 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssociative Constructive Evolution: Enhancing Metaheuristics through Hebbian-Learned Generative Guidance
Mar 31, 2026Metaheuristic algorithms such as Particle Swarm Optimization (PSO) and Evolutionary Algorithms (EA) excel at exploring solution spaces but lack mechanisms to accumulate and reuse procedural knowledge from successful search trajectories. This paper proposes Associative Constructive Evolution (ACE), a framework that enhances metaheuristics through learned generative guidance. ACE introduces a Generative Construction Automaton (GCA) -- a probabilistic model over operation sequences -- coupled with the base metaheuristic in a synergistic loop: the metaheuristic explores and provides trajectory samples, while the GCA consolidates successful patterns and guides future exploration. Three mechanisms realize this cooperation: Hebbian weight consolidation that strengthens associations between co-successful operations, guided sampling that biases search toward learned high-quality regions, and symbolic abstraction that extracts frequent patterns into reusable macro-operations. Experiments integrating ACE with EA and PSO on molecular design and maze navigation demonstrate consistent improvements. ACE-PSO achieves a 27.5% increase in success rate while reducing convergence time by 49.6%. In molecular design, ACE-EA improves fitness by 10.1% with 126 chemically interpretable macro-operations automatically discovered.
Multi-Constrained Evolutionary Molecular Design Framework: An Interpretable Drug Design Method Combining Rule-Based Evolution and Molecular Crossover
Jan 15, 2026This study proposes MCEMOL (Multi-Constrained Evolutionary Molecular Design Framework), a molecular optimization approach integrating rule-based evolution with molecular crossover. MCEMOL employs dual-layer evolution: optimizing transformation rules at rule level while applying crossover and mutation to molecular structures. Unlike deep learning methods requiring large datasets and extensive training, our algorithm evolves efficiently from minimal starting molecules with low computational overhead. The framework incorporates message-passing neural networks and comprehensive chemical constraints, ensuring efficient and interpretable molecular design. Experimental results demonstrate that MCEMOL provides transparent design pathways through its evolutionary mechanism while generating valid, diverse, target-compliant molecules. The framework achieves 100% molecular validity with high structural diversity and excellent drug-likeness compliance, showing strong performance in symmetry constraints, pharmacophore optimization, and stereochemical integrity. Unlike black-box methods, MCEMOL delivers dual value: interpretable transformation rules researchers can understand and trust, alongside high-quality molecular libraries for practical applications. This establishes a paradigm where interpretable AI-driven drug design and effective molecular generation are achieved simultaneously, bridging the gap between computational innovation and practical drug discovery needs.
HyperZero: A Customized End-to-End Auto-Tuning System for Recommendation with Hourly Feedback
Jan 30, 2025



Modern recommendation systems can be broadly divided into two key stages: the ranking stage, where the system predicts various user engagements (e.g., click-through rate, like rate, follow rate, watch time), and the value model stage, which aggregates these predictive scores through a function (e.g., a linear combination defined by a weight vector) to measure the value of each content by a single numerical score. Both stages play roughly equally important roles in real industrial systems; however, how to optimize the model weights for the second stage still lacks systematic study. This paper focuses on optimizing the second stage through auto-tuning technology. Although general auto-tuning systems and solutions - both from established production practices and open-source solutions - can address this problem, they typically require weeks or even months to identify a feasible solution. Such prolonged tuning processes are unacceptable in production environments for recommendation systems, as suboptimal value models can severely degrade user experience. An effective auto-tuning solution is required to identify a viable model within 2-3 days, rather than the extended timelines typically associated with existing approaches. In this paper, we introduce a practical auto-tuning system named HyperZero that addresses these time constraints while effectively solving the unique challenges inherent in modern recommendation systems. Moreover, this framework has the potential to be expanded to broader tuning tasks within recommendation systems.
SWaT: Statistical Modeling of Video Watch Time through User Behavior Analysis
Aug 14, 2024



The significance of estimating video watch time has been highlighted by the rising importance of (short) video recommendation, which has become a core product of mainstream social media platforms. Modeling video watch time, however, has been challenged by the complexity of user-video interaction, such as different user behavior modes in watching the recommended videos and varying watching probabilities over the video horizon. Despite the importance and challenges, existing literature on modeling video watch time mostly focuses on relatively black-box mechanical enhancement of the classical regression/classification losses, without factoring in user behavior in a principled manner. In this paper, we for the first time take on a user-centric perspective to model video watch time, from which we propose a white-box statistical framework that directly translates various user behavior assumptions in watching (short) videos into statistical watch time models. These behavior assumptions are portrayed by our domain knowledge on users' behavior modes in video watching. We further employ bucketization to cope with user's non-stationary watching probability over the video horizon, which additionally helps to respect the constraint of video length and facilitate the practical compatibility between the continuous regression event of watch time and other binary classification events. We test our models extensively on two public datasets, a large-scale offline industrial dataset, and an online A/B test on a short video platform with hundreds of millions of daily-active users. On all experiments, our models perform competitively against strong relevant baselines, demonstrating the efficacy of our user-centric perspective and proposed framework.
TODM: Train Once Deploy Many Efficient Supernet-Based RNN-T Compression For On-device ASR Models
Sep 05, 2023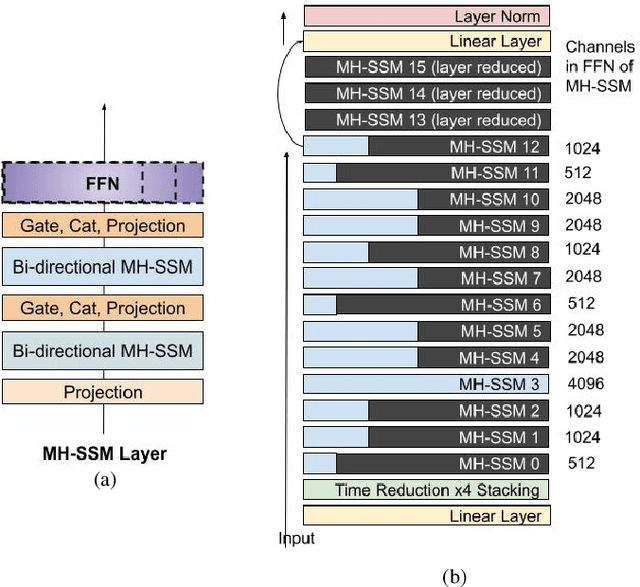
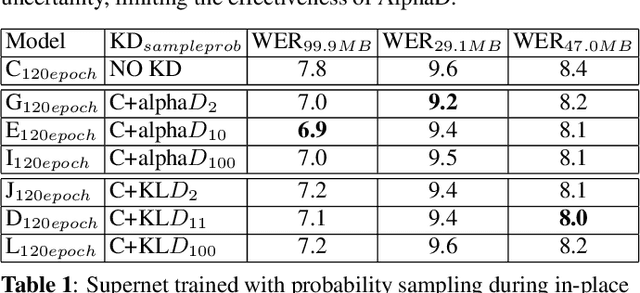
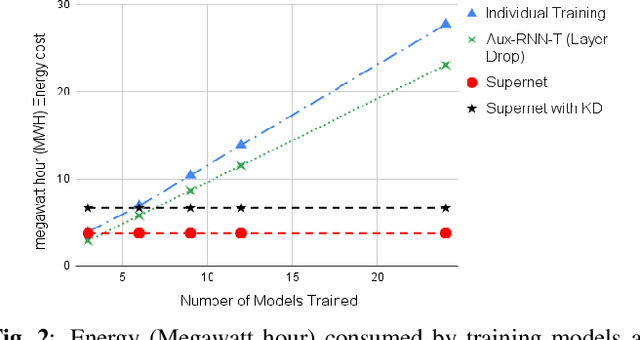
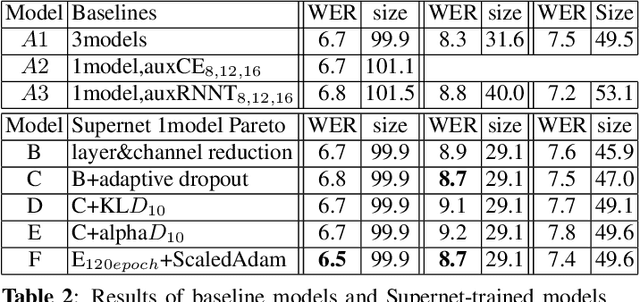
Automatic Speech Recognition (ASR) models need to be optimized for specific hardware before they can be deployed on devices. This can be done by tuning the model's hyperparameters or exploring variations in its architecture. Re-training and re-validating models after making these changes can be a resource-intensive task. This paper presents TODM (Train Once Deploy Many), a new approach to efficiently train many sizes of hardware-friendly on-device ASR models with comparable GPU-hours to that of a single training job. TODM leverages insights from prior work on Supernet, where Recurrent Neural Network Transducer (RNN-T) models share weights within a Supernet. It reduces layer sizes and widths of the Supernet to obtain subnetworks, making them smaller models suitable for all hardware types. We introduce a novel combination of three techniques to improve the outcomes of the TODM Supernet: adaptive dropouts, an in-place Alpha-divergence knowledge distillation, and the use of ScaledAdam optimizer. We validate our approach by comparing Supernet-trained versus individually tuned Multi-Head State Space Model (MH-SSM) RNN-T using LibriSpeech. Results demonstrate that our TODM Supernet either matches or surpasses the performance of manually tuned models by up to a relative of 3% better in word error rate (WER), while efficiently keeping the cost of training many models at a small constant.
Mixture-of-Supernets: Improving Weight-Sharing Supernet Training with Architecture-Routed Mixture-of-Experts
Jun 08, 2023



Weight-sharing supernet has become a vital component for performance estimation in the state-of-the-art (SOTA) neural architecture search (NAS) frameworks. Although supernet can directly generate different subnetworks without retraining, there is no guarantee for the quality of these subnetworks because of weight sharing. In NLP tasks such as machine translation and pre-trained language modeling, we observe that given the same model architecture, there is a large performance gap between supernet and training from scratch. Hence, supernet cannot be directly used and retraining is necessary after finding the optimal architectures. In this work, we propose mixture-of-supernets, a generalized supernet formulation where mixture-of-experts (MoE) is adopted to enhance the expressive power of the supernet model, with negligible training overhead. In this way, different subnetworks do not share the model weights directly, but through an architecture-based routing mechanism. As a result, model weights of different subnetworks are customized towards their specific architectures and the weight generation is learned by gradient descent. Compared to existing weight-sharing supernet for NLP, our method can minimize the retraining time, greatly improving training efficiency. In addition, the proposed method achieves the SOTA performance in NAS for building fast machine translation models, yielding better latency-BLEU tradeoff compared to HAT, state-of-the-art NAS for MT. We also achieve the SOTA performance in NAS for building memory-efficient task-agnostic BERT models, outperforming NAS-BERT and AutoDistil in various model sizes.
LiCo-Net: Linearized Convolution Network for Hardware-efficient Keyword Spotting
Nov 09, 2022



This paper proposes a hardware-efficient architecture, Linearized Convolution Network (LiCo-Net) for keyword spotting. It is optimized specifically for low-power processor units like microcontrollers. ML operators exhibit heterogeneous efficiency profiles on power-efficient hardware. Given the exact theoretical computation cost, int8 operators are more computation-effective than float operators, and linear layers are often more efficient than other layers. The proposed LiCo-Net is a dual-phase system that uses the efficient int8 linear operators at the inference phase and applies streaming convolutions at the training phase to maintain a high model capacity. The experimental results show that LiCo-Net outperforms single-value decomposition filter (SVDF) on hardware efficiency with on-par detection performance. Compared to SVDF, LiCo-Net reduces cycles by 40% on HiFi4 DSP.
Learning a Dual-Mode Speech Recognition Model via Self-Pruning
Jul 25, 2022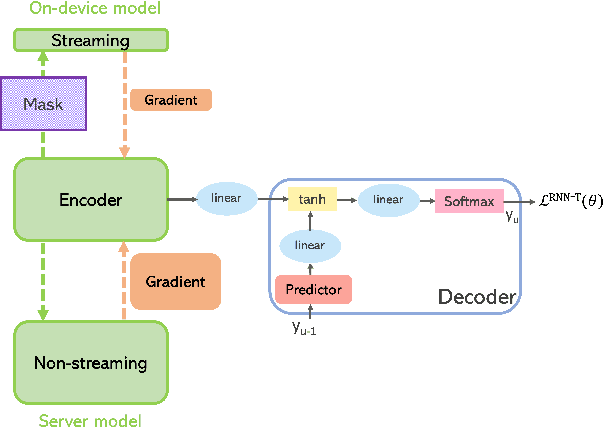

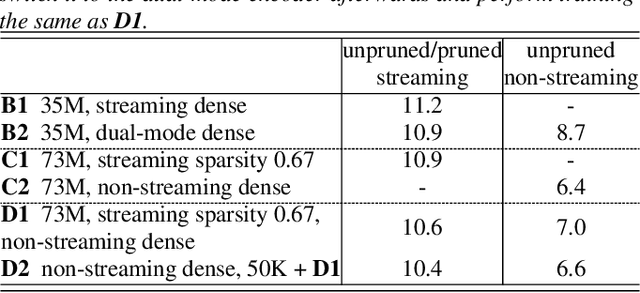

There is growing interest in unifying the streaming and full-context automatic speech recognition (ASR) networks into a single end-to-end ASR model to simplify the model training and deployment for both use cases. While in real-world ASR applications, the streaming ASR models typically operate under more storage and computational constraints - e.g., on embedded devices - than any server-side full-context models. Motivated by the recent progress in Omni-sparsity supernet training, where multiple subnetworks are jointly optimized in one single model, this work aims to jointly learn a compact sparse on-device streaming ASR model, and a large dense server non-streaming model, in a single supernet. Next, we present that, performing supernet training on both wav2vec 2.0 self-supervised learning and supervised ASR fine-tuning can not only substantially improve the large non-streaming model as shown in prior works, and also be able to improve the compact sparse streaming model.
DepthShrinker: A New Compression Paradigm Towards Boosting Real-Hardware Efficiency of Compact Neural Networks
Jun 02, 2022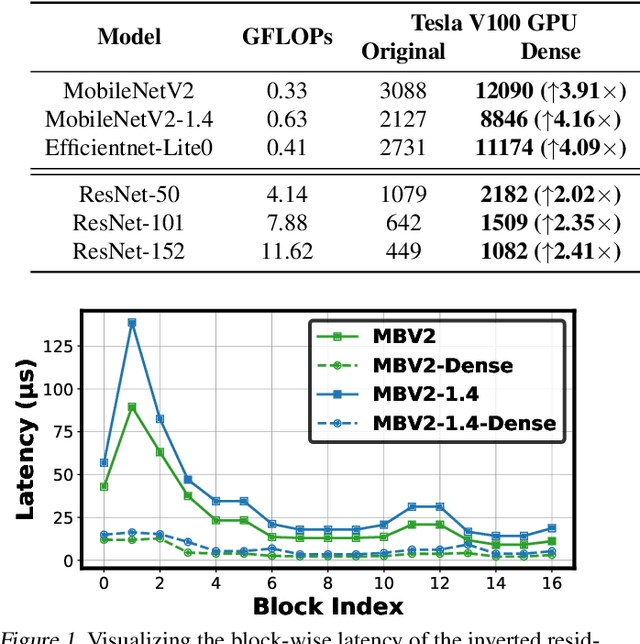
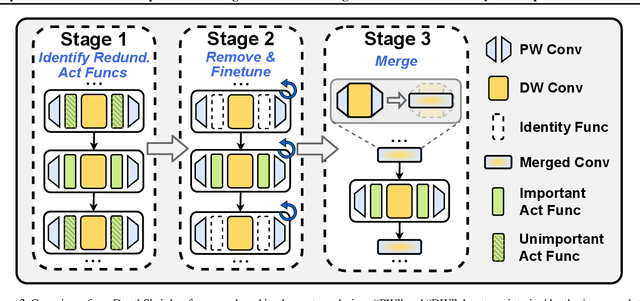
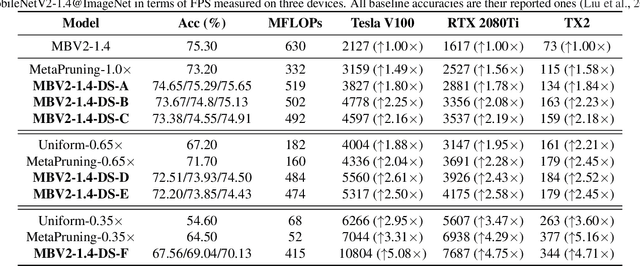
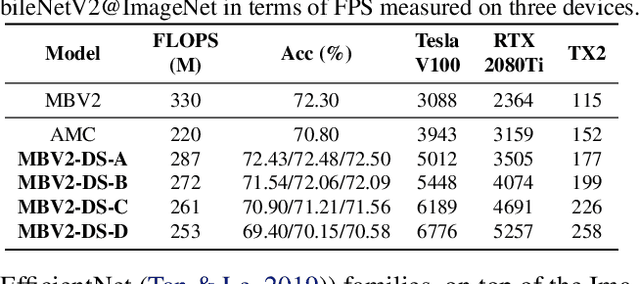
Efficient deep neural network (DNN) models equipped with compact operators (e.g., depthwise convolutions) have shown great potential in reducing DNNs' theoretical complexity (e.g., the total number of weights/operations) while maintaining a decent model accuracy. However, existing efficient DNNs are still limited in fulfilling their promise in boosting real-hardware efficiency, due to their commonly adopted compact operators' low hardware utilization. In this work, we open up a new compression paradigm for developing real-hardware efficient DNNs, leading to boosted hardware efficiency while maintaining model accuracy. Interestingly, we observe that while some DNN layers' activation functions help DNNs' training optimization and achievable accuracy, they can be properly removed after training without compromising the model accuracy. Inspired by this observation, we propose a framework dubbed DepthShrinker, which develops hardware-friendly compact networks via shrinking the basic building blocks of existing efficient DNNs that feature irregular computation patterns into dense ones with much improved hardware utilization and thus real-hardware efficiency. Excitingly, our DepthShrinker framework delivers hardware-friendly compact networks that outperform both state-of-the-art efficient DNNs and compression techniques, e.g., a 3.06\% higher accuracy and 1.53$\times$ throughput on Tesla V100 over SOTA channel-wise pruning method MetaPruning. Our codes are available at: https://github.com/RICE-EIC/DepthShrinker.
PyTorchVideo: A Deep Learning Library for Video Understanding
Nov 18, 2021
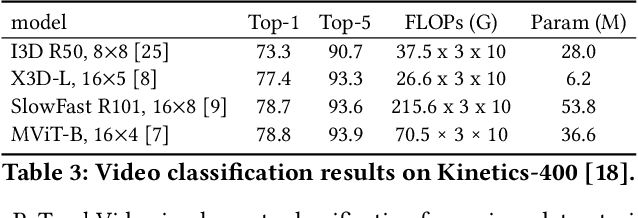

We introduce PyTorchVideo, an open-source deep-learning library that provides a rich set of modular, efficient, and reproducible components for a variety of video understanding tasks, including classification, detection, self-supervised learning, and low-level processing. The library covers a full stack of video understanding tools including multimodal data loading, transformations, and models that reproduce state-of-the-art performance. PyTorchVideo further supports hardware acceleration that enables real-time inference on mobile devices. The library is based on PyTorch and can be used by any training framework; for example, PyTorchLightning, PySlowFast, or Classy Vision. PyTorchVideo is available at https://pytorchvideo.org/