 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo MLLMs Understand Pointing? Benchmarking and Enhancing Referential Reasoning in Egocentric Vision
Apr 23, 2026Egocentric AI agents, such as smart glasses, rely on pointing gestures to resolve referential ambiguities in natural language commands. However, despite advancements in Multimodal Large Language Models (MLLMs), current systems often fail to precisely ground the spatial semantics of pointing. Instead, they rely on spurious correlations with visual proximity or object saliency, a phenomenon we term "Referential Hallucination." To address this gap, we introduce EgoPoint-Bench, a comprehensive question-answering benchmark designed to evaluate and enhance multimodal pointing reasoning in egocentric views. Comprising over 11k high-fidelity simulated and real-world samples, the benchmark spans five evaluation dimensions and three levels of referential complexity. Extensive experiments demonstrate that while state-of-the-art proprietary and open-source models struggle with egocentric pointing, models fine-tuned on our synthetic data achieve significant performance gains and robust sim-to-real generalization. This work highlights the importance of spatially aware supervision and offers a scalable path toward precise egocentric AI assistants. Project page: https://guyyyug.github.io/EgoPoint-Bench/
LLM-Driven Reasoning for Constraint-Aware Feature Selection in Industrial Systems
Mar 26, 2026Feature selection is a crucial step in large-scale industrial machine learning systems, directly affecting model accuracy, efficiency, and maintainability. Traditional feature selection methods rely on labeled data and statistical heuristics, making them difficult to apply in production environments where labeled data are limited and multiple operational constraints must be satisfied. To address this, we propose Model Feature Agent (MoFA), a model-driven framework that performs sequential, reasoning-based feature selection using both semantic and quantitative feature information. MoFA incorporates feature definitions, importance scores, correlations, and metadata (e.g., feature groups or types) into structured prompts and selects features through interpretable, constraint-aware reasoning. We evaluate MoFA in three real-world industrial applications: (1) True Interest and Time-Worthiness Prediction, where it improves accuracy while reducing feature group complexity, (2) Value Model Enhancement, where it discovers high-order interaction terms that yield substantial engagement gains in online experiments, and (3) Notification Behavior Prediction, where it selects compact, high-value feature subsets that improve both model accuracy and inference efficiency. Together, these results demonstrate the practicality and effectiveness of LLM-based reasoning for feature selection in real production systems.
EBPO: Empirical Bayes Shrinkage for Stabilizing Group-Relative Policy Optimization
Feb 05, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has proven effective for enhancing the reasoning capabilities of Large Language Models (LLMs). However, dominant approaches like Group Relative Policy Optimization (GRPO) face critical stability challenges: they suffer from high estimator variance under computational constraints (small group sizes) and vanishing gradient signals in saturated failure regimes where all responses yield identical zero rewards. To address this, we propose Empirical Bayes Policy Optimization (EBPO), a novel framework that regularizes local group-based baselines by borrowing strength from the policy's accumulated global statistics. Instead of estimating baselines in isolation, EBPO employs a shrinkage estimator that dynamically balances local group statistics with a global prior updated via Welford's online algorithm. Theoretically, we demonstrate that EBPO guarantees strictly lower Mean Squared Error (MSE), bounded entropy decay, and non-vanishing penalty signals in failure scenarios compared to GRPO. Empirically, EBPO consistently outperforms GRPO and other established baselines across diverse benchmarks, including AIME and OlympiadBench. Notably, EBPO exhibits superior training stability, achieving high-performance gains even with small group sizes, and benefits significantly from difficulty-stratified curriculum learning.
Thought Communication in Multiagent Collaboration
Oct 23, 2025Natural language has long enabled human cooperation, but its lossy, ambiguous, and indirect nature limits the potential of collective intelligence. While machines are not subject to these constraints, most LLM-based multi-agent systems still rely solely on natural language, exchanging tokens or their embeddings. To go beyond language, we introduce a new paradigm, thought communication, which enables agents to interact directly mind-to-mind, akin to telepathy. To uncover these latent thoughts in a principled way, we formalize the process as a general latent variable model, where agent states are generated by an unknown function of underlying thoughts. We prove that, in a nonparametric setting without auxiliary information, both shared and private latent thoughts between any pair of agents can be identified. Moreover, the global structure of thought sharing, including which agents share which thoughts and how these relationships are structured, can also be recovered with theoretical guarantees. Guided by the established theory, we develop a framework that extracts latent thoughts from all agents prior to communication and assigns each agent the relevant thoughts, along with their sharing patterns. This paradigm naturally extends beyond LLMs to all modalities, as most observational data arise from hidden generative processes. Experiments on both synthetic and real-world benchmarks validate the theory and demonstrate the collaborative advantages of thought communication. We hope this work illuminates the potential of leveraging the hidden world, as many challenges remain unsolvable through surface-level observation alone, regardless of compute or data scale.
HyperZero: A Customized End-to-End Auto-Tuning System for Recommendation with Hourly Feedback
Jan 30, 2025



Modern recommendation systems can be broadly divided into two key stages: the ranking stage, where the system predicts various user engagements (e.g., click-through rate, like rate, follow rate, watch time), and the value model stage, which aggregates these predictive scores through a function (e.g., a linear combination defined by a weight vector) to measure the value of each content by a single numerical score. Both stages play roughly equally important roles in real industrial systems; however, how to optimize the model weights for the second stage still lacks systematic study. This paper focuses on optimizing the second stage through auto-tuning technology. Although general auto-tuning systems and solutions - both from established production practices and open-source solutions - can address this problem, they typically require weeks or even months to identify a feasible solution. Such prolonged tuning processes are unacceptable in production environments for recommendation systems, as suboptimal value models can severely degrade user experience. An effective auto-tuning solution is required to identify a viable model within 2-3 days, rather than the extended timelines typically associated with existing approaches. In this paper, we introduce a practical auto-tuning system named HyperZero that addresses these time constraints while effectively solving the unique challenges inherent in modern recommendation systems. Moreover, this framework has the potential to be expanded to broader tuning tasks within recommendation systems.
TC-LLaVA: Rethinking the Transfer from Image to Video Understanding with Temporal Considerations
Sep 05, 2024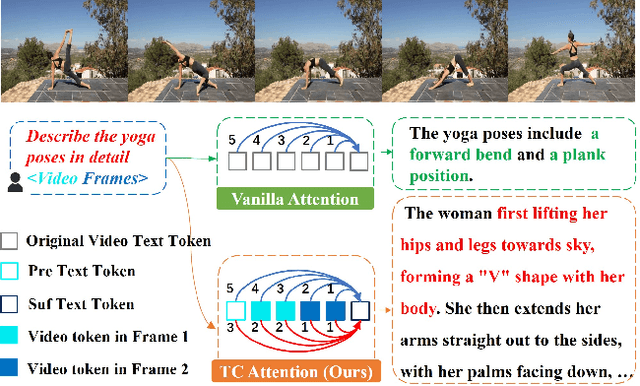

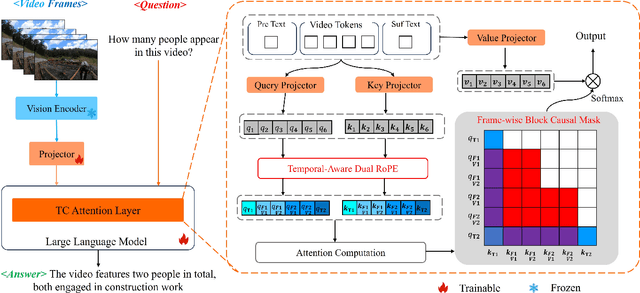

Multimodal Large Language Models (MLLMs) have significantly improved performance across various image-language applications. Recently, there has been a growing interest in adapting image pre-trained MLLMs for video-related tasks. However, most efforts concentrate on enhancing the vision encoder and projector components, while the core part, Large Language Models (LLMs), remains comparatively under-explored. In this paper, we propose two strategies to enhance the model's capability in video understanding tasks by improving inter-layer attention computation in LLMs. Specifically, the first approach focuses on the enhancement of Rotary Position Embedding (RoPE) with Temporal-Aware Dual RoPE, which introduces temporal position information to strengthen the MLLM's temporal modeling capabilities while preserving the relative position relationships of both visual and text tokens. The second approach involves enhancing the Attention Mask with the Frame-wise Block Causal Attention Mask, a simple yet effective method that broadens visual token interactions within and across video frames while maintaining the causal inference mechanism. Based on these proposed methods, we adapt LLaVA for video understanding tasks, naming it Temporal-Considered LLaVA (TC-LLaVA). Our TC-LLaVA achieves new state-of-the-art performance across various video understanding benchmarks with only supervised fine-tuning (SFT) on video-related datasets.
Tuning Pre-trained Model via Moment Probing
Jul 21, 2023Recently, efficient fine-tuning of large-scale pre-trained models has attracted increasing research interests, where linear probing (LP) as a fundamental module is involved in exploiting the final representations for task-dependent classification. However, most of the existing methods focus on how to effectively introduce a few of learnable parameters, and little work pays attention to the commonly used LP module. In this paper, we propose a novel Moment Probing (MP) method to further explore the potential of LP. Distinguished from LP which builds a linear classification head based on the mean of final features (e.g., word tokens for ViT) or classification tokens, our MP performs a linear classifier on feature distribution, which provides the stronger representation ability by exploiting richer statistical information inherent in features. Specifically, we represent feature distribution by its characteristic function, which is efficiently approximated by using first- and second-order moments of features. Furthermore, we propose a multi-head convolutional cross-covariance (MHC$^3$) to compute second-order moments in an efficient and effective manner. By considering that MP could affect feature learning, we introduce a partially shared module to learn two recalibrating parameters (PSRP) for backbones based on MP, namely MP$_{+}$. Extensive experiments on ten benchmarks using various models show that our MP significantly outperforms LP and is competitive with counterparts at less training cost, while our MP$_{+}$ achieves state-of-the-art performance.
AdaTT: Adaptive Task-to-Task Fusion Network for Multitask Learning in Recommendations
Apr 11, 2023



Multi-task learning (MTL) aims at enhancing the performance and efficiency of machine learning models by training them on multiple tasks simultaneously. However, MTL research faces two challenges: 1) modeling the relationships between tasks to effectively share knowledge between them, and 2) jointly learning task-specific and shared knowledge. In this paper, we present a novel model Adaptive Task-to-Task Fusion Network (AdaTT) to address both challenges. AdaTT is a deep fusion network built with task specific and optional shared fusion units at multiple levels. By leveraging a residual mechanism and gating mechanism for task-to-task fusion, these units adaptively learn shared knowledge and task specific knowledge. To evaluate the performance of AdaTT, we conduct experiments on a public benchmark and an industrial recommendation dataset using various task groups. Results demonstrate AdaTT can significantly outperform existing state-of-the-art baselines.
Demand Response Method Considering Multiple Types of Flexible Loads in Industrial Parks
May 24, 2022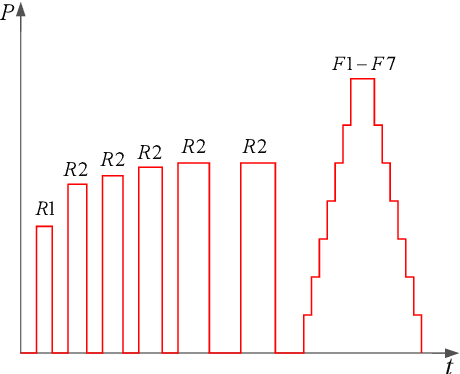

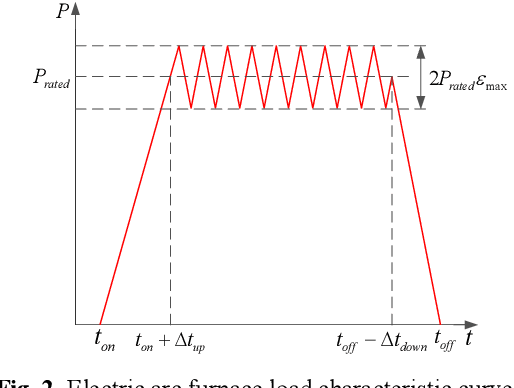

With the rapid development of the energy internet, the proportion of flexible loads in smart grid is getting much higher than before. It is highly important to model flexible loads based on demand response. Therefore, a new demand response method considering multiple flexible loads is proposed in this paper to character the integrated demand response (IDR) resources. Firstly, a physical process analytical deduction (PPAD) model is proposed to improve the classification of flexible loads in industrial parks. Scenario generation, data point augmentation, and smooth curves under various operating conditions are considered to enhance the applicability of the model. Secondly, in view of the strong volatility and poor modeling effect of Wasserstein-generative adversarial networks (WGAN), an improved WGAN-gradient penalty (IWGAN-GP) model is developed to get a faster convergence speed than traditional WGAN and generate a higher quality samples. Finally, the PPAD and IWGAN-GP models are jointly implemented to reveal the degree of correlation between flexible loads. Meanwhile, an intelligent offline database is built to deal with the impact of nonlinear factors in different response scenarios. Numerical examples have been performed with the results proving that the proposed method is significantly better than the existing technologies in reducing load modeling deviation and improving the responsiveness of park loads.
Hierarchical Classification of Pulmonary Lesions: A Large-Scale Radio-Pathomics Study
Oct 08, 2020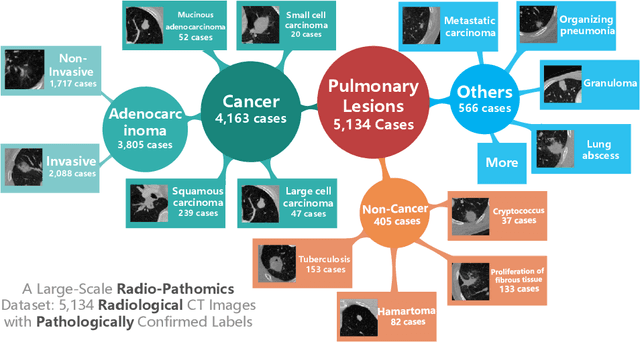
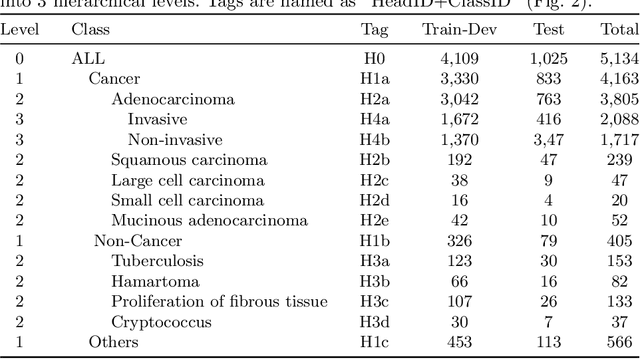
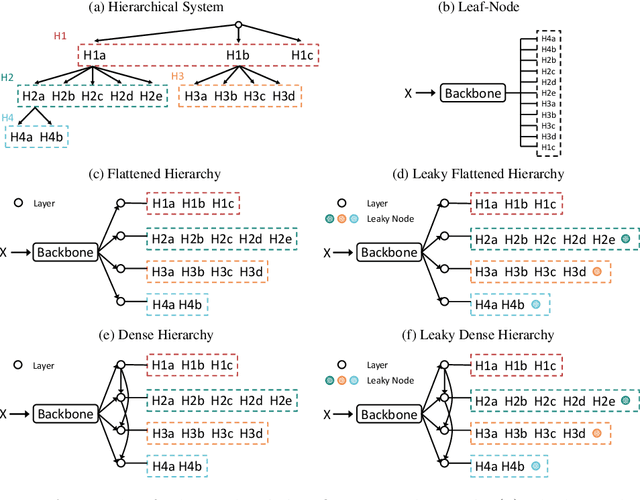
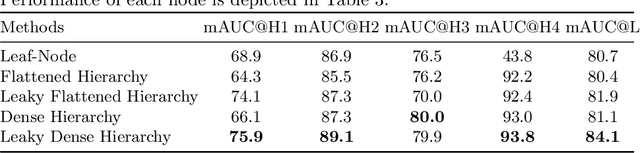
Diagnosis of pulmonary lesions from computed tomography (CT) is important but challenging for clinical decision making in lung cancer related diseases. Deep learning has achieved great success in computer aided diagnosis (CADx) area for lung cancer, whereas it suffers from label ambiguity due to the difficulty in the radiological diagnosis. Considering that invasive pathological analysis serves as the clinical golden standard of lung cancer diagnosis, in this study, we solve the label ambiguity issue via a large-scale radio-pathomics dataset containing 5,134 radiological CT images with pathologically confirmed labels, including cancers (e.g., invasive/non-invasive adenocarcinoma, squamous carcinoma) and non-cancer diseases (e.g., tuberculosis, hamartoma). This retrospective dataset, named Pulmonary-RadPath, enables development and validation of accurate deep learning systems to predict invasive pathological labels with a non-invasive procedure, i.e., radiological CT scans. A three-level hierarchical classification system for pulmonary lesions is developed, which covers most diseases in cancer-related diagnosis. We explore several techniques for hierarchical classification on this dataset, and propose a Leaky Dense Hierarchy approach with proven effectiveness in experiments. Our study significantly outperforms prior arts in terms of data scales (6x larger), disease comprehensiveness and hierarchies. The promising results suggest the potentials to facilitate precision medicine.