 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalkCuts: A Large-Scale Dataset for Multi-Shot Human Speech Video Generation
Oct 08, 2025In this work, we present TalkCuts, a large-scale dataset designed to facilitate the study of multi-shot human speech video generation. Unlike existing datasets that focus on single-shot, static viewpoints, TalkCuts offers 164k clips totaling over 500 hours of high-quality human speech videos with diverse camera shots, including close-up, half-body, and full-body views. The dataset includes detailed textual descriptions, 2D keypoints and 3D SMPL-X motion annotations, covering over 10k identities, enabling multimodal learning and evaluation. As a first attempt to showcase the value of the dataset, we present Orator, an LLM-guided multi-modal generation framework as a simple baseline, where the language model functions as a multi-faceted director, orchestrating detailed specifications for camera transitions, speaker gesticulations, and vocal modulation. This architecture enables the synthesis of coherent long-form videos through our integrated multi-modal video generation module. Extensive experiments in both pose-guided and audio-driven settings show that training on TalkCuts significantly enhances the cinematographic coherence and visual appeal of generated multi-shot speech videos. We believe TalkCuts provides a strong foundation for future work in controllable, multi-shot speech video generation and broader multimodal learning.
Towards Understanding Camera Motions in Any Video
Apr 21, 2025
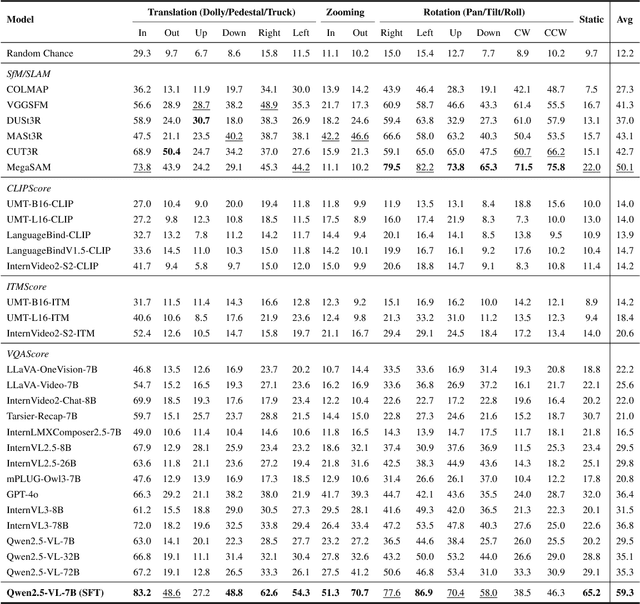
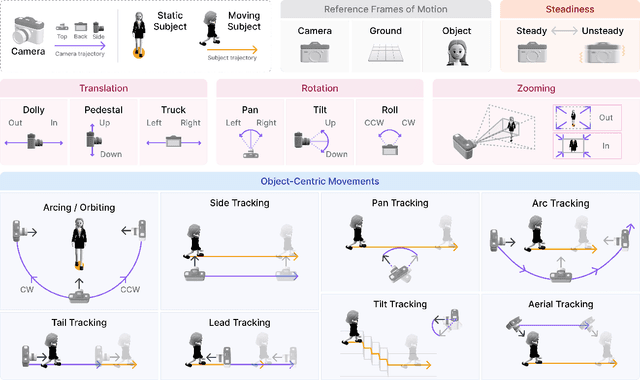
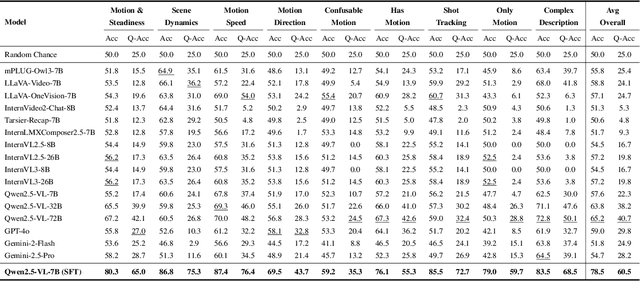
We introduce CameraBench, a large-scale dataset and benchmark designed to assess and improve camera motion understanding. CameraBench consists of ~3,000 diverse internet videos, annotated by experts through a rigorous multi-stage quality control process. One of our contributions is a taxonomy of camera motion primitives, designed in collaboration with cinematographers. We find, for example, that some motions like "follow" (or tracking) require understanding scene content like moving subjects. We conduct a large-scale human study to quantify human annotation performance, revealing that domain expertise and tutorial-based training can significantly enhance accuracy. For example, a novice may confuse zoom-in (a change of intrinsics) with translating forward (a change of extrinsics), but can be trained to differentiate the two. Using CameraBench, we evaluate Structure-from-Motion (SfM) and Video-Language Models (VLMs), finding that SfM models struggle to capture semantic primitives that depend on scene content, while VLMs struggle to capture geometric primitives that require precise estimation of trajectories. We then fine-tune a generative VLM on CameraBench to achieve the best of both worlds and showcase its applications, including motion-augmented captioning, video question answering, and video-text retrieval. We hope our taxonomy, benchmark, and tutorials will drive future efforts towards the ultimate goal of understanding camera motions in any video.
RapVerse: Coherent Vocals and Whole-Body Motions Generations from Text
May 30, 2024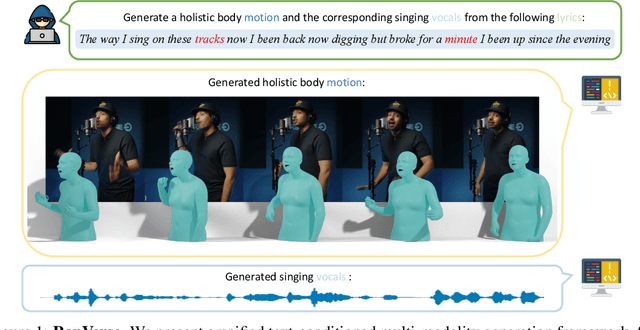
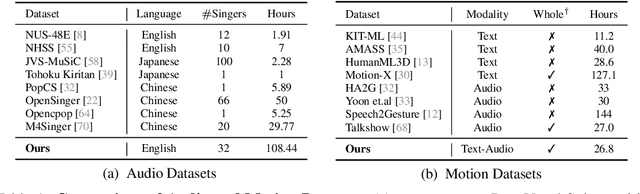
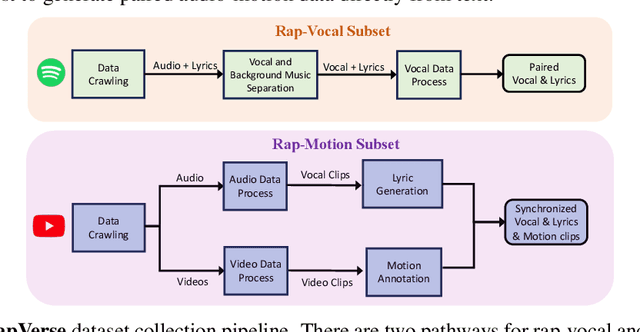
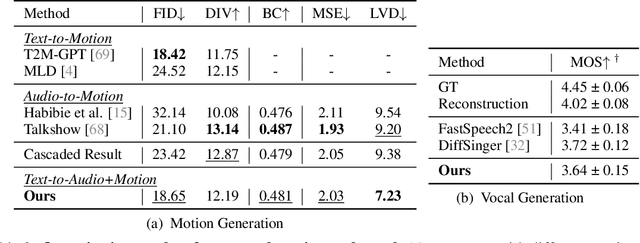
In this work, we introduce a challenging task for simultaneously generating 3D holistic body motions and singing vocals directly from textual lyrics inputs, advancing beyond existing works that typically address these two modalities in isolation. To facilitate this, we first collect the RapVerse dataset, a large dataset containing synchronous rapping vocals, lyrics, and high-quality 3D holistic body meshes. With the RapVerse dataset, we investigate the extent to which scaling autoregressive multimodal transformers across language, audio, and motion can enhance the coherent and realistic generation of vocals and whole-body human motions. For modality unification, a vector-quantized variational autoencoder is employed to encode whole-body motion sequences into discrete motion tokens, while a vocal-to-unit model is leveraged to obtain quantized audio tokens preserving content, prosodic information, and singer identity. By jointly performing transformer modeling on these three modalities in a unified way, our framework ensures a seamless and realistic blend of vocals and human motions. Extensive experiments demonstrate that our unified generation framework not only produces coherent and realistic singing vocals alongside human motions directly from textual inputs but also rivals the performance of specialized single-modality generation systems, establishing new benchmarks for joint vocal-motion generation. The project page is available for research purposes at https://vis-www.cs.umass.edu/RapVerse.