 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQiMeng-SALV: Signal-Aware Learning for Verilog Code Generation
Oct 22, 2025The remarkable progress of Large Language Models (LLMs) presents promising opportunities for Verilog code generation which is significantly important for automated circuit design. The lacking of meaningful functional rewards hinders the preference optimization based on Reinforcement Learning (RL) for producing functionally correct Verilog code. In this paper, we propose Signal-Aware Learning for Verilog code generation (QiMeng-SALV) by leveraging code segments of functionally correct output signal to optimize RL training. Considering Verilog code specifies the structural interconnection of hardware gates and wires so that different output signals are independent, the key insight of QiMeng-SALV is to extract verified signal-aware implementations in partially incorrect modules, so as to enhance the extraction of meaningful functional rewards. Roughly, we verify the functional correctness of signals in generated module by comparing with that of reference module in the training data. Then abstract syntax tree (AST) is employed to identify signal-aware code segments which can provide meaningful functional rewards from erroneous modules. Finally, we introduce signal-aware DPO which is optimized on the correct signal-level code segments, thereby preventing noise and interference from incorrect signals. The proposed QiMeng-SALV underscores the paradigm shift from conventional module-level to fine-grained signal-level optimization in Verilog code generation, addressing the issue of insufficient functional rewards. Experiments demonstrate that our method achieves state-of-the-art performance on VerilogEval and RTLLM, with a 7B parameter model matching the performance of the DeepSeek v3 671B model and significantly outperforming the leading open-source model CodeV trained on the same dataset. Our code is available at https://github.com/zy1xxx/SALV.
Object-Level Verbalized Confidence Calibration in Vision-Language Models via Semantic Perturbation
Apr 21, 2025



Vision-language models (VLMs) excel in various multimodal tasks but frequently suffer from poor calibration, resulting in misalignment between their verbalized confidence and response correctness. This miscalibration undermines user trust, especially when models confidently provide incorrect or fabricated information. In this work, we propose a novel Confidence Calibration through Semantic Perturbation (CSP) framework to improve the calibration of verbalized confidence for VLMs in response to object-centric queries. We first introduce a perturbed dataset where Gaussian noise is applied to the key object regions to simulate visual uncertainty at different confidence levels, establishing an explicit mapping between visual ambiguity and confidence levels. We further enhance calibration through a two-stage training process combining supervised fine-tuning on the perturbed dataset with subsequent preference optimization. Extensive experiments on popular benchmarks demonstrate that our method significantly improves the alignment between verbalized confidence and response correctness while maintaining or enhancing overall task performance. These results highlight the potential of semantic perturbation as a practical tool for improving the reliability and interpretability of VLMs.
Towards Analyzing and Mitigating Sycophancy in Large Vision-Language Models
Aug 21, 2024



Large Vision-Language Models (LVLMs) have shown significant capability in vision-language understanding. However, one critical issue that persists in these models is sycophancy, which means models are unduly influenced by leading or deceptive prompts, resulting in biased outputs and hallucinations. Despite the progress in LVLMs, evaluating and mitigating sycophancy is yet much under-explored. In this work, we fill this gap by systematically analyzing sycophancy on various VL benchmarks with curated leading queries and further proposing a text contrastive decoding method for mitigation. While the specific sycophantic behavior varies significantly among models, our analysis reveals the severe deficiency of all LVLMs in resilience of sycophancy across various tasks. For improvement, we propose Leading Query Contrastive Decoding (LQCD), a model-agnostic method focusing on calibrating the LVLMs' over-reliance on leading cues by identifying and suppressing the probabilities of sycophancy tokens at the decoding stage. Extensive experiments show that LQCD effectively mitigate sycophancy, outperforming both prompt engineering methods and common methods for hallucination mitigation. We further demonstrate that LQCD does not hurt but even slightly improves LVLMs' responses to neutral queries, suggesting it being a more effective strategy for general-purpose decoding but not limited to sycophancy.
Assessing and Understanding Creativity in Large Language Models
Jan 23, 2024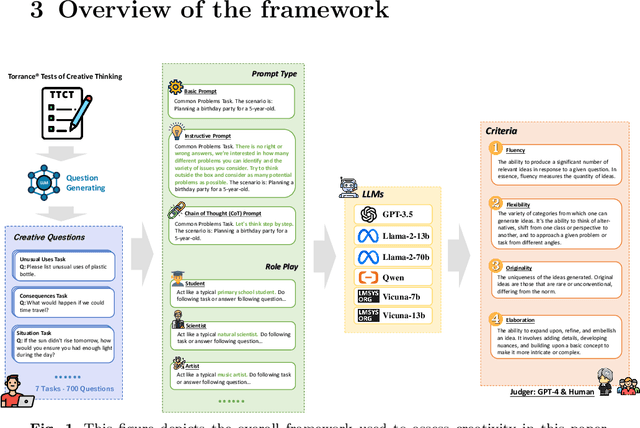
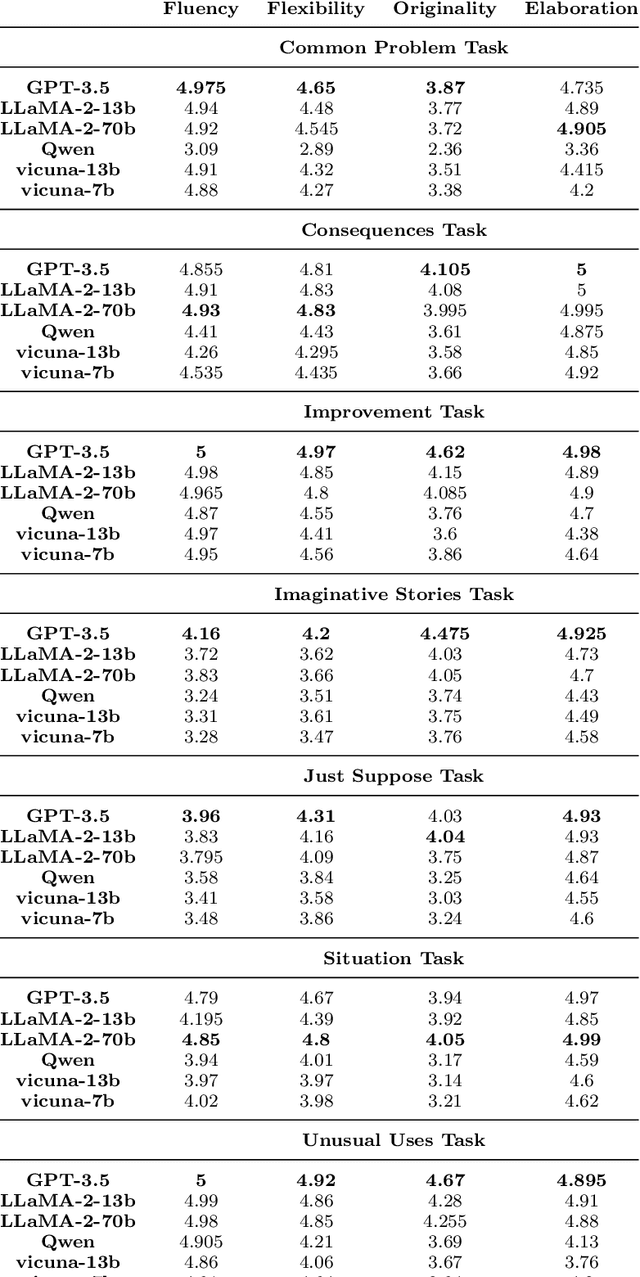
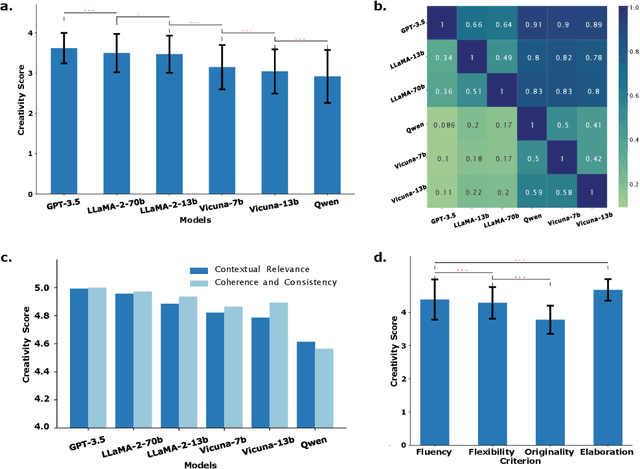
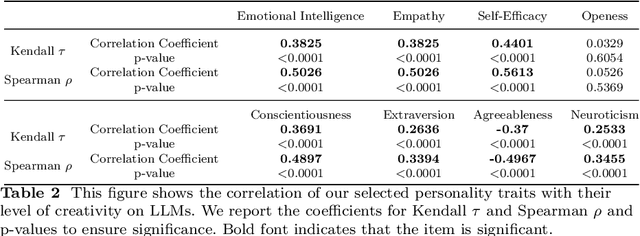
In the field of natural language processing, the rapid development of large language model (LLM) has attracted more and more attention. LLMs have shown a high level of creativity in various tasks, but the methods for assessing such creativity are inadequate. The assessment of LLM creativity needs to consider differences from humans, requiring multi-dimensional measurement while balancing accuracy and efficiency. This paper aims to establish an efficient framework for assessing the level of creativity in LLMs. By adapting the modified Torrance Tests of Creative Thinking, the research evaluates the creative performance of various LLMs across 7 tasks, emphasizing 4 criteria including Fluency, Flexibility, Originality, and Elaboration. In this context, we develop a comprehensive dataset of 700 questions for testing and an LLM-based evaluation method. In addition, this study presents a novel analysis of LLMs' responses to diverse prompts and role-play situations. We found that the creativity of LLMs primarily falls short in originality, while excelling in elaboration. Besides, the use of prompts and the role-play settings of the model significantly influence creativity. Additionally, the experimental results also indicate that collaboration among multiple LLMs can enhance originality. Notably, our findings reveal a consensus between human evaluations and LLMs regarding the personality traits that influence creativity. The findings underscore the significant impact of LLM design on creativity and bridges artificial intelligence and human creativity, offering insights into LLMs' creativity and potential applications.
AutoDES: AutoML Pipeline Generation of Classification with Dynamic Ensemble Strategy Selection
Jan 01, 2022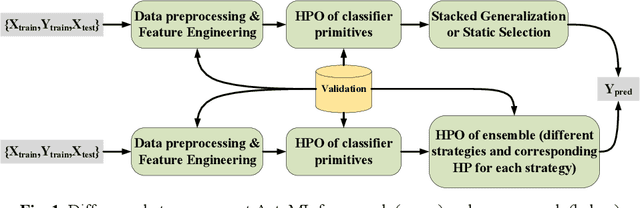

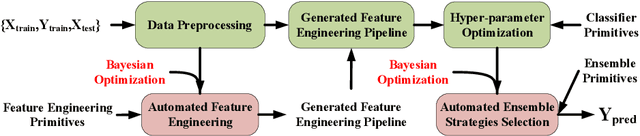

Automating machine learning has achieved remarkable technological developments in recent years, and building an automated machine learning pipeline is now an essential task. The model ensemble is the technique of combining multiple models to get a better and more robust model. However, existing automated machine learning tends to be simplistic in handling the model ensemble, where the ensemble strategy is fixed, such as stacked generalization. There have been many techniques on different ensemble methods, especially ensemble selection, and the fixed ensemble strategy limits the upper limit of the model's performance. In this article, we present a novel framework for automated machine learning. Our framework incorporates advances in dynamic ensemble selection, and to our best knowledge, our approach is the first in the field of AutoML to search and optimize ensemble strategies. In the comparison experiments, our method outperforms the state-of-the-art automated machine learning frameworks with the same CPU time in 42 classification datasets from the OpenML platform. Ablation experiments on our framework validate the effectiveness of our proposed method.