 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: The Inevitable End of One-Architecture-Fits-All-Domains in Time Series Forecasting
Feb 02, 2026Recent work has questioned the effectiveness and robustness of neural network architectures for time series forecasting tasks. We summarize these concerns and analyze groundly their inherent limitations: i.e. the irreconcilable conflict between single (or few similar) domains SOTA and generalizability over general domains for time series forecasting neural network architecture designs. Moreover, neural networks architectures for general domain time series forecasting are becoming more and more complicated and their performance has almost saturated in recent years. As a result, network architectures developed aiming at fitting general time series domains are almost not inspiring for real world practices for certain single (or few similar) domains such as Finance, Weather, Traffic, etc: each specific domain develops their own methods that rarely utilize advances in neural network architectures of time series community in recent 2-3 years. As a result, we call for the time series community to shift focus away from research on time series neural network architectures for general domains: these researches have become saturated and away from domain-specific SOTAs over time. We should either (1) focus on deep learning methods for certain specific domain(s), or (2) turn to the development of meta-learning methods for general domains.
ERA: Transforming VLMs into Embodied Agents via Embodied Prior Learning and Online Reinforcement Learning
Oct 14, 2025Recent advances in embodied AI highlight the potential of vision language models (VLMs) as agents capable of perception, reasoning, and interaction in complex environments. However, top-performing systems rely on large-scale models that are costly to deploy, while smaller VLMs lack the necessary knowledge and skills to succeed. To bridge this gap, we present \textit{Embodied Reasoning Agent (ERA)}, a two-stage framework that integrates prior knowledge learning and online reinforcement learning (RL). The first stage, \textit{Embodied Prior Learning}, distills foundational knowledge from three types of data: (1) Trajectory-Augmented Priors, which enrich existing trajectory data with structured reasoning generated by stronger models; (2) Environment-Anchored Priors, which provide in-environment knowledge and grounding supervision; and (3) External Knowledge Priors, which transfer general knowledge from out-of-environment datasets. In the second stage, we develop an online RL pipeline that builds on these priors to further enhance agent performance. To overcome the inherent challenges in agent RL, including long horizons, sparse rewards, and training instability, we introduce three key designs: self-summarization for context management, dense reward shaping, and turn-level policy optimization. Extensive experiments on both high-level planning (EB-ALFRED) and low-level control (EB-Manipulation) tasks demonstrate that ERA-3B surpasses both prompting-based large models and previous training-based baselines. Specifically, it achieves overall improvements of 8.4\% on EB-ALFRED and 19.4\% on EB-Manipulation over GPT-4o, and exhibits strong generalization to unseen tasks. Overall, ERA offers a practical path toward scalable embodied intelligence, providing methodological insights for future embodied AI systems.
Gradient Imbalance in Direct Preference Optimization
Feb 28, 2025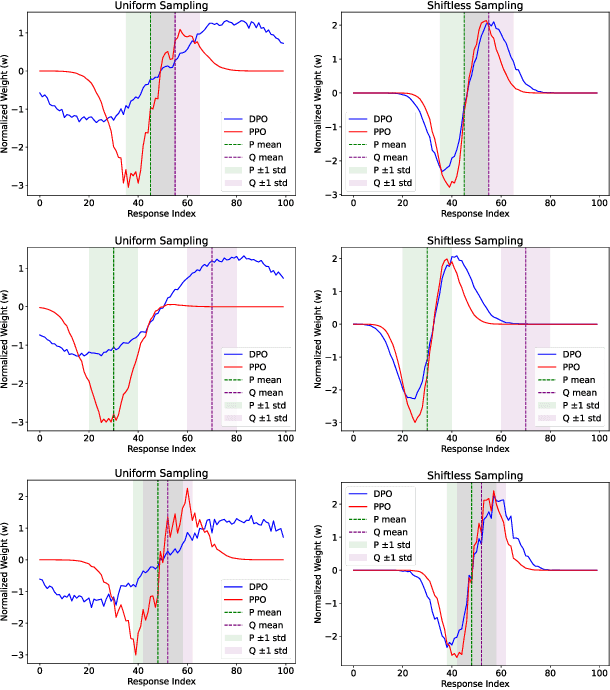
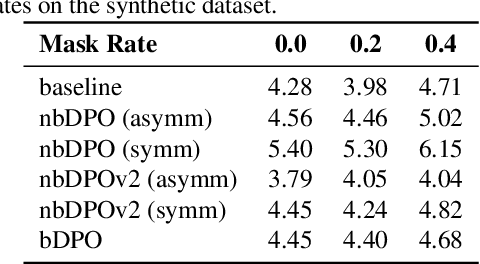
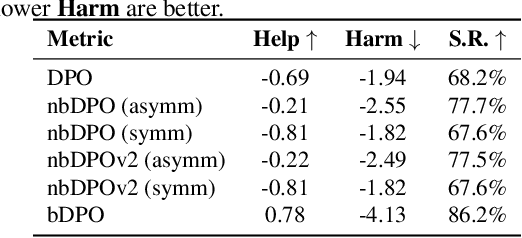
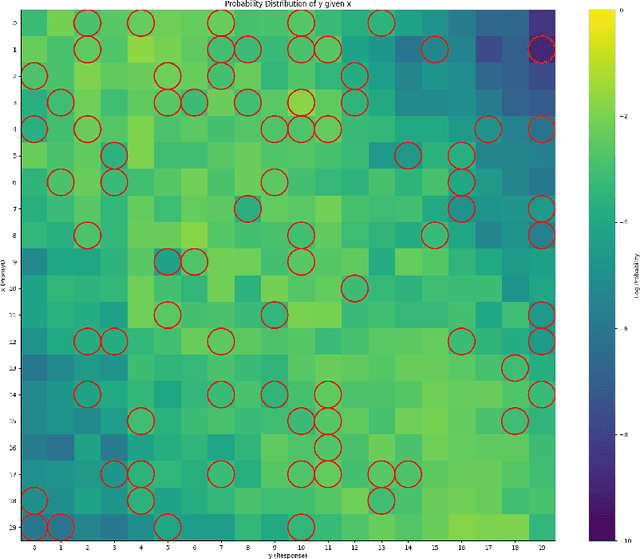
Direct Preference Optimization (DPO) has been proposed as a promising alternative to Proximal Policy Optimization (PPO) based Reinforcement Learning with Human Feedback (RLHF). However, empirical evaluations consistently reveal suboptimal performance in DPO compared to common RLHF pipelines. In this work, we conduct a systematic analysis of DPO's training dynamics and identify gradient imbalance as a critical limitation. We demonstrate theoretically and empirically that this imbalance perturbs optimization trajectories, destabilizes learning, and induces suboptimal convergence. To address this issue, we propose Balanced-DPO, a simple yet effective modification to the DPO objective that introduces a computationally efficient gradient reweighting mechanism. Our experiments demonstrate the effectiveness of Balanced-DPO, validating the theoretical findings and confirming that addressing gradient imbalance is key to improving DPO's performance, highlighting a promising direction for future research.
Explaining Context Length Scaling and Bounds for Language Models
Feb 03, 2025Long Context Language Models have drawn great attention in the past few years. There has been work discussing the impact of long context on Language Model performance: some find that long irrelevant context could harm performance, while some experimentally summarize loss reduction by relevant long context as Scaling Laws. This calls for a more thorough understanding on how long context impact Language Modeling. In this work, we (1) propose a clean and effective theoretical framework on explaining the impact of context length to Language Modeling, from an Intrinsic Space perspective; and (2) conduct experiments on natural language and synthetic data, validating our proposed theoretical assumptions and deductions. Our theoretical framework can provide practical insights such as establishing that training dataset size dictates an optimal context length and bounds context length scaling for certain case. We hope our work may inspire new long context Language Models, as well as future work studying Physics for Language Models. Code for our experiments is available at this url: https://github.com/JingzheShi/NLPCtlScalingAndBounds.
Physics-Informed Neural Network Based Digital Image Correlation Method
Sep 02, 2024Digital Image Correlation (DIC) is a key technique in experimental mechanics for full-field deformation measurement, traditionally relying on subset matching to determine displacement fields. However, selecting optimal parameters like shape functions and subset size can be challenging in non-uniform deformation scenarios. Recent deep learning-based DIC approaches, both supervised and unsupervised, use neural networks to map speckle images to deformation fields, offering precise measurements without manual tuning. However, these methods require complex network architectures to extract speckle image features, which does not guarantee solution accuracy This paper introduces PINN-DIC, a novel DIC method based on Physics-Informed Neural Networks (PINNs). Unlike traditional approaches, PINN-DIC uses a simple fully connected neural network that takes the coordinate domain as input and outputs the displacement field. By integrating the DIC governing equation into the loss function, PINN-DIC directly extracts the displacement field from reference and deformed speckle images through iterative optimization. Evaluations on simulated and real experiments demonstrate that PINN-DIC maintains the accuracy of deep learning-based DIC in non-uniform fields while offering three distinct advantages: 1) enhanced precision with a simpler network by directly fitting the displacement field from coordinates, 2) effective handling of irregular boundary displacement fields with minimal parameter adjustments, and 3) easy integration with other neural network-based mechanical analysis methods for comprehensive DIC result analysis.
RapVerse: Coherent Vocals and Whole-Body Motions Generations from Text
May 30, 2024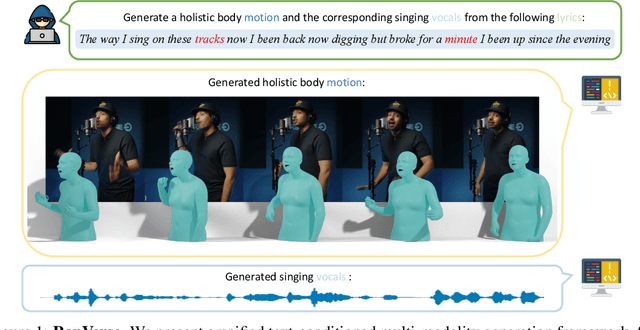
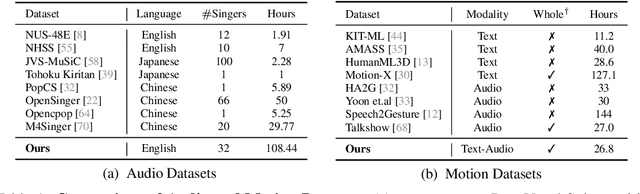
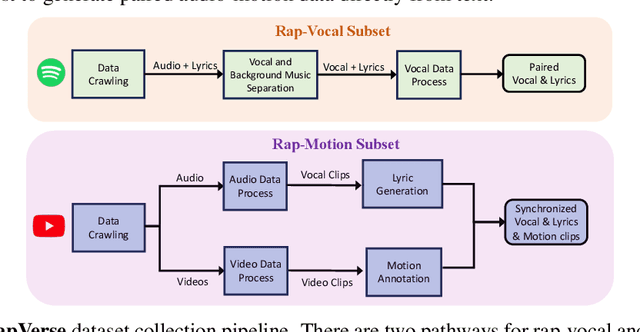
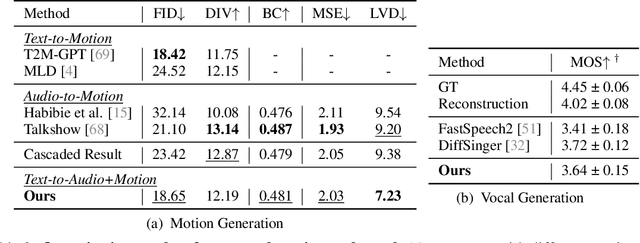
In this work, we introduce a challenging task for simultaneously generating 3D holistic body motions and singing vocals directly from textual lyrics inputs, advancing beyond existing works that typically address these two modalities in isolation. To facilitate this, we first collect the RapVerse dataset, a large dataset containing synchronous rapping vocals, lyrics, and high-quality 3D holistic body meshes. With the RapVerse dataset, we investigate the extent to which scaling autoregressive multimodal transformers across language, audio, and motion can enhance the coherent and realistic generation of vocals and whole-body human motions. For modality unification, a vector-quantized variational autoencoder is employed to encode whole-body motion sequences into discrete motion tokens, while a vocal-to-unit model is leveraged to obtain quantized audio tokens preserving content, prosodic information, and singer identity. By jointly performing transformer modeling on these three modalities in a unified way, our framework ensures a seamless and realistic blend of vocals and human motions. Extensive experiments demonstrate that our unified generation framework not only produces coherent and realistic singing vocals alongside human motions directly from textual inputs but also rivals the performance of specialized single-modality generation systems, establishing new benchmarks for joint vocal-motion generation. The project page is available for research purposes at https://vis-www.cs.umass.edu/RapVerse.
Scaling Law for Time Series Forecasting
May 27, 2024



Scaling law that rewards large datasets, complex models and enhanced data granularity has been observed in various fields of deep learning. Yet, studies on time series forecasting have cast doubt on scaling behaviors of deep learning methods for time series forecasting: while more training data improves performance, more capable models do not always outperform less capable models, and longer input horizons may hurt performance for some models. We propose a theory for scaling law for time series forecasting that can explain these seemingly abnormal behaviors. We take into account the impact of dataset size and model complexity, as well as time series data granularity, particularly focusing on the look-back horizon, an aspect that has been unexplored in previous theories. Furthermore, we empirically evaluate various models using a diverse set of time series forecasting datasets, which (1) verifies the validity of scaling law on dataset size and model complexity within the realm of time series forecasting, and (2) validates our theoretical framework, particularly regarding the influence of look back horizon. We hope our findings may inspire new models targeting time series forecasting datasets of limited size, as well as large foundational datasets and models for time series forecasting in future works.\footnote{Codes for our experiments will be made public at: \url{https://github.com/JingzheShi/ScalingLawForTimeSeriesForecasting}.
CHOPS: CHat with custOmer Profile Systems for Customer Service with LLMs
Apr 15, 2024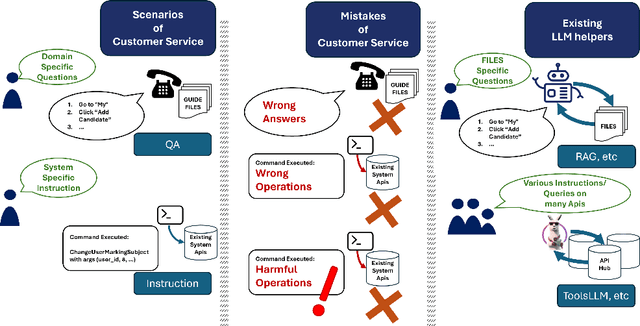

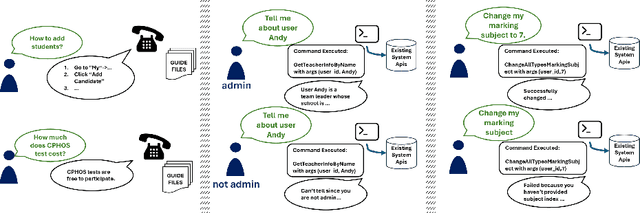

Businesses and software platforms are increasingly turning to Large Language Models (LLMs) such as GPT-3.5, GPT-4, GLM-3, and LLaMa-2 for chat assistance with file access or as reasoning agents for customer service. However, current LLM-based customer service models have limited integration with customer profiles and lack the operational capabilities necessary for effective service. Moreover, existing API integrations emphasize diversity over the precision and error avoidance essential in real-world customer service scenarios. To address these issues, we propose an LLM agent named CHOPS (CHat with custOmer Profile in existing System), designed to: (1) efficiently utilize existing databases or systems for accessing user information or interacting with these systems following existing guidelines; (2) provide accurate and reasonable responses or carry out required operations in the system while avoiding harmful operations; and (3) leverage a combination of small and large LLMs to achieve satisfying performance at a reasonable inference cost. We introduce a practical dataset, the CPHOS-dataset, which includes a database, guiding files, and QA pairs collected from CPHOS, an online platform that facilitates the organization of simulated Physics Olympiads for high school teachers and students. We have conducted extensive experiments to validate the performance of our proposed CHOPS architecture using the CPHOS-dataset, with the aim of demonstrating how LLMs can enhance or serve as alternatives to human customer service. Code for our proposed architecture and dataset can be found at {https://github.com/JingzheShi/CHOPS}.