 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpromptu VLA: Open Weights and Open Data for Driving Vision-Language-Action Models
May 29, 2025
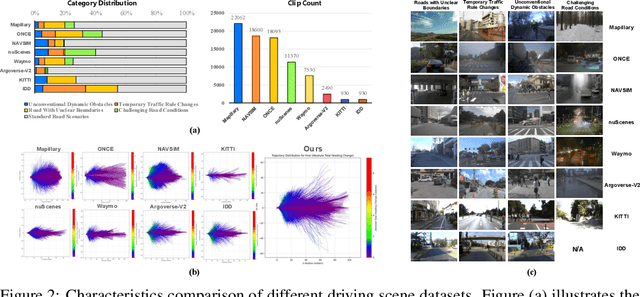
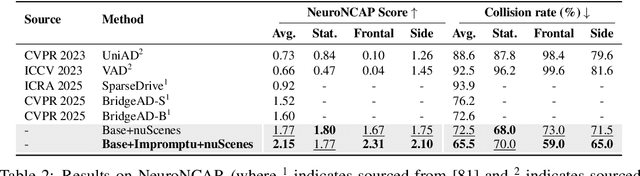

Vision-Language-Action (VLA) models for autonomous driving show promise but falter in unstructured corner case scenarios, largely due to a scarcity of targeted benchmarks. To address this, we introduce Impromptu VLA. Our core contribution is the Impromptu VLA Dataset: over 80,000 meticulously curated video clips, distilled from over 2M source clips sourced from 8 open-source large-scale datasets. This dataset is built upon our novel taxonomy of four challenging unstructured categories and features rich, planning-oriented question-answering annotations and action trajectories. Crucially, experiments demonstrate that VLAs trained with our dataset achieve substantial performance gains on established benchmarks--improving closed-loop NeuroNCAP scores and collision rates, and reaching near state-of-the-art L2 accuracy in open-loop nuScenes trajectory prediction. Furthermore, our Q&A suite serves as an effective diagnostic, revealing clear VLM improvements in perception, prediction, and planning. Our code, data and models are available at https://github.com/ahydchh/Impromptu-VLA.
FB-4D: Spatial-Temporal Coherent Dynamic 3D Content Generation with Feature Banks
Mar 26, 2025With the rapid advancements in diffusion models and 3D generation techniques, dynamic 3D content generation has become a crucial research area. However, achieving high-fidelity 4D (dynamic 3D) generation with strong spatial-temporal consistency remains a challenging task. Inspired by recent findings that pretrained diffusion features capture rich correspondences, we propose FB-4D, a novel 4D generation framework that integrates a Feature Bank mechanism to enhance both spatial and temporal consistency in generated frames. In FB-4D, we store features extracted from previous frames and fuse them into the process of generating subsequent frames, ensuring consistent characteristics across both time and multiple views. To ensure a compact representation, the Feature Bank is updated by a proposed dynamic merging mechanism. Leveraging this Feature Bank, we demonstrate for the first time that generating additional reference sequences through multiple autoregressive iterations can continuously improve generation performance. Experimental results show that FB-4D significantly outperforms existing methods in terms of rendering quality, spatial-temporal consistency, and robustness. It surpasses all multi-view generation tuning-free approaches by a large margin and achieves performance on par with training-based methods.
PartRM: Modeling Part-Level Dynamics with Large Cross-State Reconstruction Model
Mar 25, 2025As interest grows in world models that predict future states from current observations and actions, accurately modeling part-level dynamics has become increasingly relevant for various applications. Existing approaches, such as Puppet-Master, rely on fine-tuning large-scale pre-trained video diffusion models, which are impractical for real-world use due to the limitations of 2D video representation and slow processing times. To overcome these challenges, we present PartRM, a novel 4D reconstruction framework that simultaneously models appearance, geometry, and part-level motion from multi-view images of a static object. PartRM builds upon large 3D Gaussian reconstruction models, leveraging their extensive knowledge of appearance and geometry in static objects. To address data scarcity in 4D, we introduce the PartDrag-4D dataset, providing multi-view observations of part-level dynamics across over 20,000 states. We enhance the model's understanding of interaction conditions with a multi-scale drag embedding module that captures dynamics at varying granularities. To prevent catastrophic forgetting during fine-tuning, we implement a two-stage training process that focuses sequentially on motion and appearance learning. Experimental results show that PartRM establishes a new state-of-the-art in part-level motion learning and can be applied in manipulation tasks in robotics. Our code, data, and models are publicly available to facilitate future research.
Training-Free Model Merging for Multi-target Domain Adaptation
Jul 18, 2024



In this paper, we study multi-target domain adaptation of scene understanding models. While previous methods achieved commendable results through inter-domain consistency losses, they often assumed unrealistic simultaneous access to images from all target domains, overlooking constraints such as data transfer bandwidth limitations and data privacy concerns. Given these challenges, we pose the question: How to merge models adapted independently on distinct domains while bypassing the need for direct access to training data? Our solution to this problem involves two components, merging model parameters and merging model buffers (i.e., normalization layer statistics). For merging model parameters, empirical analyses of mode connectivity surprisingly reveal that linear merging suffices when employing the same pretrained backbone weights for adapting separate models. For merging model buffers, we model the real-world distribution with a Gaussian prior and estimate new statistics from the buffers of separately trained models. Our method is simple yet effective, achieving comparable performance with data combination training baselines, while eliminating the need for accessing training data. Project page: https://air-discover.github.io/ModelMerging
FairDiff: Fair Segmentation with Point-Image Diffusion
Jul 08, 2024

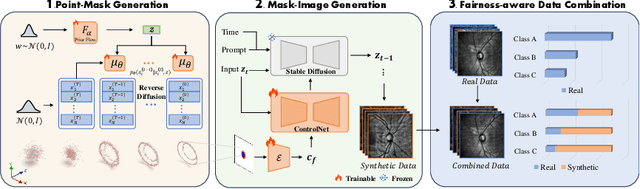

Fairness is an important topic for medical image analysis, driven by the challenge of unbalanced training data among diverse target groups and the societal demand for equitable medical quality. In response to this issue, our research adopts a data-driven strategy-enhancing data balance by integrating synthetic images. However, in terms of generating synthetic images, previous works either lack paired labels or fail to precisely control the boundaries of synthetic images to be aligned with those labels. To address this, we formulate the problem in a joint optimization manner, in which three networks are optimized towards the goal of empirical risk minimization and fairness maximization. On the implementation side, our solution features an innovative Point-Image Diffusion architecture, which leverages 3D point clouds for improved control over mask boundaries through a point-mask-image synthesis pipeline. This method outperforms significantly existing techniques in synthesizing scanning laser ophthalmoscopy (SLO) fundus images. By combining synthetic data with real data during the training phase using a proposed Equal Scale approach, our model achieves superior fairness segmentation performance compared to the state-of-the-art fairness learning models. Code is available at https://github.com/wenyi-li/FairDiff.
SCP-Diff: Photo-Realistic Semantic Image Synthesis with Spatial-Categorical Joint Prior
Mar 14, 2024



Semantic image synthesis (SIS) shows good promises for sensor simulation. However, current best practices in this field, based on GANs, have not yet reached the desired level of quality. As latent diffusion models make significant strides in image generation, we are prompted to evaluate ControlNet, a notable method for its dense control capabilities. Our investigation uncovered two primary issues with its results: the presence of weird sub-structures within large semantic areas and the misalignment of content with the semantic mask. Through empirical study, we pinpointed the cause of these problems as a mismatch between the noised training data distribution and the standard normal prior applied at the inference stage. To address this challenge, we developed specific noise priors for SIS, encompassing spatial, categorical, and a novel spatial-categorical joint prior for inference. This approach, which we have named SCP-Diff, has yielded exceptional results, achieving an FID of 10.53 on Cityscapes and 12.66 on ADE20K.The code and models can be accessed via the project page.
Assessing and Understanding Creativity in Large Language Models
Jan 23, 2024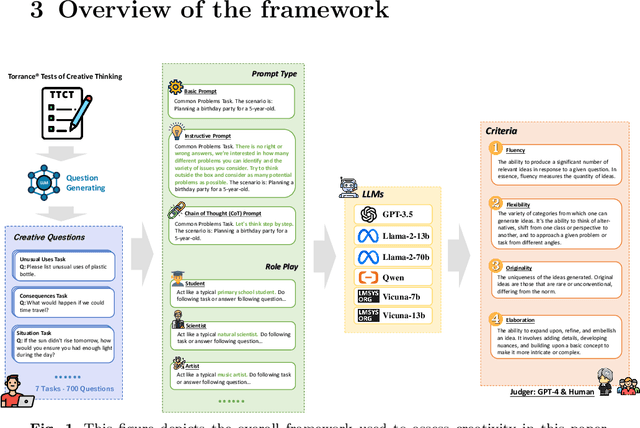
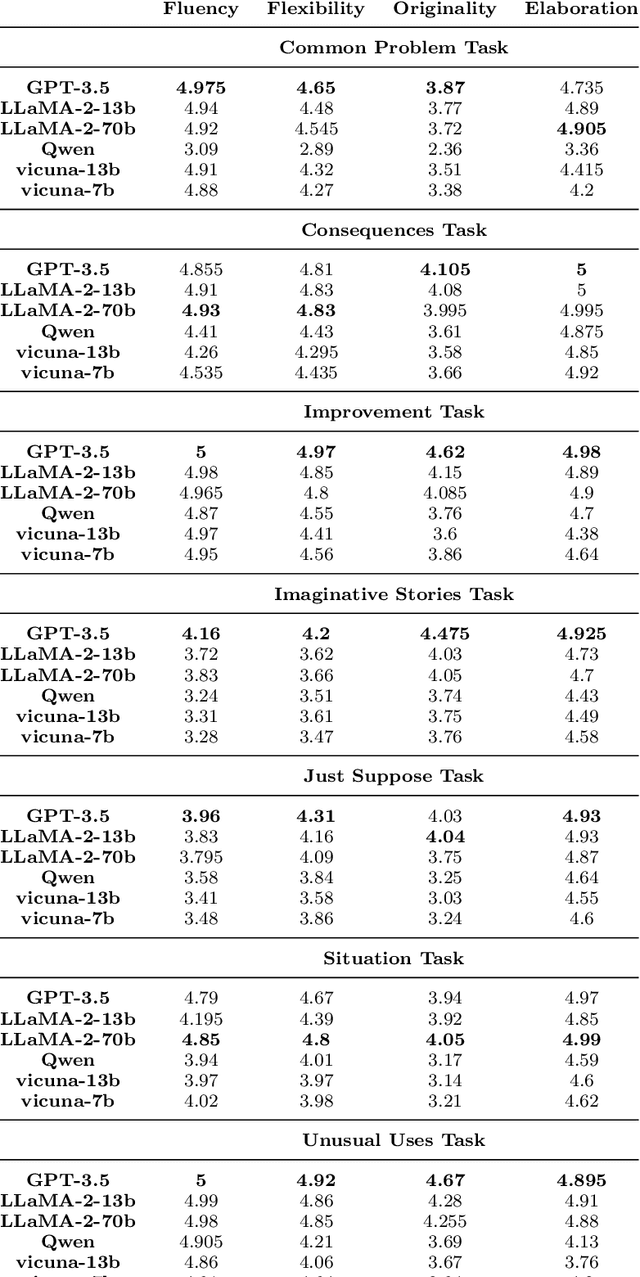
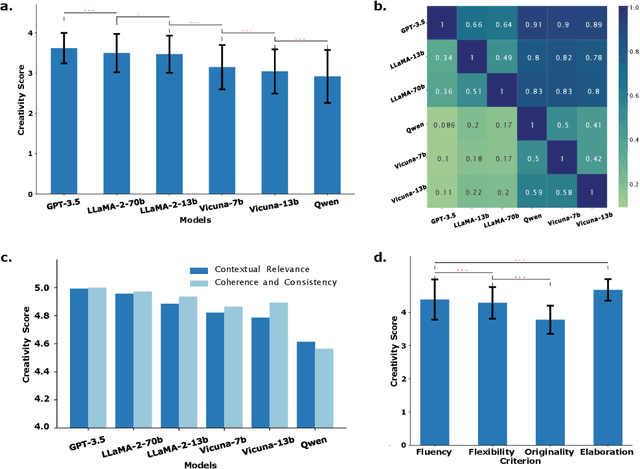
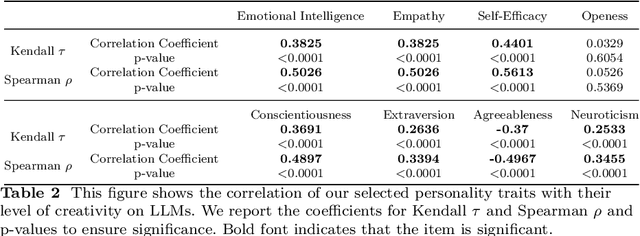
In the field of natural language processing, the rapid development of large language model (LLM) has attracted more and more attention. LLMs have shown a high level of creativity in various tasks, but the methods for assessing such creativity are inadequate. The assessment of LLM creativity needs to consider differences from humans, requiring multi-dimensional measurement while balancing accuracy and efficiency. This paper aims to establish an efficient framework for assessing the level of creativity in LLMs. By adapting the modified Torrance Tests of Creative Thinking, the research evaluates the creative performance of various LLMs across 7 tasks, emphasizing 4 criteria including Fluency, Flexibility, Originality, and Elaboration. In this context, we develop a comprehensive dataset of 700 questions for testing and an LLM-based evaluation method. In addition, this study presents a novel analysis of LLMs' responses to diverse prompts and role-play situations. We found that the creativity of LLMs primarily falls short in originality, while excelling in elaboration. Besides, the use of prompts and the role-play settings of the model significantly influence creativity. Additionally, the experimental results also indicate that collaboration among multiple LLMs can enhance originality. Notably, our findings reveal a consensus between human evaluations and LLMs regarding the personality traits that influence creativity. The findings underscore the significant impact of LLM design on creativity and bridges artificial intelligence and human creativity, offering insights into LLMs' creativity and potential applications.
The Brain-Inspired Decoder for Natural Visual Image Reconstruction
Jul 18, 2022
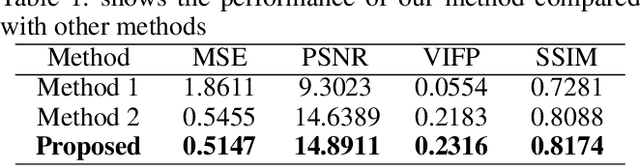

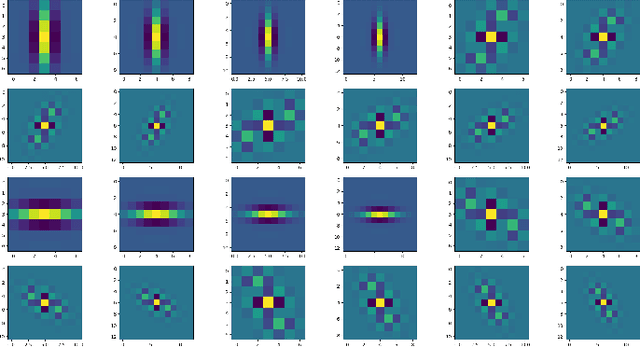
Decoding images from brain activity has been a challenge. Owing to the development of deep learning, there are available tools to solve this problem. The decoded image, which aims to map neural spike trains to low-level visual features and high-level semantic information space. Recently, there are a few studies of decoding from spike trains, however, these studies pay less attention to the foundations of neuroscience and there are few studies that merged receptive field into visual image reconstruction. In this paper, we propose a deep learning neural network architecture with biological properties to reconstruct visual image from spike trains. As far as we know, we implemented a method that integrated receptive field property matrix into loss function at the first time. Our model is an end-to-end decoder from neural spike trains to images. We not only merged Gabor filter into auto-encoder which used to generate images but also proposed a loss function with receptive field properties. We evaluated our decoder on two datasets which contain macaque primary visual cortex neural spikes and salamander retina ganglion cells (RGCs) spikes. Our results show that our method can effectively combine receptive field features to reconstruct images, providing a new approach to visual reconstruction based on neural information.
A Spiking Neural Network based on Neural Manifold for Augmenting Intracortical Brain-Computer Interface Data
Mar 26, 2022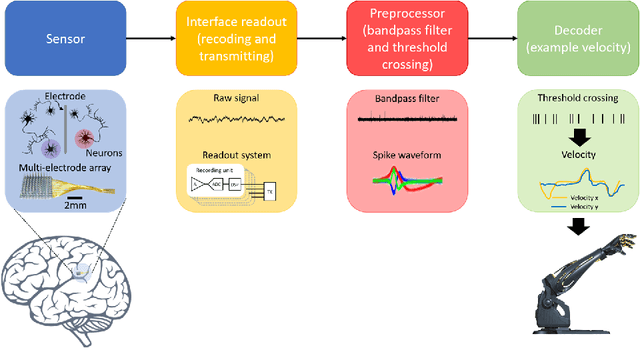
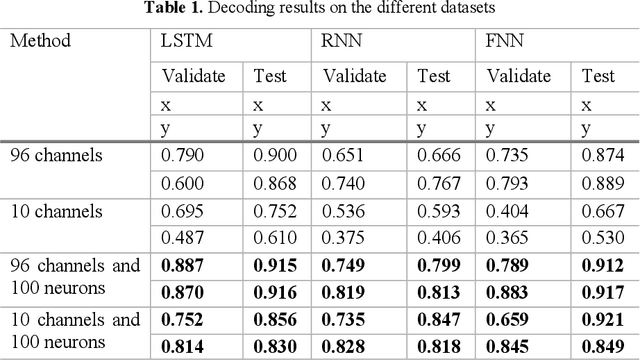
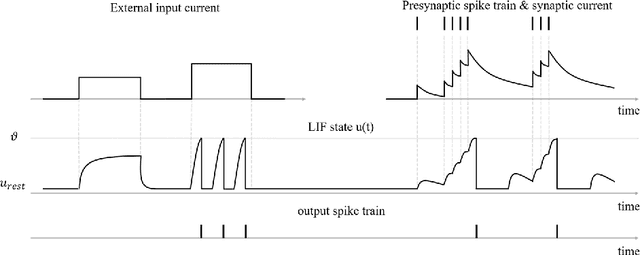
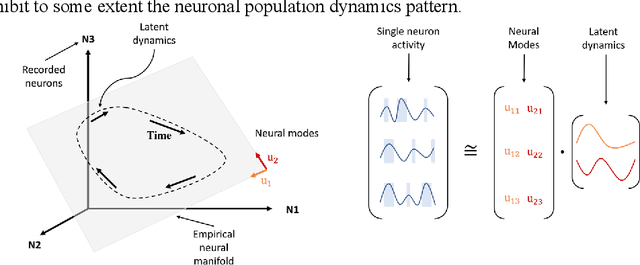
Brain-computer interfaces (BCIs), transform neural signals in the brain into in-structions to control external devices. However, obtaining sufficient training data is difficult as well as limited. With the advent of advanced machine learning methods, the capability of brain-computer interfaces has been enhanced like never before, however, these methods require a large amount of data for training and thus require data augmentation of the limited data available. Here, we use spiking neural networks (SNN) as data generators. It is touted as the next-generation neu-ral network and is considered as one of the algorithms oriented to general artifi-cial intelligence because it borrows the neural information processing from bio-logical neurons. We use the SNN to generate neural spike information that is bio-interpretable and conforms to the intrinsic patterns in the original neural data. Ex-periments show that the model can directly synthesize new spike trains, which in turn improves the generalization ability of the BCI decoder. Both the input and output of the spiking neural model are spike information, which is a brain-inspired intelligence approach that can be better integrated with BCI in the future.