight, real-time defenses to prevent the generation of copyrighted text, ensuring the safe and lawful use of LLMs. Our experiments demonstrate that current LLMs frequently output copyrighted text, and that jailbreaking attacks can significantly increase the volume of copyrighted output. Our proposed defense mechanisms significantly reduce the volume of copyrighted text generated by LLMs by effectively refusing malicious requests. Code is publicly available at https://github.com/xz-liu/SHIELD
Evaluating the Factuality of Large Language Models using Large-Scale Knowledge Graphs
Apr 01, 2024



The advent of Large Language Models (LLMs) has significantly transformed the AI landscape, enhancing machine learning and AI capabilities. Factuality issue is a critical concern for LLMs, as they may generate factually incorrect responses. In this paper, we propose GraphEval to evaluate an LLM's performance using a substantially large test dataset. Specifically, the test dataset is retrieved from a large knowledge graph with more than 10 million facts without expensive human efforts. Unlike conventional methods that evaluate LLMs based on generated responses, GraphEval streamlines the evaluation process by creating a judge model to estimate the correctness of the answers given by the LLM. Our experiments demonstrate that the judge model's factuality assessment aligns closely with the correctness of the LLM's generated outputs, while also substantially reducing evaluation costs. Besides, our findings offer valuable insights into LLM performance across different metrics and highlight the potential for future improvements in ensuring the factual integrity of LLM outputs. The code is publicly available at https://github.com/xz-liu/GraphEval.
Towards Poisoning Fair Representations
Sep 28, 2023Fair machine learning seeks to mitigate model prediction bias against certain demographic subgroups such as elder and female. Recently, fair representation learning (FRL) trained by deep neural networks has demonstrated superior performance, whereby representations containing no demographic information are inferred from the data and then used as the input to classification or other downstream tasks. Despite the development of FRL methods, their vulnerability under data poisoning attack, a popular protocol to benchmark model robustness under adversarial scenarios, is under-explored. Data poisoning attacks have been developed for classical fair machine learning methods which incorporate fairness constraints into shallow-model classifiers. Nonetheless, these attacks fall short in FRL due to notably different fairness goals and model architectures. This work proposes the first data poisoning framework attacking FRL. We induce the model to output unfair representations that contain as much demographic information as possible by injecting carefully crafted poisoning samples into the training data. This attack entails a prohibitive bilevel optimization, wherefore an effective approximated solution is proposed. A theoretical analysis on the needed number of poisoning samples is derived and sheds light on defending against the attack. Experiments on benchmark fairness datasets and state-of-the-art fair representation learning models demonstrate the superiority of our attack.