 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHymba: A Hybrid-head Architecture for Small Language Models
Nov 20, 2024



We propose Hymba, a family of small language models featuring a hybrid-head parallel architecture that integrates transformer attention mechanisms with state space models (SSMs) for enhanced efficiency. Attention heads provide high-resolution recall, while SSM heads enable efficient context summarization. Additionally, we introduce learnable meta tokens that are prepended to prompts, storing critical information and alleviating the "forced-to-attend" burden associated with attention mechanisms. This model is further optimized by incorporating cross-layer key-value (KV) sharing and partial sliding window attention, resulting in a compact cache size. During development, we conducted a controlled study comparing various architectures under identical settings and observed significant advantages of our proposed architecture. Notably, Hymba achieves state-of-the-art results for small LMs: Our Hymba-1.5B-Base model surpasses all sub-2B public models in performance and even outperforms Llama-3.2-3B with 1.32% higher average accuracy, an 11.67x cache size reduction, and 3.49x throughput.
Omni-Recon: Towards General-Purpose Neural Radiance Fields for Versatile 3D Applications
Mar 17, 2024Recent breakthroughs in Neural Radiance Fields (NeRFs) have sparked significant demand for their integration into real-world 3D applications. However, the varied functionalities required by different 3D applications often necessitate diverse NeRF models with various pipelines, leading to tedious NeRF training for each target task and cumbersome trial-and-error experiments. Drawing inspiration from the generalization capability and adaptability of emerging foundation models, our work aims to develop one general-purpose NeRF for handling diverse 3D tasks. We achieve this by proposing a framework called Omni-Recon, which is capable of (1) generalizable 3D reconstruction and zero-shot multitask scene understanding, and (2) adaptability to diverse downstream 3D applications such as real-time rendering and scene editing. Our key insight is that an image-based rendering pipeline, with accurate geometry and appearance estimation, can lift 2D image features into their 3D counterparts, thus extending widely explored 2D tasks to the 3D world in a generalizable manner. Specifically, our Omni-Recon features a general-purpose NeRF model using image-based rendering with two decoupled branches: one complex transformer-based branch that progressively fuses geometry and appearance features for accurate geometry estimation, and one lightweight branch for predicting blending weights of source views. This design achieves state-of-the-art (SOTA) generalizable 3D surface reconstruction quality with blending weights reusable across diverse tasks for zero-shot multitask scene understanding. In addition, it can enable real-time rendering after baking the complex geometry branch into meshes, swift adaptation to achieve SOTA generalizable 3D understanding performance, and seamless integration with 2D diffusion models for text-guided 3D editing.
Towards Cognitive AI Systems: a Survey and Prospective on Neuro-Symbolic AI
Jan 02, 2024The remarkable advancements in artificial intelligence (AI), primarily driven by deep neural networks, have significantly impacted various aspects of our lives. However, the current challenges surrounding unsustainable computational trajectories, limited robustness, and a lack of explainability call for the development of next-generation AI systems. Neuro-symbolic AI (NSAI) emerges as a promising paradigm, fusing neural, symbolic, and probabilistic approaches to enhance interpretability, robustness, and trustworthiness while facilitating learning from much less data. Recent NSAI systems have demonstrated great potential in collaborative human-AI scenarios with reasoning and cognitive capabilities. In this paper, we provide a systematic review of recent progress in NSAI and analyze the performance characteristics and computational operators of NSAI models. Furthermore, we discuss the challenges and potential future directions of NSAI from both system and architectural perspectives.
GPT4AIGChip: Towards Next-Generation AI Accelerator Design Automation via Large Language Models
Sep 19, 2023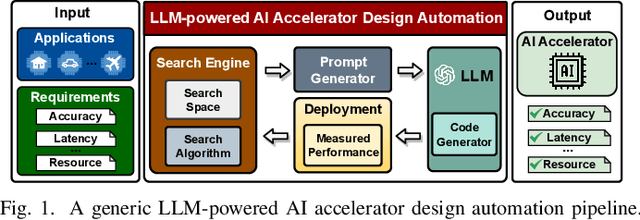
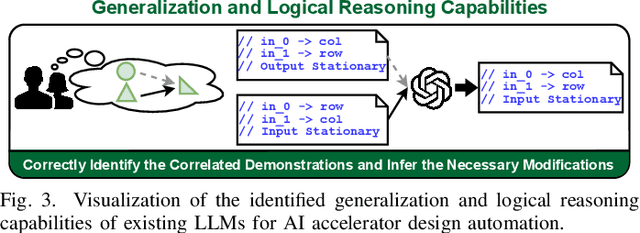
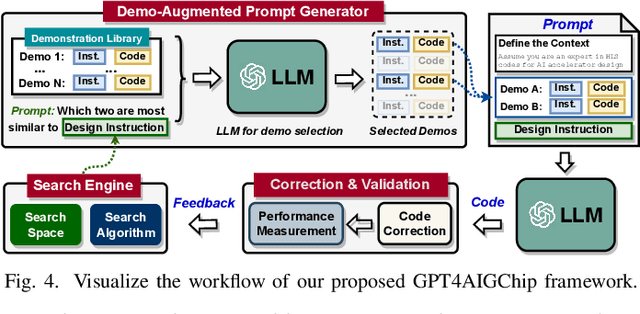
The remarkable capabilities and intricate nature of Artificial Intelligence (AI) have dramatically escalated the imperative for specialized AI accelerators. Nonetheless, designing these accelerators for various AI workloads remains both labor- and time-intensive. While existing design exploration and automation tools can partially alleviate the need for extensive human involvement, they still demand substantial hardware expertise, posing a barrier to non-experts and stifling AI accelerator development. Motivated by the astonishing potential of large language models (LLMs) for generating high-quality content in response to human language instructions, we embark on this work to examine the possibility of harnessing LLMs to automate AI accelerator design. Through this endeavor, we develop GPT4AIGChip, a framework intended to democratize AI accelerator design by leveraging human natural languages instead of domain-specific languages. Specifically, we first perform an in-depth investigation into LLMs' limitations and capabilities for AI accelerator design, thus aiding our understanding of our current position and garnering insights into LLM-powered automated AI accelerator design. Furthermore, drawing inspiration from the above insights, we develop a framework called GPT4AIGChip, which features an automated demo-augmented prompt-generation pipeline utilizing in-context learning to guide LLMs towards creating high-quality AI accelerator design. To our knowledge, this work is the first to demonstrate an effective pipeline for LLM-powered automated AI accelerator generation. Accordingly, we anticipate that our insights and framework can serve as a catalyst for innovations in next-generation LLM-powered design automation tools.
NetBooster: Empowering Tiny Deep Learning By Standing on the Shoulders of Deep Giants
Jun 23, 2023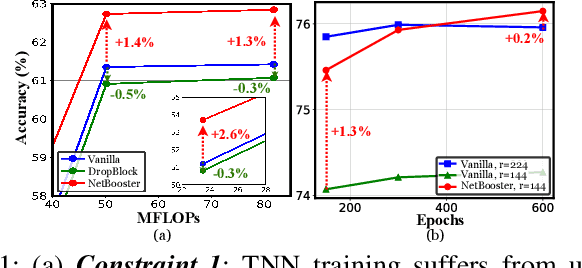
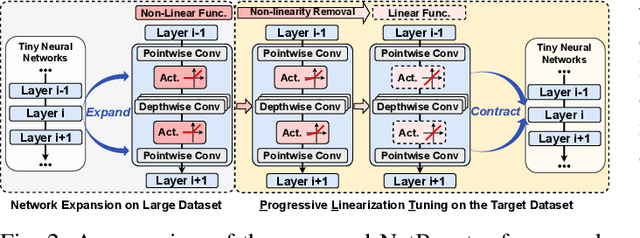
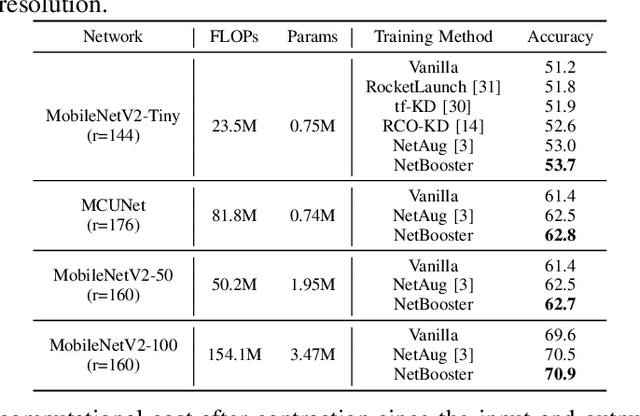
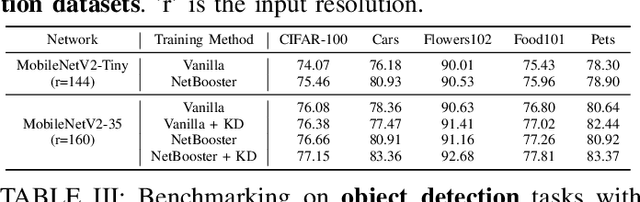
Tiny deep learning has attracted increasing attention driven by the substantial demand for deploying deep learning on numerous intelligent Internet-of-Things devices. However, it is still challenging to unleash tiny deep learning's full potential on both large-scale datasets and downstream tasks due to the under-fitting issues caused by the limited model capacity of tiny neural networks (TNNs). To this end, we propose a framework called NetBooster to empower tiny deep learning by augmenting the architectures of TNNs via an expansion-then-contraction strategy. Extensive experiments show that NetBooster consistently outperforms state-of-the-art tiny deep learning solutions.
Master-ASR: Achieving Multilingual Scalability and Low-Resource Adaptation in ASR with Modular Learning
Jun 23, 2023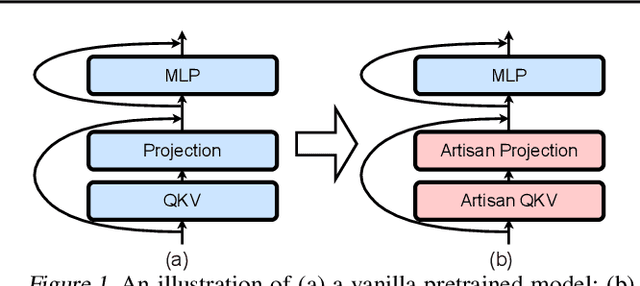
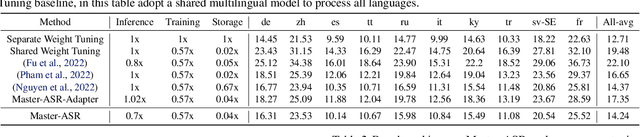
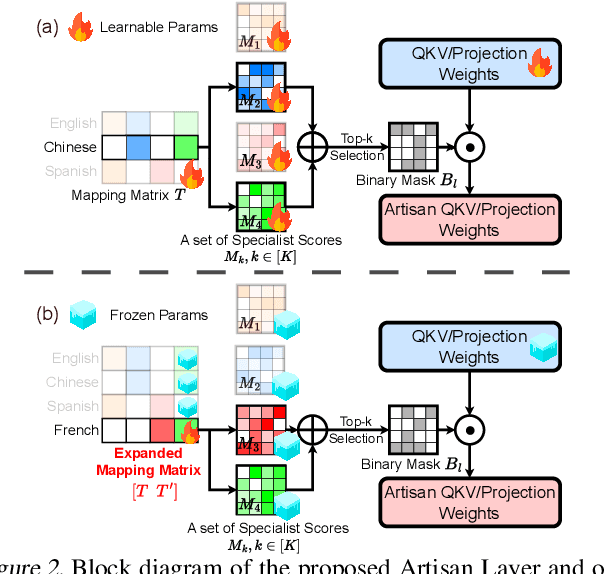
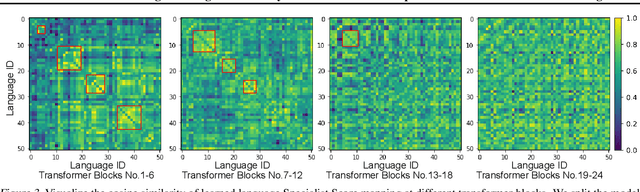
Despite the impressive performance recently achieved by automatic speech recognition (ASR), we observe two primary challenges that hinder its broader applications: (1) The difficulty of introducing scalability into the model to support more languages with limited training, inference, and storage overhead; (2) The low-resource adaptation ability that enables effective low-resource adaptation while avoiding over-fitting and catastrophic forgetting issues. Inspired by recent findings, we hypothesize that we can address the above challenges with modules widely shared across languages. To this end, we propose an ASR framework, dubbed \METHODNS, that, \textit{for the first time}, simultaneously achieves strong multilingual scalability and low-resource adaptation ability thanks to its modularize-then-assemble strategy. Specifically, \METHOD learns a small set of generalizable sub-modules and adaptively assembles them for different languages to reduce the multilingual overhead and enable effective knowledge transfer for low-resource adaptation. Extensive experiments and visualizations demonstrate that \METHOD can effectively discover language similarity and improve multilingual and low-resource ASR performance over state-of-the-art (SOTA) methods, e.g., under multilingual-ASR, our framework achieves a 0.13$\sim$2.41 lower character error rate (CER) with 30\% smaller inference overhead over SOTA solutions on multilingual ASR and a comparable CER, with nearly 50 times fewer trainable parameters over SOTA solutions on low-resource tuning, respectively.
NeRFool: Uncovering the Vulnerability of Generalizable Neural Radiance Fields against Adversarial Perturbations
Jun 10, 2023



Generalizable Neural Radiance Fields (GNeRF) are one of the most promising real-world solutions for novel view synthesis, thanks to their cross-scene generalization capability and thus the possibility of instant rendering on new scenes. While adversarial robustness is essential for real-world applications, little study has been devoted to understanding its implication on GNeRF. We hypothesize that because GNeRF is implemented by conditioning on the source views from new scenes, which are often acquired from the Internet or third-party providers, there are potential new security concerns regarding its real-world applications. Meanwhile, existing understanding and solutions for neural networks' adversarial robustness may not be applicable to GNeRF, due to its 3D nature and uniquely diverse operations. To this end, we present NeRFool, which to the best of our knowledge is the first work that sets out to understand the adversarial robustness of GNeRF. Specifically, NeRFool unveils the vulnerability patterns and important insights regarding GNeRF's adversarial robustness. Built upon the above insights gained from NeRFool, we further develop NeRFool+, which integrates two techniques capable of effectively attacking GNeRF across a wide range of target views, and provide guidelines for defending against our proposed attacks. We believe that our NeRFool/NeRFool+ lays the initial foundation for future innovations in developing robust real-world GNeRF solutions. Our codes are available at: https://github.com/GATECH-EIC/NeRFool.
Instant-NeRF: Instant On-Device Neural Radiance Field Training via Algorithm-Accelerator Co-Designed Near-Memory Processing
May 09, 2023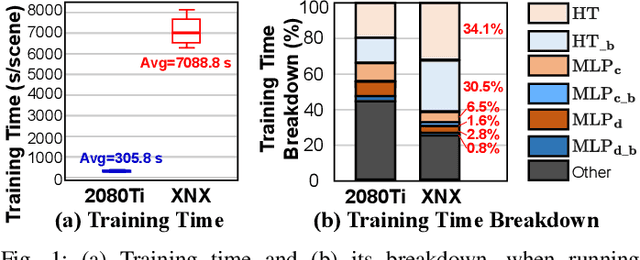
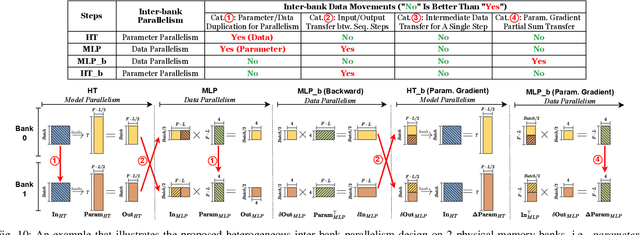
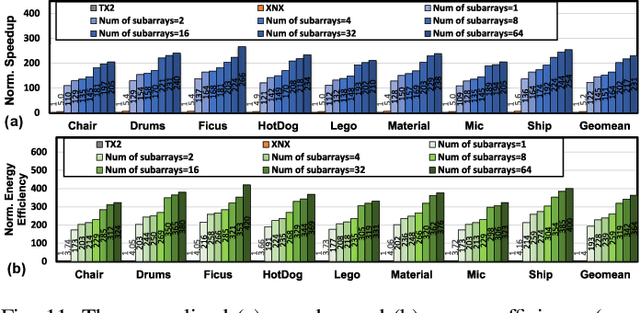
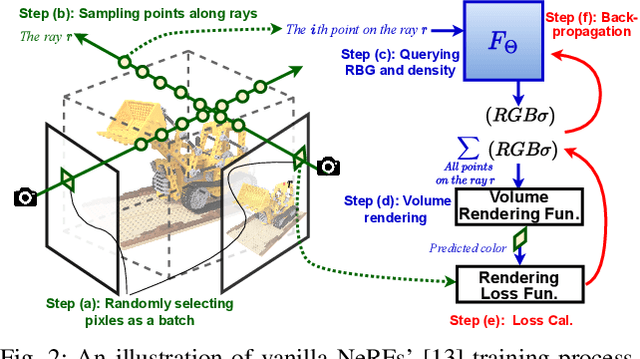
Instant on-device Neural Radiance Fields (NeRFs) are in growing demand for unleashing the promise of immersive AR/VR experiences, but are still limited by their prohibitive training time. Our profiling analysis reveals a memory-bound inefficiency in NeRF training. To tackle this inefficiency, near-memory processing (NMP) promises to be an effective solution, but also faces challenges due to the unique workloads of NeRFs, including the random hash table lookup, random point processing sequence, and heterogeneous bottleneck steps. Therefore, we propose the first NMP framework, Instant-NeRF, dedicated to enabling instant on-device NeRF training. Experiments on eight datasets consistently validate the effectiveness of Instant-NeRF.
Hint-Aug: Drawing Hints from Foundation Vision Transformers Towards Boosted Few-Shot Parameter-Efficient Tuning
Apr 26, 2023Despite the growing demand for tuning foundation vision transformers (FViTs) on downstream tasks, fully unleashing FViTs' potential under data-limited scenarios (e.g., few-shot tuning) remains a challenge due to FViTs' data-hungry nature. Common data augmentation techniques fall short in this context due to the limited features contained in the few-shot tuning data. To tackle this challenge, we first identify an opportunity for FViTs in few-shot tuning: pretrained FViTs themselves have already learned highly representative features from large-scale pretraining data, which are fully preserved during widely used parameter-efficient tuning. We thus hypothesize that leveraging those learned features to augment the tuning data can boost the effectiveness of few-shot FViT tuning. To this end, we propose a framework called Hint-based Data Augmentation (Hint-Aug), which aims to boost FViT in few-shot tuning by augmenting the over-fitted parts of tuning samples with the learned features of pretrained FViTs. Specifically, Hint-Aug integrates two key enablers: (1) an Attentive Over-fitting Detector (AOD) to detect over-confident patches of foundation ViTs for potentially alleviating their over-fitting on the few-shot tuning data and (2) a Confusion-based Feature Infusion (CFI) module to infuse easy-to-confuse features from the pretrained FViTs with the over-confident patches detected by the above AOD in order to enhance the feature diversity during tuning. Extensive experiments and ablation studies on five datasets and three parameter-efficient tuning techniques consistently validate Hint-Aug's effectiveness: 0.04% ~ 32.91% higher accuracy over the state-of-the-art (SOTA) data augmentation method under various low-shot settings. For example, on the Pet dataset, Hint-Aug achieves a 2.22% higher accuracy with 50% less training data over SOTA data augmentation methods.
Gen-NeRF: Efficient and Generalizable Neural Radiance Fields via Algorithm-Hardware Co-Design
Apr 25, 2023

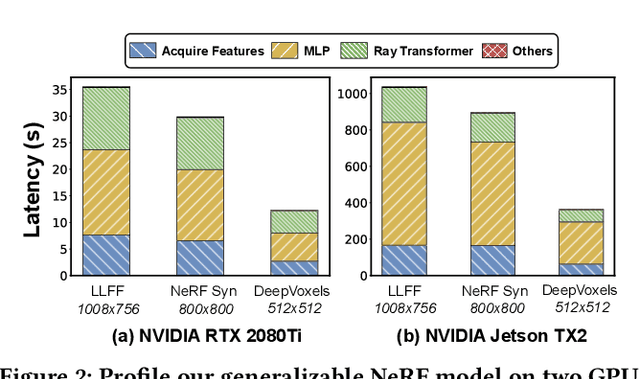
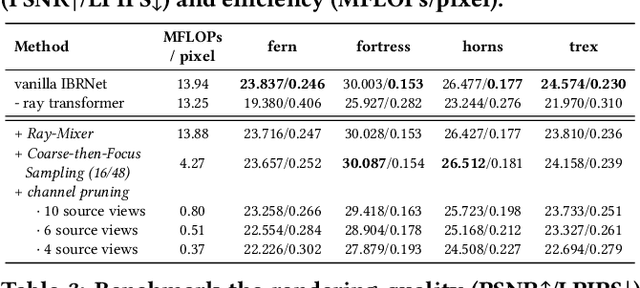
Novel view synthesis is an essential functionality for enabling immersive experiences in various Augmented- and Virtual-Reality (AR/VR) applications, for which generalizable Neural Radiance Fields (NeRFs) have gained increasing popularity thanks to their cross-scene generalization capability. Despite their promise, the real-device deployment of generalizable NeRFs is bottlenecked by their prohibitive complexity due to the required massive memory accesses to acquire scene features, causing their ray marching process to be memory-bounded. To this end, we propose Gen-NeRF, an algorithm-hardware co-design framework dedicated to generalizable NeRF acceleration, which for the first time enables real-time generalizable NeRFs. On the algorithm side, Gen-NeRF integrates a coarse-then-focus sampling strategy, leveraging the fact that different regions of a 3D scene contribute differently to the rendered pixel, to enable sparse yet effective sampling. On the hardware side, Gen-NeRF highlights an accelerator micro-architecture to maximize the data reuse opportunities among different rays by making use of their epipolar geometric relationship. Furthermore, our Gen-NeRF accelerator features a customized dataflow to enhance data locality during point-to-hardware mapping and an optimized scene feature storage strategy to minimize memory bank conflicts. Extensive experiments validate the effectiveness of our proposed Gen-NeRF framework in enabling real-time and generalizable novel view synthesis.