 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProsodyLM: Uncovering the Emerging Prosody Processing Capabilities in Speech Language Models
Jul 27, 2025Speech language models refer to language models with speech processing and understanding capabilities. One key desirable capability for speech language models is the ability to capture the intricate interdependency between content and prosody. The existing mainstream paradigm of training speech language models, which converts speech into discrete tokens before feeding them into LLMs, is sub-optimal in learning prosody information -- we find that the resulting LLMs do not exhibit obvious emerging prosody processing capabilities via pre-training alone. To overcome this, we propose ProsodyLM, which introduces a simple tokenization scheme amenable to learning prosody. Each speech utterance is first transcribed into text, followed by a sequence of word-level prosody tokens. Compared with conventional speech tokenization schemes, the proposed tokenization scheme retains more complete prosody information, and is more understandable to text-based LLMs. We find that ProsodyLM can learn surprisingly diverse emerging prosody processing capabilities through pre-training alone, ranging from harnessing the prosody nuances in generated speech, such as contrastive focus, understanding emotion and stress in an utterance, to maintaining prosody consistency in long contexts.
A Hierarchical Probabilistic Framework for Incremental Knowledge Tracing in Classroom Settings
Jun 11, 2025Knowledge tracing (KT) aims to estimate a student's evolving knowledge state and predict their performance on new exercises based on performance history. Many realistic classroom settings for KT are typically low-resource in data and require online updates as students' exercise history grows, which creates significant challenges for existing KT approaches. To restore strong performance under low-resource conditions, we revisit the hierarchical knowledge concept (KC) information, which is typically available in many classroom settings and can provide strong prior when data are sparse. We therefore propose Knowledge-Tree-based Knowledge Tracing (KT$^2$), a probabilistic KT framework that models student understanding over a tree-structured hierarchy of knowledge concepts using a Hidden Markov Tree Model. KT$^2$ estimates student mastery via an EM algorithm and supports personalized prediction through an incremental update mechanism as new responses arrive. Our experiments show that KT$^2$ consistently outperforms strong baselines in realistic online, low-resource settings.
ThinkPrune: Pruning Long Chain-of-Thought of LLMs via Reinforcement Learning
Apr 02, 2025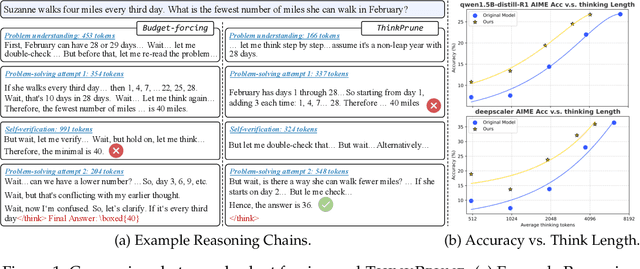
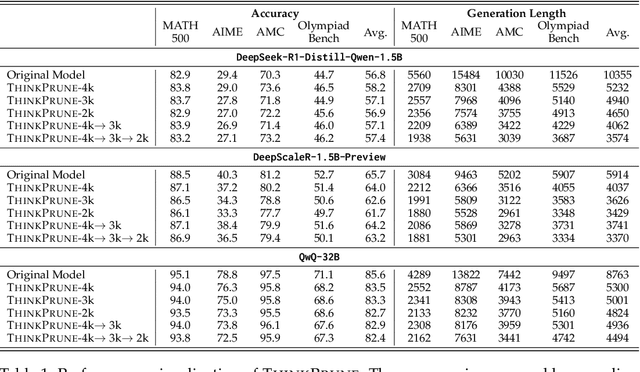
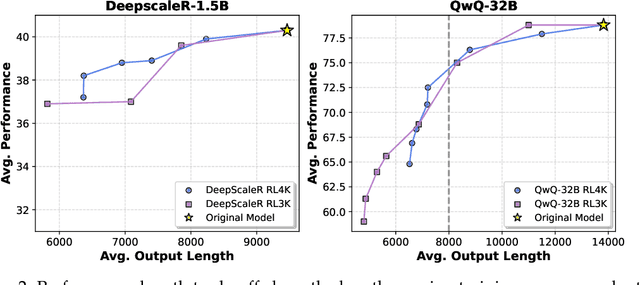
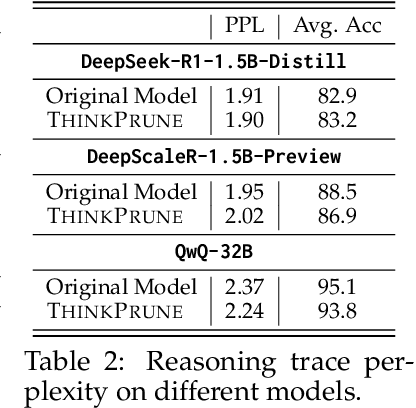
We present ThinkPrune, a simple yet effective method for pruning the thinking length for long-thinking LLMs, which has been found to often produce inefficient and redundant thinking processes. Existing preliminary explorations of reducing thinking length primarily focus on forcing the thinking process to early exit, rather than adapting the LLM to optimize and consolidate the thinking process, and therefore the length-performance tradeoff observed so far is sub-optimal. To fill this gap, ThinkPrune offers a simple solution that continuously trains the long-thinking LLMs via reinforcement learning (RL) with an added token limit, beyond which any unfinished thoughts and answers will be discarded, resulting in a zero reward. To further preserve model performance, we introduce an iterative length pruning approach, where multiple rounds of RL are conducted, each with an increasingly more stringent token limit. We observed that ThinkPrune results in a remarkable performance-length tradeoff -- on the AIME24 dataset, the reasoning length of DeepSeek-R1-Distill-Qwen-1.5B can be reduced by half with only 2% drop in performance. We also observed that after pruning, the LLMs can bypass unnecessary steps while keeping the core reasoning process complete. Code is available at https://github.com/UCSB-NLP-Chang/ThinkPrune.
PLAY2PROMPT: Zero-shot Tool Instruction Optimization for LLM Agents via Tool Play
Mar 18, 2025



Large language models (LLMs) are increasingly integrated with specialized external tools, yet many tasks demand zero-shot tool usage with minimal or noisy documentation. Existing solutions rely on manual rewriting or labeled data for validation, making them inapplicable in true zero-shot settings. To address these challenges, we propose PLAY2PROMPT, an automated framework that systematically "plays" with each tool to explore its input-output behaviors. Through this iterative trial-and-error process, PLAY2PROMPT refines tool documentation and generates usage examples without any labeled data. These examples not only guide LLM inference but also serve as validation to further enhance tool utilization. Extensive experiments on real-world tasks demonstrate that PLAY2PROMPT significantly improves zero-shot tool performance across both open and closed models, offering a scalable and effective solution for domain-specific tool integration.
UniMuMo: Unified Text, Music and Motion Generation
Oct 06, 2024



We introduce UniMuMo, a unified multimodal model capable of taking arbitrary text, music, and motion data as input conditions to generate outputs across all three modalities. To address the lack of time-synchronized data, we align unpaired music and motion data based on rhythmic patterns to leverage existing large-scale music-only and motion-only datasets. By converting music, motion, and text into token-based representation, our model bridges these modalities through a unified encoder-decoder transformer architecture. To support multiple generation tasks within a single framework, we introduce several architectural improvements. We propose encoding motion with a music codebook, mapping motion into the same feature space as music. We introduce a music-motion parallel generation scheme that unifies all music and motion generation tasks into a single transformer decoder architecture with a single training task of music-motion joint generation. Moreover, the model is designed by fine-tuning existing pre-trained single-modality models, significantly reducing computational demands. Extensive experiments demonstrate that UniMuMo achieves competitive results on all unidirectional generation benchmarks across music, motion, and text modalities. Quantitative results are available in the \href{https://hanyangclarence.github.io/unimumo_demo/}{project page}.
Towards Unsupervised Speech Recognition Without Pronunciation Models
Jun 12, 2024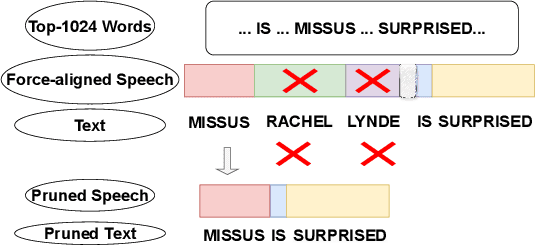
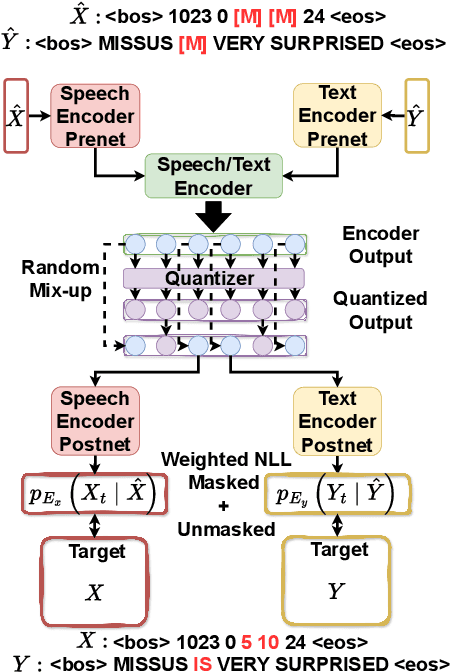
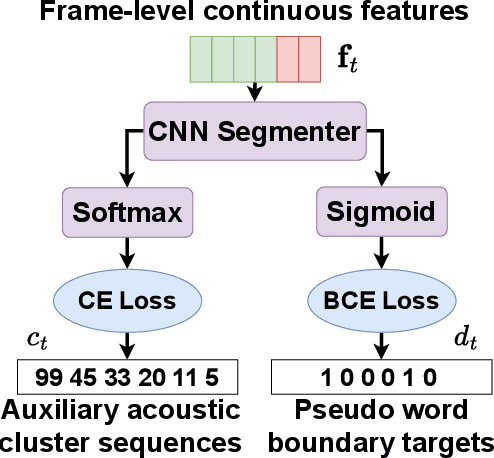
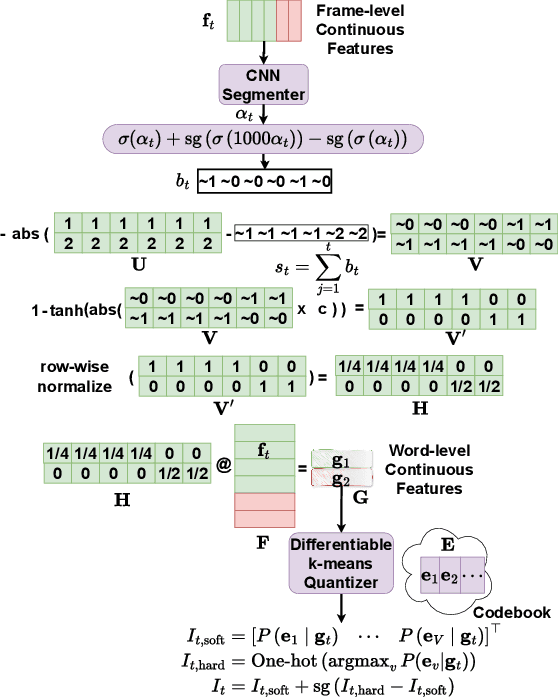
Recent advancements in supervised automatic speech recognition (ASR) have achieved remarkable performance, largely due to the growing availability of large transcribed speech corpora. However, most languages lack sufficient paired speech and text data to effectively train these systems. In this article, we tackle the challenge of developing ASR systems without paired speech and text corpora by proposing the removal of reliance on a phoneme lexicon. We explore a new research direction: word-level unsupervised ASR. Using a curated speech corpus containing only high-frequency English words, our system achieves a word error rate of nearly 20% without parallel transcripts or oracle word boundaries. Furthermore, we experimentally demonstrate that an unsupervised speech recognizer can emerge from joint speech-to-speech and text-to-text masked token-infilling. This innovative model surpasses the performance of previous unsupervised ASR models trained with direct distribution matching.
RapVerse: Coherent Vocals and Whole-Body Motions Generations from Text
May 30, 2024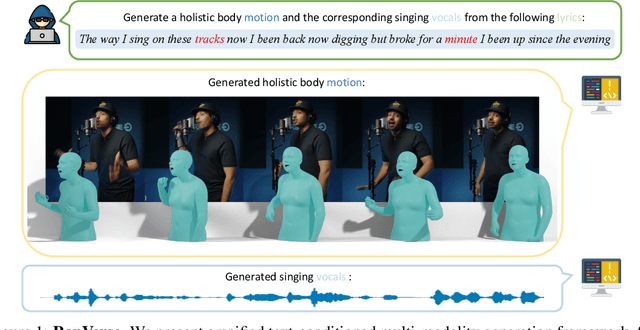
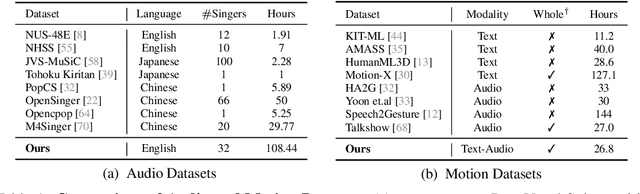
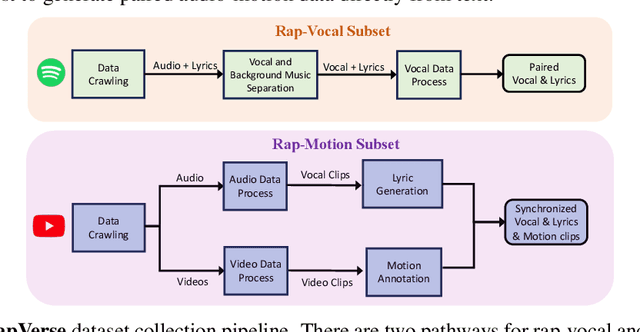
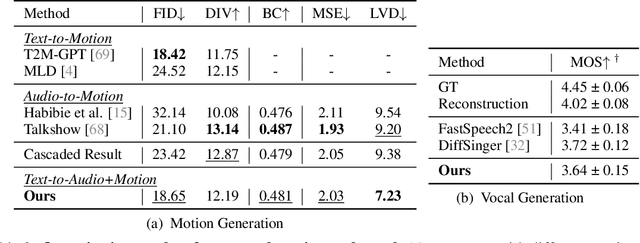
In this work, we introduce a challenging task for simultaneously generating 3D holistic body motions and singing vocals directly from textual lyrics inputs, advancing beyond existing works that typically address these two modalities in isolation. To facilitate this, we first collect the RapVerse dataset, a large dataset containing synchronous rapping vocals, lyrics, and high-quality 3D holistic body meshes. With the RapVerse dataset, we investigate the extent to which scaling autoregressive multimodal transformers across language, audio, and motion can enhance the coherent and realistic generation of vocals and whole-body human motions. For modality unification, a vector-quantized variational autoencoder is employed to encode whole-body motion sequences into discrete motion tokens, while a vocal-to-unit model is leveraged to obtain quantized audio tokens preserving content, prosodic information, and singer identity. By jointly performing transformer modeling on these three modalities in a unified way, our framework ensures a seamless and realistic blend of vocals and human motions. Extensive experiments demonstrate that our unified generation framework not only produces coherent and realistic singing vocals alongside human motions directly from textual inputs but also rivals the performance of specialized single-modality generation systems, establishing new benchmarks for joint vocal-motion generation. The project page is available for research purposes at https://vis-www.cs.umass.edu/RapVerse.
Decomposing Uncertainty for Large Language Models through Input Clarification Ensembling
Nov 15, 2023



Uncertainty decomposition refers to the task of decomposing the total uncertainty of a model into data (aleatoric) uncertainty, resulting from the inherent complexity or ambiguity of the data, and model (epistemic) uncertainty, resulting from the lack of knowledge in the model. Performing uncertainty decomposition for large language models (LLMs) is an important step toward improving the reliability, trustworthiness, and interpretability of LLMs, but this research task is very challenging and remains unresolved. The existing canonical method, Bayesian Neural Network (BNN), cannot be applied to LLMs, because BNN requires training and ensembling multiple variants of models, which is infeasible or prohibitively expensive for LLMs. In this paper, we introduce an uncertainty decomposition framework for LLMs, called input clarifications ensemble, which bypasses the need to train new models. Rather than ensembling models with different parameters, our approach generates a set of clarifications for the input, feeds them into the fixed LLMs, and ensembles the corresponding predictions. We show that our framework shares a symmetric decomposition structure with BNN. Empirical evaluations demonstrate that the proposed framework provides accurate and reliable uncertainty quantification on various tasks. Code will be made publicly available at https://github.com/UCSB-NLP-Chang/llm_uncertainty .
Master-ASR: Achieving Multilingual Scalability and Low-Resource Adaptation in ASR with Modular Learning
Jun 23, 2023
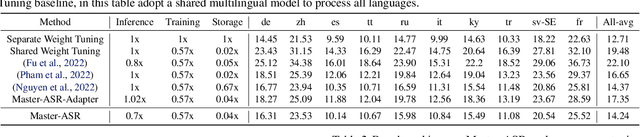
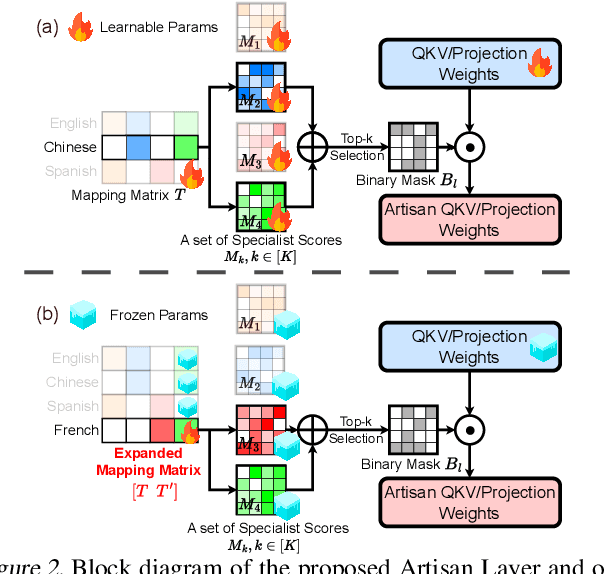
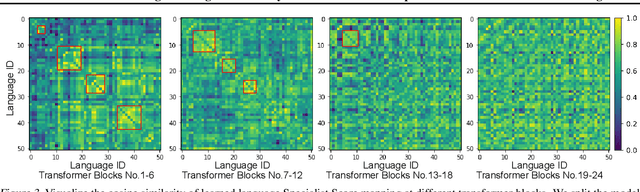
Despite the impressive performance recently achieved by automatic speech recognition (ASR), we observe two primary challenges that hinder its broader applications: (1) The difficulty of introducing scalability into the model to support more languages with limited training, inference, and storage overhead; (2) The low-resource adaptation ability that enables effective low-resource adaptation while avoiding over-fitting and catastrophic forgetting issues. Inspired by recent findings, we hypothesize that we can address the above challenges with modules widely shared across languages. To this end, we propose an ASR framework, dubbed \METHODNS, that, \textit{for the first time}, simultaneously achieves strong multilingual scalability and low-resource adaptation ability thanks to its modularize-then-assemble strategy. Specifically, \METHOD learns a small set of generalizable sub-modules and adaptively assembles them for different languages to reduce the multilingual overhead and enable effective knowledge transfer for low-resource adaptation. Extensive experiments and visualizations demonstrate that \METHOD can effectively discover language similarity and improve multilingual and low-resource ASR performance over state-of-the-art (SOTA) methods, e.g., under multilingual-ASR, our framework achieves a 0.13$\sim$2.41 lower character error rate (CER) with 30\% smaller inference overhead over SOTA solutions on multilingual ASR and a comparable CER, with nearly 50 times fewer trainable parameters over SOTA solutions on low-resource tuning, respectively.
Physics-Driven Diffusion Models for Impact Sound Synthesis from Videos
Apr 11, 2023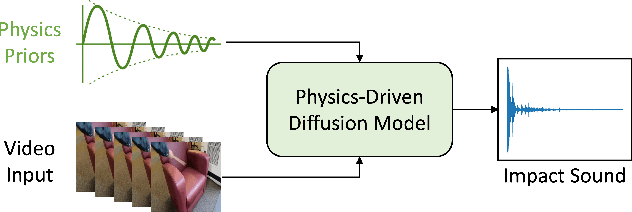
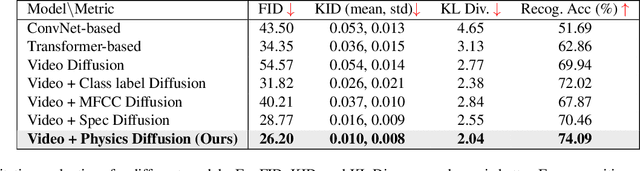
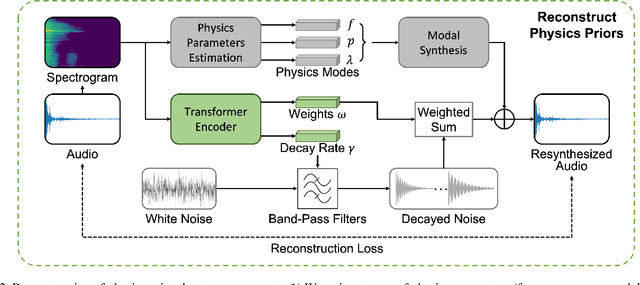
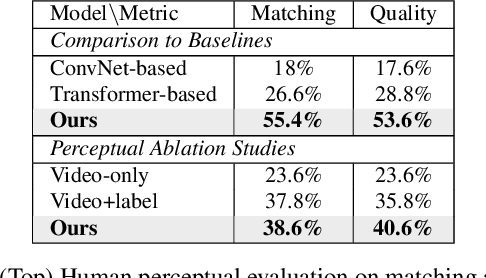
Modeling sounds emitted from physical object interactions is critical for immersive perceptual experiences in real and virtual worlds. Traditional methods of impact sound synthesis use physics simulation to obtain a set of physics parameters that could represent and synthesize the sound. However, they require fine details of both the object geometries and impact locations, which are rarely available in the real world and can not be applied to synthesize impact sounds from common videos. On the other hand, existing video-driven deep learning-based approaches could only capture the weak correspondence between visual content and impact sounds since they lack of physics knowledge. In this work, we propose a physics-driven diffusion model that can synthesize high-fidelity impact sound for a silent video clip. In addition to the video content, we propose to use additional physics priors to guide the impact sound synthesis procedure. The physics priors include both physics parameters that are directly estimated from noisy real-world impact sound examples without sophisticated setup and learned residual parameters that interpret the sound environment via neural networks. We further implement a novel diffusion model with specific training and inference strategies to combine physics priors and visual information for impact sound synthesis. Experimental results show that our model outperforms several existing systems in generating realistic impact sounds. More importantly, the physics-based representations are fully interpretable and transparent, thus enabling us to perform sound editing flexibly.