 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYunque DeepResearch Technical Report
Jan 27, 2026Deep research has emerged as a transformative capability for autonomous agents, empowering Large Language Models to navigate complex, open-ended tasks. However, realizing its full potential is hindered by critical limitations, including escalating contextual noise in long-horizon tasks, fragility leading to cascading errors, and a lack of modular extensibility. To address these challenges, we introduce Yunque DeepResearch, a hierarchical, modular, and robust framework. The architecture is characterized by three key components: (1) a centralized Multi-Agent Orchestration System that routes subtasks to an Atomic Capability Pool of tools and specialized sub-agents; (2) a Dynamic Context Management mechanism that structures completed sub-goals into semantic summaries to mitigate information overload; and (3) a proactive Supervisor Module that ensures resilience through active anomaly detection and context pruning. Yunque DeepResearch achieves state-of-the-art performance across a range of agentic deep research benchmarks, including GAIA, BrowseComp, BrowseComp-ZH, and Humanity's Last Exam. We open-source the framework, reproducible implementations, and application cases to empower the community.
Reinforcement learning-guided optimization of critical current in high-temperature superconductors
Oct 25, 2025High-temperature superconductors are essential for next-generation energy and quantum technologies, yet their performance is often limited by the critical current density ($J_c$), which is strongly influenced by microstructural defects. Optimizing $J_c$ through defect engineering is challenging due to the complex interplay of defect type, density, and spatial correlation. Here we present an integrated workflow that combines reinforcement learning (RL) with time-dependent Ginzburg-Landau (TDGL) simulations to autonomously identify optimal defect configurations that maximize $J_c$. In our framework, TDGL simulations generate current-voltage characteristics to evaluate $J_c$, which serves as the reward signal that guides the RL agent to iteratively refine defect configurations. We find that the agent discovers optimal defect densities and correlations in two-dimensional thin-film geometries, enhancing vortex pinning and $J_c$ relative to the pristine thin-film, approaching 60\% of theoretical depairing limit with up to 15-fold enhancement compared to random initialization. This RL-driven approach provides a scalable strategy for defect engineering, with broad implications for advancing HTS applications in fusion magnets, particle accelerators, and other high-field technologies.
ReVision: A Dataset and Baseline VLM for Privacy-Preserving Task-Oriented Visual Instruction Rewriting
Feb 20, 2025



Efficient and privacy-preserving multimodal interaction is essential as AR, VR, and modern smartphones with powerful cameras become primary interfaces for human-computer communication. Existing powerful large vision-language models (VLMs) enabling multimodal interaction often rely on cloud-based processing, raising significant concerns about (1) visual privacy by transmitting sensitive vision data to servers, and (2) their limited real-time, on-device usability. This paper explores Visual Instruction Rewriting, a novel approach that transforms multimodal instructions into text-only commands, allowing seamless integration of lightweight on-device instruction rewriter VLMs (250M parameters) with existing conversational AI systems, enhancing vision data privacy. To achieve this, we present a dataset of over 39,000 examples across 14 domains and develop a compact VLM, pretrained on image captioning datasets and fine-tuned for instruction rewriting. Experimental results, evaluated through NLG metrics such as BLEU, METEOR, and ROUGE, along with semantic parsing analysis, demonstrate that even a quantized version of the model (<500MB storage footprint) can achieve effective instruction rewriting, thus enabling privacy-focused, multimodal AI applications.
AI-driven materials design: a mini-review
Feb 05, 2025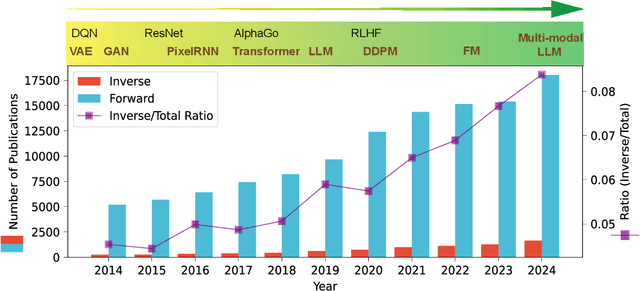
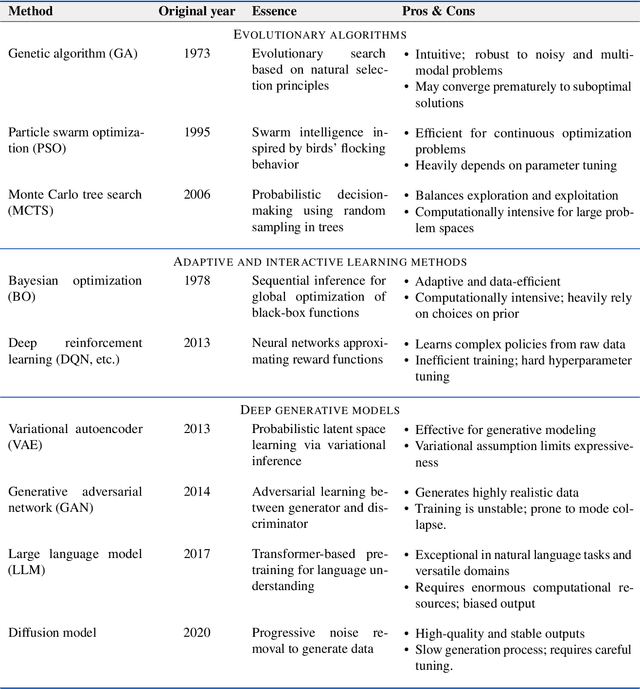
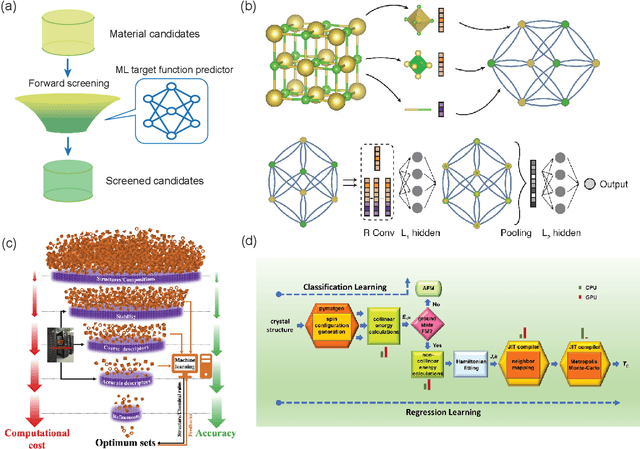
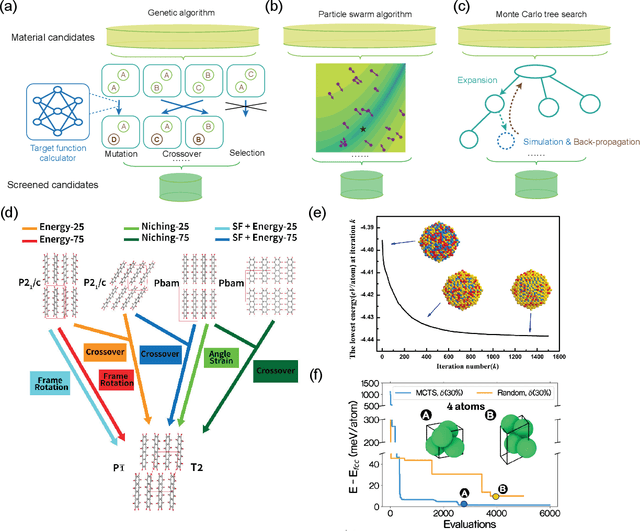
Materials design is an important component of modern science and technology, yet traditional approaches rely heavily on trial-and-error and can be inefficient. Computational techniques, enhanced by modern artificial intelligence (AI), have greatly accelerated the design of new materials. Among these approaches, inverse design has shown great promise in designing materials that meet specific property requirements. In this mini-review, we summarize key computational advancements for materials design over the past few decades. We follow the evolution of relevant materials design techniques, from high-throughput forward machine learning (ML) methods and evolutionary algorithms, to advanced AI strategies like reinforcement learning (RL) and deep generative models. We highlight the paradigm shift from conventional screening approaches to inverse generation driven by deep generative models. Finally, we discuss current challenges and future perspectives of materials inverse design. This review may serve as a brief guide to the approaches, progress, and outlook of designing future functional materials with technological relevance.
Unstructured Text Enhanced Open-domain Dialogue System: A Systematic Survey
Nov 14, 2024



Incorporating external knowledge into dialogue generation has been proven to benefit the performance of an open-domain Dialogue System (DS), such as generating informative or stylized responses, controlling conversation topics. In this article, we study the open-domain DS that uses unstructured text as external knowledge sources (\textbf{U}nstructured \textbf{T}ext \textbf{E}nhanced \textbf{D}ialogue \textbf{S}ystem, \textbf{UTEDS}). The existence of unstructured text entails distinctions between UTEDS and traditional data-driven DS and we aim to analyze these differences. We first give the definition of the UTEDS related concepts, then summarize the recently released datasets and models. We categorize UTEDS into Retrieval and Generative models and introduce them from the perspective of model components. The retrieval models consist of Fusion, Matching, and Ranking modules, while the generative models comprise Dialogue and Knowledge Encoding, Knowledge Selection, and Response Generation modules. We further summarize the evaluation methods utilized in UTEDS and analyze the current models' performance. At last, we discuss the future development trends of UTEDS, hoping to inspire new research in this field.
* 45 pages, 3 Figures, 11 Tables
Large Language Model-Guided Prediction Toward Quantum Materials Synthesis
Oct 28, 2024



The synthesis of inorganic crystalline materials is essential for modern technology, especially in quantum materials development. However, designing efficient synthesis workflows remains a significant challenge due to the precise experimental conditions and extensive trial and error. Here, we present a framework using large language models (LLMs) to predict synthesis pathways for inorganic materials, including quantum materials. Our framework contains three models: LHS2RHS, predicting products from reactants; RHS2LHS, predicting reactants from products; and TGT2CEQ, generating full chemical equations for target compounds. Fine-tuned on a text-mined synthesis database, our model raises accuracy from under 40% with pretrained models, to under 80% using conventional fine-tuning, and further to around 90% with our proposed generalized Tanimoto similarity, while maintaining robust to additional synthesis steps. Our model further demonstrates comparable performance across materials with varying degrees of quantumness quantified using quantum weight, indicating that LLMs offer a powerful tool to predict balanced chemical equations for quantum materials discovery.
Policy-driven Knowledge Selection and Response Generation for Document-grounded Dialogue
Oct 21, 2024

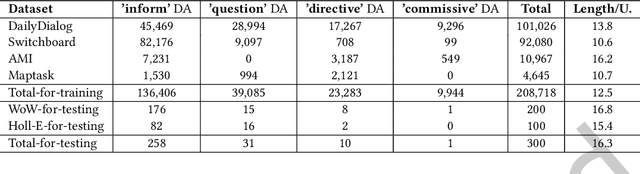

Document-grounded dialogue (DGD) uses documents as external knowledge for dialogue generation. Correctly understanding the dialogue context is crucial for selecting knowledge from the document and generating proper responses. In this paper, we propose using a dialogue policy to help the dialogue understanding in DGD. Our dialogue policy consists of two kinds of guiding signals: utterance function and topic transfer intent. The utterance function reflects the purpose and style of an utterance, and the topic transfer intent reflects the topic and content of an utterance. We propose a novel framework exploiting our dialogue policy for two core tasks in DGD, namely knowledge selection (KS) and response generation (RG). The framework consists of two modules: the Policy planner leverages policy-aware dialogue representation to select knowledge and predict the policy of the response; the generator uses policy/knowledge-aware dialogue representation for response generation. Our policy-driven model gets state-of-the-art performance on three public benchmarks and we provide a detailed analysis of the experimental results. Our code/data will be released on GitHub.
* 29 pages, 9 figures, 14 tables, TOIS 2024
TRACE: Temporal Grounding Video LLM via Causal Event Modeling
Oct 08, 2024



Video Temporal Grounding (VTG) is a crucial capability for video understanding models and plays a vital role in downstream tasks such as video browsing and editing. To effectively handle various tasks simultaneously and enable zero-shot prediction, there is a growing trend in employing video LLMs for VTG tasks. However, current video LLM-based methods rely exclusively on natural language generation, lacking the ability to model the clear structure inherent in videos, which restricts their effectiveness in tackling VTG tasks. To address this issue, this paper first formally introduces causal event modeling framework, which represents videos as sequences of events, and predict the current event using previous events, video inputs, and textural instructions. Each event consists of three components: timestamps, salient scores, and textual captions. We then propose a novel task-interleaved video LLM called TRACE to effectively implement the causal event modeling framework in practice. The TRACE processes visual frames, timestamps, salient scores, and text as distinct tasks, employing various encoders and decoding heads for each. Task tokens are arranged in an interleaved sequence according to the causal event modeling framework's formulation. Extensive experiments on various VTG tasks and datasets demonstrate the superior performance of TRACE compared to state-of-the-art video LLMs. Our model and code are available at \url{https://github.com/gyxxyg/TRACE}.
Enhancing Long Video Understanding via Hierarchical Event-Based Memory
Sep 10, 2024
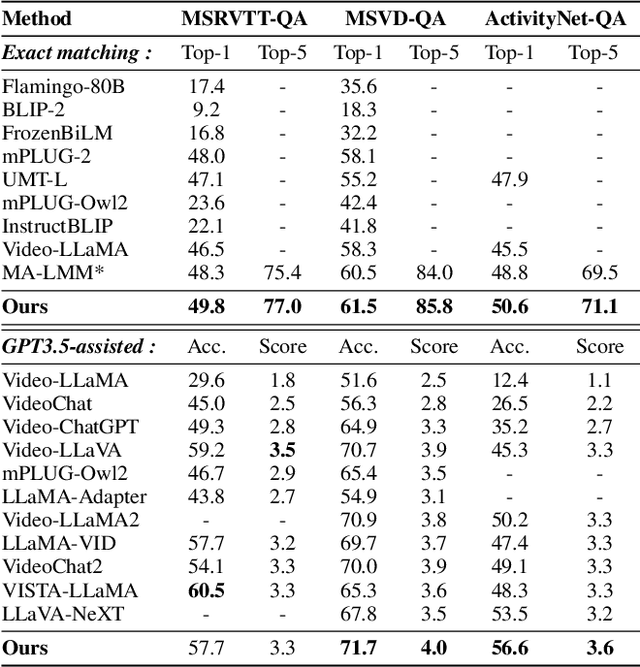
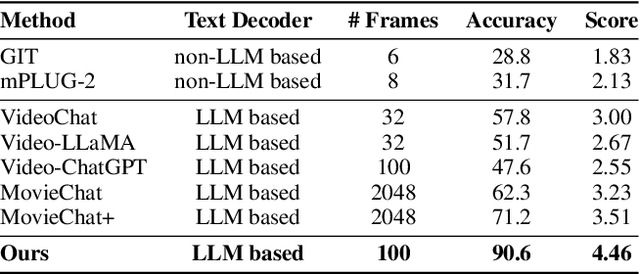

Recently, integrating visual foundation models into large language models (LLMs) to form video understanding systems has attracted widespread attention. Most of the existing models compress diverse semantic information within the whole video and feed it into LLMs for content comprehension. While this method excels in short video understanding, it may result in a blend of multiple event information in long videos due to coarse compression, which causes information redundancy. Consequently, the semantics of key events might be obscured within the vast information that hinders the model's understanding capabilities. To address this issue, we propose a Hierarchical Event-based Memory-enhanced LLM (HEM-LLM) for better understanding of long videos. Firstly, we design a novel adaptive sequence segmentation scheme to divide multiple events within long videos. In this way, we can perform individual memory modeling for each event to establish intra-event contextual connections, thereby reducing information redundancy. Secondly, while modeling current event, we compress and inject the information of the previous event to enhance the long-term inter-event dependencies in videos. Finally, we perform extensive experiments on various video understanding tasks and the results show that our model achieves state-of-the-art performances.
TC-LLaVA: Rethinking the Transfer from Image to Video Understanding with Temporal Considerations
Sep 05, 2024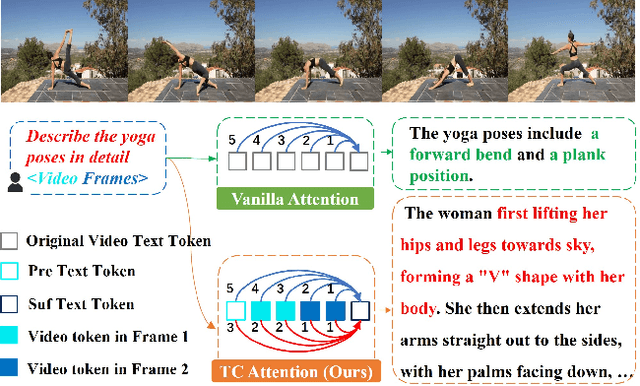

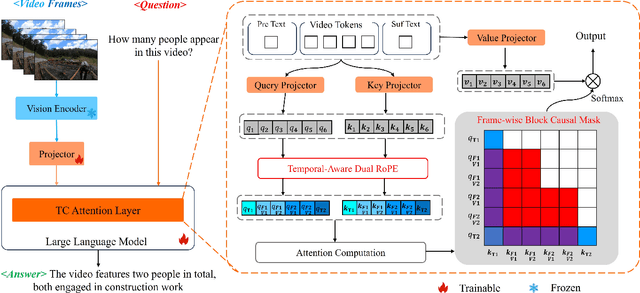

Multimodal Large Language Models (MLLMs) have significantly improved performance across various image-language applications. Recently, there has been a growing interest in adapting image pre-trained MLLMs for video-related tasks. However, most efforts concentrate on enhancing the vision encoder and projector components, while the core part, Large Language Models (LLMs), remains comparatively under-explored. In this paper, we propose two strategies to enhance the model's capability in video understanding tasks by improving inter-layer attention computation in LLMs. Specifically, the first approach focuses on the enhancement of Rotary Position Embedding (RoPE) with Temporal-Aware Dual RoPE, which introduces temporal position information to strengthen the MLLM's temporal modeling capabilities while preserving the relative position relationships of both visual and text tokens. The second approach involves enhancing the Attention Mask with the Frame-wise Block Causal Attention Mask, a simple yet effective method that broadens visual token interactions within and across video frames while maintaining the causal inference mechanism. Based on these proposed methods, we adapt LLaVA for video understanding tasks, naming it Temporal-Considered LLaVA (TC-LLaVA). Our TC-LLaVA achieves new state-of-the-art performance across various video understanding benchmarks with only supervised fine-tuning (SFT) on video-related datasets.