 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutual-Supervised Learning for Sequential-to-Parallel Code Translation
Jun 11, 2025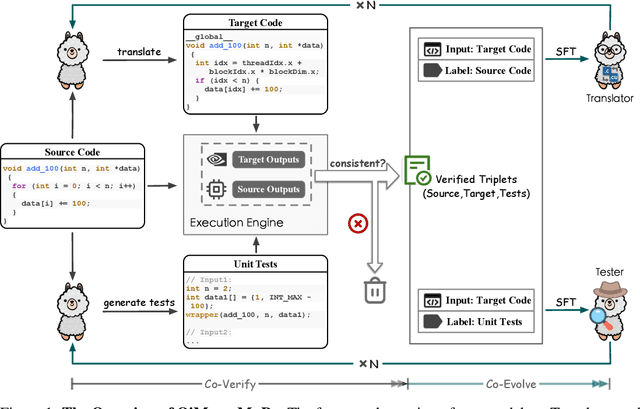
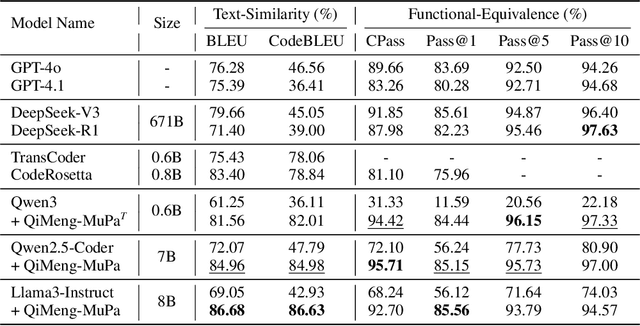
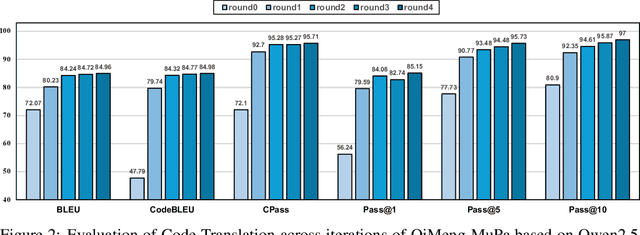
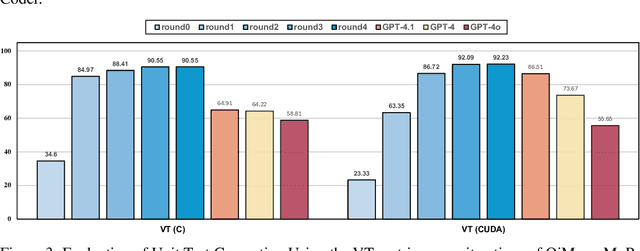
The rise of GPU-based high-performance computing (HPC) has driven the widespread adoption of parallel programming models such as CUDA. Yet, the inherent complexity of parallel programming creates a demand for the automated sequential-to-parallel approaches. However, data scarcity poses a significant challenge for machine learning-based sequential-to-parallel code translation. Although recent back-translation methods show promise, they still fail to ensure functional equivalence in the translated code. In this paper, we propose a novel Mutual-Supervised Learning (MSL) framework for sequential-to-parallel code translation to address the functional equivalence issue. MSL consists of two models, a Translator and a Tester. Through an iterative loop consisting of Co-verify and Co-evolve steps, the Translator and the Tester mutually generate data for each other and improve collectively. The Tester generates unit tests to verify and filter functionally equivalent translated code, thereby evolving the Translator, while the Translator generates translated code as augmented input to evolve the Tester. Experimental results demonstrate that MuSL significantly enhances the performance of the base model: when applied to Qwen2.5-Coder, it not only improves Pass@1 by up to 28.91% and boosts Tester performance by 68.90%, but also outperforms the previous state-of-the-art method CodeRosetta by 1.56 and 6.92 in BLEU and CodeBLEU scores, while achieving performance comparable to DeepSeek-R1 and GPT-4.1. Our code is available at https://github.com/kcxain/musl.
Towards Analyzing and Mitigating Sycophancy in Large Vision-Language Models
Aug 21, 2024



Large Vision-Language Models (LVLMs) have shown significant capability in vision-language understanding. However, one critical issue that persists in these models is sycophancy, which means models are unduly influenced by leading or deceptive prompts, resulting in biased outputs and hallucinations. Despite the progress in LVLMs, evaluating and mitigating sycophancy is yet much under-explored. In this work, we fill this gap by systematically analyzing sycophancy on various VL benchmarks with curated leading queries and further proposing a text contrastive decoding method for mitigation. While the specific sycophantic behavior varies significantly among models, our analysis reveals the severe deficiency of all LVLMs in resilience of sycophancy across various tasks. For improvement, we propose Leading Query Contrastive Decoding (LQCD), a model-agnostic method focusing on calibrating the LVLMs' over-reliance on leading cues by identifying and suppressing the probabilities of sycophancy tokens at the decoding stage. Extensive experiments show that LQCD effectively mitigate sycophancy, outperforming both prompt engineering methods and common methods for hallucination mitigation. We further demonstrate that LQCD does not hurt but even slightly improves LVLMs' responses to neutral queries, suggesting it being a more effective strategy for general-purpose decoding but not limited to sycophancy.
I run as fast as a rabbit, can you? A Multilingual Simile Dialogue Dataset
Jun 09, 2023



A simile is a figure of speech that compares two different things (called the tenor and the vehicle) via shared properties. The tenor and the vehicle are usually connected with comparator words such as "like" or "as". The simile phenomena are unique and complex in a real-life dialogue scene where the tenor and the vehicle can be verbal phrases or sentences, mentioned by different speakers, exist in different sentences, or occur in reversed order. However, the current simile research usually focuses on similes in a triplet tuple (tenor, property, vehicle) or a single sentence where the tenor and vehicle are usually entities or noun phrases, which could not reflect complex simile phenomena in real scenarios. In this paper, we propose a novel and high-quality multilingual simile dialogue (MSD) dataset to facilitate the study of complex simile phenomena. The MSD is the largest manually annotated simile data ($\sim$20K) and it contains both English and Chinese data. Meanwhile, the MSD data can also be used on dialogue tasks to test the ability of dialogue systems when using similes. We design 3 simile tasks (recognition, interpretation, and generation) and 2 dialogue tasks (retrieval and generation) with MSD. For each task, we provide experimental results from strong pre-trained or state-of-the-art models. The experiments demonstrate the challenge of MSD and we have released the data/code on GitHub.