 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnstructured Text Enhanced Open-domain Dialogue System: A Systematic Survey
Nov 14, 2024



Incorporating external knowledge into dialogue generation has been proven to benefit the performance of an open-domain Dialogue System (DS), such as generating informative or stylized responses, controlling conversation topics. In this article, we study the open-domain DS that uses unstructured text as external knowledge sources (\textbf{U}nstructured \textbf{T}ext \textbf{E}nhanced \textbf{D}ialogue \textbf{S}ystem, \textbf{UTEDS}). The existence of unstructured text entails distinctions between UTEDS and traditional data-driven DS and we aim to analyze these differences. We first give the definition of the UTEDS related concepts, then summarize the recently released datasets and models. We categorize UTEDS into Retrieval and Generative models and introduce them from the perspective of model components. The retrieval models consist of Fusion, Matching, and Ranking modules, while the generative models comprise Dialogue and Knowledge Encoding, Knowledge Selection, and Response Generation modules. We further summarize the evaluation methods utilized in UTEDS and analyze the current models' performance. At last, we discuss the future development trends of UTEDS, hoping to inspire new research in this field.
* 45 pages, 3 Figures, 11 Tables
Policy-driven Knowledge Selection and Response Generation for Document-grounded Dialogue
Oct 21, 2024

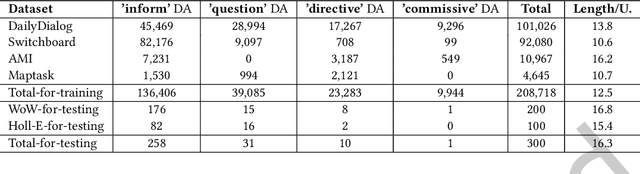

Document-grounded dialogue (DGD) uses documents as external knowledge for dialogue generation. Correctly understanding the dialogue context is crucial for selecting knowledge from the document and generating proper responses. In this paper, we propose using a dialogue policy to help the dialogue understanding in DGD. Our dialogue policy consists of two kinds of guiding signals: utterance function and topic transfer intent. The utterance function reflects the purpose and style of an utterance, and the topic transfer intent reflects the topic and content of an utterance. We propose a novel framework exploiting our dialogue policy for two core tasks in DGD, namely knowledge selection (KS) and response generation (RG). The framework consists of two modules: the Policy planner leverages policy-aware dialogue representation to select knowledge and predict the policy of the response; the generator uses policy/knowledge-aware dialogue representation for response generation. Our policy-driven model gets state-of-the-art performance on three public benchmarks and we provide a detailed analysis of the experimental results. Our code/data will be released on GitHub.
* 29 pages, 9 figures, 14 tables, TOIS 2024
Through the Lens of Core Competency: Survey on Evaluation of Large Language Models
Aug 15, 2023From pre-trained language model (PLM) to large language model (LLM), the field of natural language processing (NLP) has witnessed steep performance gains and wide practical uses. The evaluation of a research field guides its direction of improvement. However, LLMs are extremely hard to thoroughly evaluate for two reasons. First of all, traditional NLP tasks become inadequate due to the excellent performance of LLM. Secondly, existing evaluation tasks are difficult to keep up with the wide range of applications in real-world scenarios. To tackle these problems, existing works proposed various benchmarks to better evaluate LLMs. To clarify the numerous evaluation tasks in both academia and industry, we investigate multiple papers concerning LLM evaluations. We summarize 4 core competencies of LLM, including reasoning, knowledge, reliability, and safety. For every competency, we introduce its definition, corresponding benchmarks, and metrics. Under this competency architecture, similar tasks are combined to reflect corresponding ability, while new tasks can also be easily added into the system. Finally, we give our suggestions on the future direction of LLM's evaluation.
I run as fast as a rabbit, can you? A Multilingual Simile Dialogue Dataset
Jun 09, 2023



A simile is a figure of speech that compares two different things (called the tenor and the vehicle) via shared properties. The tenor and the vehicle are usually connected with comparator words such as "like" or "as". The simile phenomena are unique and complex in a real-life dialogue scene where the tenor and the vehicle can be verbal phrases or sentences, mentioned by different speakers, exist in different sentences, or occur in reversed order. However, the current simile research usually focuses on similes in a triplet tuple (tenor, property, vehicle) or a single sentence where the tenor and vehicle are usually entities or noun phrases, which could not reflect complex simile phenomena in real scenarios. In this paper, we propose a novel and high-quality multilingual simile dialogue (MSD) dataset to facilitate the study of complex simile phenomena. The MSD is the largest manually annotated simile data ($\sim$20K) and it contains both English and Chinese data. Meanwhile, the MSD data can also be used on dialogue tasks to test the ability of dialogue systems when using similes. We design 3 simile tasks (recognition, interpretation, and generation) and 2 dialogue tasks (retrieval and generation) with MSD. For each task, we provide experimental results from strong pre-trained or state-of-the-art models. The experiments demonstrate the challenge of MSD and we have released the data/code on GitHub.
SelF-Eval: Self-supervised Fine-grained Dialogue Evaluation
Aug 23, 2022



This paper introduces a novel Self-supervised Fine-grained Dialogue Evaluation framework (SelF-Eval). The core idea is to model the correlation between turn quality and the entire dialogue quality. We first propose a novel automatic data construction method that can automatically assign fine-grained scores for arbitrarily dialogue data. Then we train \textbf{SelF-Eval} with a multi-level contrastive learning schema which helps to distinguish different score levels. Experimental results on multiple benchmarks show that SelF-Eval is highly consistent with human evaluations and better than the state-of-the-art models. We give a detailed analysis of the experiments in this paper. Our code and data will be published on GitHub.
A Compare Aggregate Transformer for Understanding Document-grounded Dialogue
Oct 01, 2020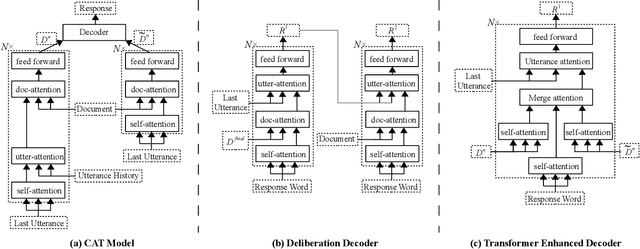
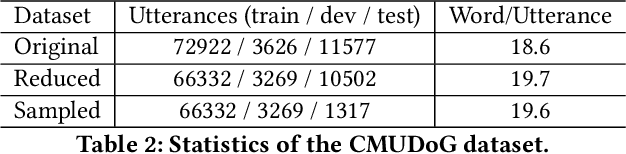
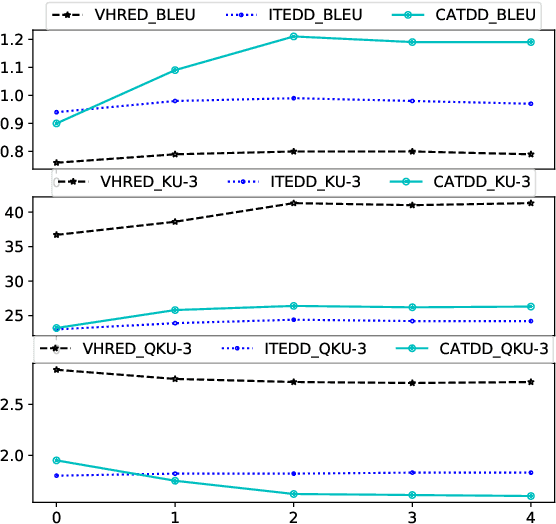

Unstructured documents serving as external knowledge of the dialogues help to generate more informative responses. Previous research focused on knowledge selection (KS) in the document with dialogue. However, dialogue history that is not related to the current dialogue may introduce noise in the KS processing. In this paper, we propose a Compare Aggregate Transformer (CAT) to jointly denoise the dialogue context and aggregate the document information for response generation. We designed two different comparison mechanisms to reduce noise (before and during decoding). In addition, we propose two metrics for evaluating document utilization efficiency based on word overlap. Experimental results on the CMUDoG dataset show that the proposed CAT model outperforms the state-of-the-art approach and strong baselines.
A Survey of Document Grounded Dialogue Systems (DGDS)
Apr 17, 2020



Dialogue system (DS) attracts great attention from industry and academia because of its wide application prospects. Researchers usually divide the DS according to the function. However, many conversations require the DS to switch between different functions. For example, movie discussion can change from chit-chat to QA, the conversational recommendation can transform from chit-chat to recommendation, etc. Therefore, classification according to functions may not be enough to help us appreciate the current development trend. We classify the DS based on background knowledge. Specifically, study the latest DS based on the unstructured document(s). We define Document Grounded Dialogue System (DGDS) as the DS that the dialogues are centering on the given document(s). The DGDS can be used in scenarios such as talking over merchandise against product Manual, commenting on news reports, etc. We believe that extracting unstructured document(s) information is the future trend of the DS because a great amount of human knowledge lies in these document(s). The research of the DGDS not only possesses a broad application prospect but also facilitates AI to better understand human knowledge and natural language. We analyze the classification, architecture, datasets, models, and future development trends of the DGDS, hoping to help researchers in this field.
Dynamic Feature Generation Network for Answer Selection
Dec 13, 2018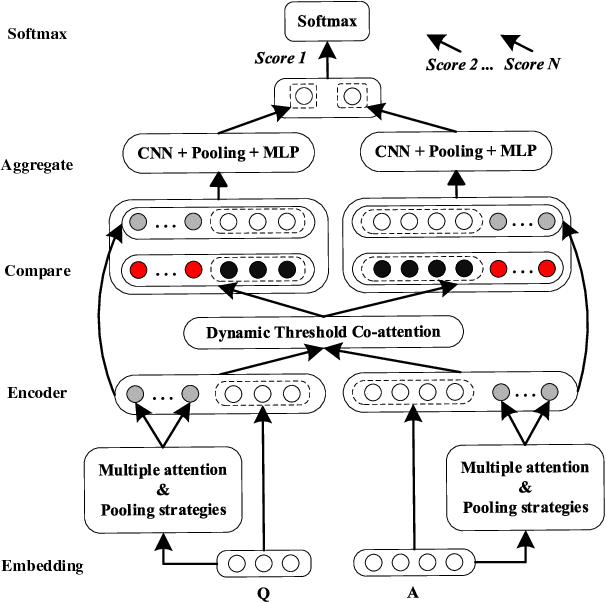



Extracting appropriate features to represent a corpus is an important task for textual mining. Previous attention based work usually enhance feature at the lexical level, which lacks the exploration of feature augmentation at the sentence level. In this paper, we exploit a Dynamic Feature Generation Network (DFGN) to solve this problem. Specifically, DFGN generates features based on a variety of attention mechanisms and attaches features to sentence representation. Then a thresholder is designed to filter the mined features automatically. DFGN extracts the most significant characteristics from datasets to keep its practicability and robustness. Experimental results on multiple well-known answer selection datasets show that our proposed approach significantly outperforms state-of-the-art baselines. We give a detailed analysis of the experiments to illustrate why DFGN provides excellent retrieval and interpretative ability.