 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlexRL: Cluster-Level Orchestration of Serviceized LLM Execution for RLVR
May 20, 2026Reinforcement learning with verifiable rewards (RLVR) has recently unlocked strong reasoning capabilities in large language models (LLMs), triggering rapid exploration of new algorithms and data. However, RLVR training is notoriously inefficient: long-tailed rollouts, tool-induced stalls, and asymmetric resource requirements between rollout and training introduce substantial idle time that cannot be eliminated by job-local optimizations such as synchronous pipelining, asynchronous rollout, or colocated execution. We argue that this inefficiency is structural. While idle gaps are unavoidable within individual RLVR jobs, they are largely anti-correlated across jobs and therefore exploitable at the cluster level. Leveraging this observation, we present PlexRL, a cluster-level runtime for multiplexing unified LLM services across RLVR jobs. By centrally managing model placement, state transitions, and function-level scheduling under strict affinity constraints, PlexRL time-slices LLM execution across jobs to fill otherwise idle periods without expensive model migration. Our implementation and evaluations demonstrate that PlexRL significantly improves effective cluster capacity and reduces user GPU hour cost by maximum 37.58% while preserving algorithmic flexibility and introducing minimal per-job overhead.
A Very Big Video Reasoning Suite
Feb 24, 2026Rapid progress in video models has largely focused on visual quality, leaving their reasoning capabilities underexplored. Video reasoning grounds intelligence in spatiotemporally consistent visual environments that go beyond what text can naturally capture, enabling intuitive reasoning over spatiotemporal structure such as continuity, interaction, and causality. However, systematically studying video reasoning and its scaling behavior is hindered by the lack of large-scale training data. To address this gap, we introduce the Very Big Video Reasoning (VBVR) Dataset, an unprecedentedly large-scale resource spanning 200 curated reasoning tasks following a principled taxonomy and over one million video clips, approximately three orders of magnitude larger than existing datasets. We further present VBVR-Bench, a verifiable evaluation framework that moves beyond model-based judging by incorporating rule-based, human-aligned scorers, enabling reproducible and interpretable diagnosis of video reasoning capabilities. Leveraging the VBVR suite, we conduct one of the first large-scale scaling studies of video reasoning and observe early signs of emergent generalization to unseen reasoning tasks. Together, VBVR lays a foundation for the next stage of research in generalizable video reasoning. The data, benchmark toolkit, and models are publicly available at https://video-reason.com/ .
Joint beamforming and mode optimization for multi-functional STAR-RIS-aided integrated sensing and communication networks
Feb 18, 2026This paper investigates the design of integrated sensing and communication (ISAC) systems assisted by simultaneously transmitting and reflecting reconfigurable intelligent surfaces (STAR-RISs), which act as multi-functional programmable metasurfaces capable of supporting concurrent communication and sensing within a unified architecture. We propose a two-stage ISAC protocol, in which the preparation phase performs direction estimation for outdoor users located in the reflection space, while maintaining communication with both outdoor and indoor users in the transmission space. The subsequent communication phase exploits the estimated directions to enhance information transfer. The directions of outdoor users are modeled as Gaussian random variables to capture estimation uncertainty, and the corresponding average communication performance is incorporated into the design. Building on this framework, we formulate a performance-balanced optimization problem that maximizes the communication sum-rate while guaranteeing the required sensing accuracy, jointly determining the beamforming vectors at the base station (BS), the STAR-RIS transmission and reflection coefficients, and the metasurface partition between energy-splitting and transmit-only modes. The physical constraints of STAR-RIS elements and the required sensing performance are explicitly enforced. To address the non-convex nature of the problem, we combine fractional programming, Lagrangian dual reformulation, and successive convex approximation. The binary metasurface partition is ultimately recovered via continuous relaxation followed by projection-based binarization. Numerical results demonstrate that the proposed design achieves an effective trade-off between sensing accuracy and communication throughput, by significantly outperforming conventional STAR-RIS-aided ISAC schemes.
DM0: An Embodied-Native Vision-Language-Action Model towards Physical AI
Feb 16, 2026Moving beyond the traditional paradigm of adapting internet-pretrained models to physical tasks, we present DM0, an Embodied-Native Vision-Language-Action (VLA) framework designed for Physical AI. Unlike approaches that treat physical grounding as a fine-tuning afterthought, DM0 unifies embodied manipulation and navigation by learning from heterogeneous data sources from the onset. Our methodology follows a comprehensive three-stage pipeline: Pretraining, Mid-Training, and Post-Training. First, we conduct large-scale unified pretraining on the Vision-Language Model (VLM) using diverse corpora--seamlessly integrating web text, autonomous driving scenarios, and embodied interaction logs-to jointly acquire semantic knowledge and physical priors. Subsequently, we build a flow-matching action expert atop the VLM. To reconcile high-level reasoning with low-level control, DM0 employs a hybrid training strategy: for embodied data, gradients from the action expert are not backpropagated to the VLM to preserve generalized representations, while the VLM remains trainable on non-embodied data. Furthermore, we introduce an Embodied Spatial Scaffolding strategy to construct spatial Chain-of-Thought (CoT) reasoning, effectively constraining the action solution space. Experiments on the RoboChallenge benchmark demonstrate that DM0 achieves state-of-the-art performance in both Specialist and Generalist settings on Table30.
From Kepler to Newton: Inductive Biases Guide Learned World Models in Transformers
Feb 06, 2026Can general-purpose AI architectures go beyond prediction to discover the physical laws governing the universe? True intelligence relies on "world models" -- causal abstractions that allow an agent to not only predict future states but understand the underlying governing dynamics. While previous "AI Physicist" approaches have successfully recovered such laws, they typically rely on strong, domain-specific priors that effectively "bake in" the physics. Conversely, Vafa et al. recently showed that generic Transformers fail to acquire these world models, achieving high predictive accuracy without capturing the underlying physical laws. We bridge this gap by systematically introducing three minimal inductive biases. We show that ensuring spatial smoothness (by formulating prediction as continuous regression) and stability (by training with noisy contexts to mitigate error accumulation) enables generic Transformers to surpass prior failures and learn a coherent Keplerian world model, successfully fitting ellipses to planetary trajectories. However, true physical insight requires a third bias: temporal locality. By restricting the attention window to the immediate past -- imposing the simple assumption that future states depend only on the local state rather than a complex history -- we force the model to abandon curve-fitting and discover Newtonian force representations. Our results demonstrate that simple architectural choices determine whether an AI becomes a curve-fitter or a physicist, marking a critical step toward automated scientific discovery.
Inverse Depth Scaling From Most Layers Being Similar
Feb 05, 2026Neural scaling laws relate loss to model size in large language models (LLMs), yet depth and width may contribute to performance differently, requiring more detailed studies. Here, we quantify how depth affects loss via analysis of LLMs and toy residual networks. We find loss scales inversely proportional to depth in LLMs, probably due to functionally similar layers reducing error through ensemble averaging rather than compositional learning or discretizing smooth dynamics. This regime is inefficient yet robust and may arise from the architectural bias of residual networks and target functions incompatible with smooth dynamics. The findings suggest that improving LLM efficiency may require architectural innovations to encourage compositional use of depth.
Universal One-third Time Scaling in Learning Peaked Distributions
Feb 03, 2026Training large language models (LLMs) is computationally expensive, partly because the loss exhibits slow power-law convergence whose origin remains debatable. Through systematic analysis of toy models and empirical evaluation of LLMs, we show that this behavior can arise intrinsically from the use of softmax and cross-entropy. When learning peaked probability distributions, e.g., next-token distributions, these components yield power-law vanishing losses and gradients, creating a fundamental optimization bottleneck. This ultimately leads to power-law time scaling of the loss with a universal exponent of $1/3$. Our results provide a mechanistic explanation for observed neural scaling and suggest new directions for improving LLM training efficiency.
STAR-RIS-Assisted Full-Space Angle Estimation via Finite Rate of Innovation
Feb 02, 2026Conventional sensor architectures typically restrict angle estimation to the half-space. By enabling simultaneous transmission and reflection, simultaneously transmitting and reflecting reconfigurable intelligent surfaces (STAR-RIS) can support full-space angle detection. This paper develops a fullspace angle estimation framework by leveraging a finite rate of innovation (FRI) model enabled by STAR-RIS. We distinguish two practical STAR-RIS configurations: (i) an element-wise uniform setting, where all metasurface elements share identical energy-splitting (ES) coefficients and phase differences, and (ii) a nonuniform ES setting, where the phase difference is common across elements while the ES coefficients vary element-wise to increase design flexibility. For each regime, we formulate the corresponding FRI-based signal model and derive the Ziv-Zakai bound (ZZB) for angle estimation. To recover the underlying FRI sampling structure, we develop a proximal-gradient algorithm implemented via alternating projections in matrix space and establish its convergence. Exploiting the recovered FRI structure, we construct an annihilating filter whose zeros encode user angles, enabling gridless estimation via polynomial root finding. Numerical results demonstrate that the proposed methods operate reliably across both configuration regimes and achieve improved angle estimation performance with low overhead.
Are Your Reasoning Models Reasoning or Guessing? A Mechanistic Analysis of Hierarchical Reasoning Models
Jan 15, 2026Hierarchical reasoning model (HRM) achieves extraordinary performance on various reasoning tasks, significantly outperforming large language model-based reasoners. To understand the strengths and potential failure modes of HRM, we conduct a mechanistic study on its reasoning patterns and find three surprising facts: (a) Failure of extremely simple puzzles, e.g., HRM can fail on a puzzle with only one unknown cell. We attribute this failure to the violation of the fixed point property, a fundamental assumption of HRM. (b) "Grokking" dynamics in reasoning steps, i.e., the answer is not improved uniformly, but instead there is a critical reasoning step that suddenly makes the answer correct; (c) Existence of multiple fixed points. HRM "guesses" the first fixed point, which could be incorrect, and gets trapped there for a while or forever. All facts imply that HRM appears to be "guessing" instead of "reasoning". Leveraging this "guessing" picture, we propose three strategies to scale HRM's guesses: data augmentation (scaling the quality of guesses), input perturbation (scaling the number of guesses by leveraging inference randomness), and model bootstrapping (scaling the number of guesses by leveraging training randomness). On the practical side, by combining all methods, we develop Augmented HRM, boosting accuracy on Sudoku-Extreme from 54.5% to 96.9%. On the scientific side, our analysis provides new insights into how reasoning models "reason".
ReSpec: Towards Optimizing Speculative Decoding in Reinforcement Learning Systems
Oct 30, 2025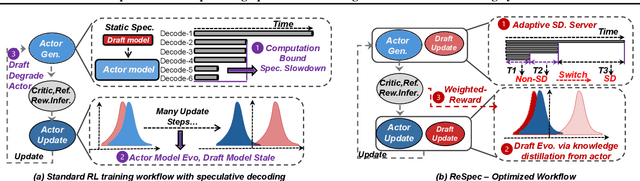

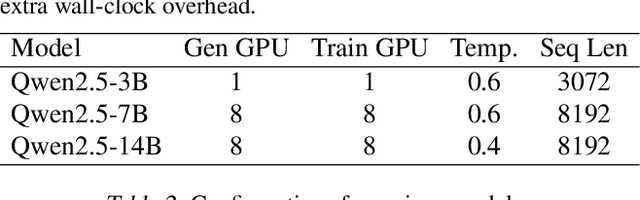

Adapting large language models (LLMs) via reinforcement learning (RL) is often bottlenecked by the generation stage, which can consume over 75\% of the training time. Speculative decoding (SD) accelerates autoregressive generation in serving systems, but its behavior under RL training remains largely unexplored. We identify three critical gaps that hinder the naive integration of SD into RL systems: diminishing speedups at large batch sizes, drafter staleness under continual actor updates, and drafter-induced policy degradation. To address these gaps, we present ReSpec, a system that adapts SD to RL through three complementary mechanisms: dynamically tuning SD configurations, evolving the drafter via knowledge distillation, and weighting updates by rollout rewards. On Qwen models (3B--14B), ReSpec achieves up to 4.5x speedup while preserving reward convergence and training stability, providing a practical solution for efficient RL-based LLM adaptation.