 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Spatial Memory with Elastic Test-Time Training
Apr 08, 2026Large Chunk Test-Time Training (LaCT) has shown strong performance on long-context 3D reconstruction, but its fully plastic inference-time updates remain vulnerable to catastrophic forgetting and overfitting. As a result, LaCT is typically instantiated with a single large chunk spanning the full input sequence, falling short of the broader goal of handling arbitrarily long sequences in a single pass. We propose Elastic Test-Time Training inspired by elastic weight consolidation, that stabilizes LaCT fast-weight updates with a Fisher-weighted elastic prior around a maintained anchor state. The anchor evolves as an exponential moving average of past fast weights to balance stability and plasticity. Based on this updated architecture, we introduce Fast Spatial Memory (FSM), an efficient and scalable model for 4D reconstruction that learns spatiotemporal representations from long observation sequences and renders novel view-time combinations. We pre-trained FSM on large-scale curated 3D/4D data to capture the dynamics and semantics of complex spatial environments. Extensive experiments show that FSM supports fast adaptation over long sequences and delivers high-quality 3D/4D reconstruction with smaller chunks and mitigating the camera-interpolation shortcut. Overall, we hope to advance LaCT beyond the bounded single-chunk setting toward robust multi-chunk adaptation, a necessary step for generalization to genuinely longer sequences, while substantially alleviating the activation-memory bottleneck.
Action Images: End-to-End Policy Learning via Multiview Video Generation
Apr 07, 2026World action models (WAMs) have emerged as a promising direction for robot policy learning, as they can leverage powerful video backbones to model the future states. However, existing approaches often rely on separate action modules, or use action representations that are not pixel-grounded, making it difficult to fully exploit the pretrained knowledge of video models and limiting transfer across viewpoints and environments. In this work, we present Action Images, a unified world action model that formulates policy learning as multiview video generation. Instead of encoding control as low-dimensional tokens, we translate 7-DoF robot actions into interpretable action images: multi-view action videos that are grounded in 2D pixels and explicitly track robot-arm motion. This pixel-grounded action representation allows the video backbone itself to act as a zero-shot policy, without a separate policy head or action module. Beyond control, the same unified model supports video-action joint generation, action-conditioned video generation, and action labeling under a shared representation. On RLBench and real-world evaluations, our model achieves the strongest zero-shot success rates and improves video-action joint generation quality over prior video-space world models, suggesting that interpretable action images are a promising route to policy learning.
3D-Layout-R1: Structured Reasoning for Language-Instructed Spatial Editing
Mar 23, 2026Large Language Models (LLMs) and Vision Language Models (VLMs) have shown impressive reasoning abilities, yet they struggle with spatial understanding and layout consistency when performing fine-grained visual editing. We introduce a Structured Reasoning framework that performs text-conditioned spatial layout editing via scene-graph reasoning. Given an input scene graph and a natural-language instruction, the model reasons over the graph to generate an updated scene graph that satisfies the text condition while maintaining spatial coherence. By explicitly guiding the reasoning process through structured relational representations, our approach improves both interpretability and control over spatial relationships. We evaluate our method on a new text-guided layout editing benchmark encompassing sorting, spatial alignment, and room-editing tasks. Our training paradigm yields an average 15% improvement in IoU and 25% reduction in center-distance error compared to Chain of Thought Fine-tuning (CoT-SFT) and vanilla GRPO baselines. Compared to SOTA zero-shot LLMs, our best models achieve up to 20% higher mIoU, demonstrating markedly improved spatial precision.
TesserAct: Learning 4D Embodied World Models
Apr 29, 2025



This paper presents an effective approach for learning novel 4D embodied world models, which predict the dynamic evolution of 3D scenes over time in response to an embodied agent's actions, providing both spatial and temporal consistency. We propose to learn a 4D world model by training on RGB-DN (RGB, Depth, and Normal) videos. This not only surpasses traditional 2D models by incorporating detailed shape, configuration, and temporal changes into their predictions, but also allows us to effectively learn accurate inverse dynamic models for an embodied agent. Specifically, we first extend existing robotic manipulation video datasets with depth and normal information leveraging off-the-shelf models. Next, we fine-tune a video generation model on this annotated dataset, which jointly predicts RGB-DN (RGB, Depth, and Normal) for each frame. We then present an algorithm to directly convert generated RGB, Depth, and Normal videos into a high-quality 4D scene of the world. Our method ensures temporal and spatial coherence in 4D scene predictions from embodied scenarios, enables novel view synthesis for embodied environments, and facilitates policy learning that significantly outperforms those derived from prior video-based world models.
RapVerse: Coherent Vocals and Whole-Body Motions Generations from Text
May 30, 2024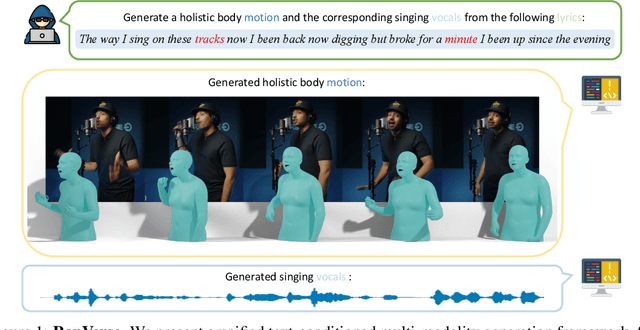
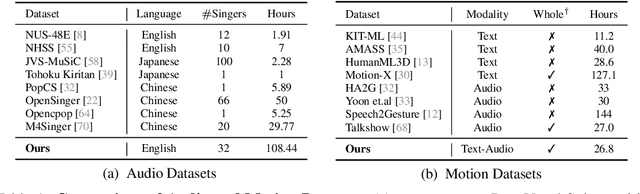
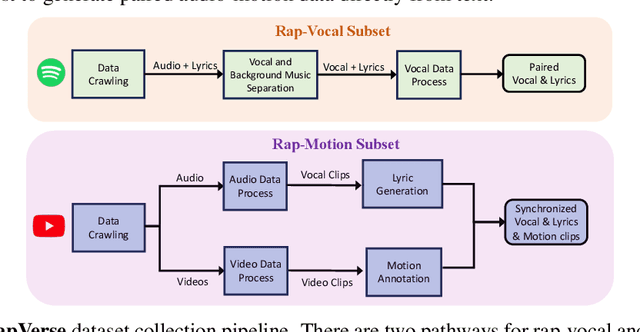
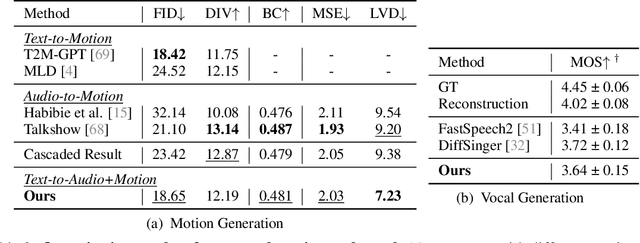
In this work, we introduce a challenging task for simultaneously generating 3D holistic body motions and singing vocals directly from textual lyrics inputs, advancing beyond existing works that typically address these two modalities in isolation. To facilitate this, we first collect the RapVerse dataset, a large dataset containing synchronous rapping vocals, lyrics, and high-quality 3D holistic body meshes. With the RapVerse dataset, we investigate the extent to which scaling autoregressive multimodal transformers across language, audio, and motion can enhance the coherent and realistic generation of vocals and whole-body human motions. For modality unification, a vector-quantized variational autoencoder is employed to encode whole-body motion sequences into discrete motion tokens, while a vocal-to-unit model is leveraged to obtain quantized audio tokens preserving content, prosodic information, and singer identity. By jointly performing transformer modeling on these three modalities in a unified way, our framework ensures a seamless and realistic blend of vocals and human motions. Extensive experiments demonstrate that our unified generation framework not only produces coherent and realistic singing vocals alongside human motions directly from textual inputs but also rivals the performance of specialized single-modality generation systems, establishing new benchmarks for joint vocal-motion generation. The project page is available for research purposes at https://vis-www.cs.umass.edu/RapVerse.
3D-VLA: A 3D Vision-Language-Action Generative World Model
Mar 14, 2024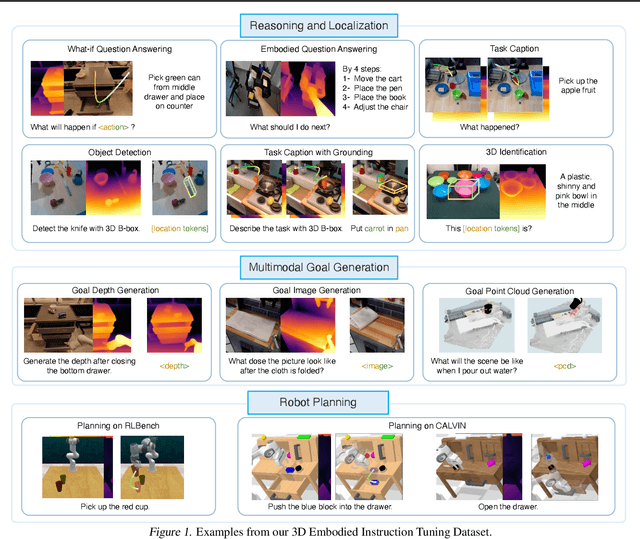
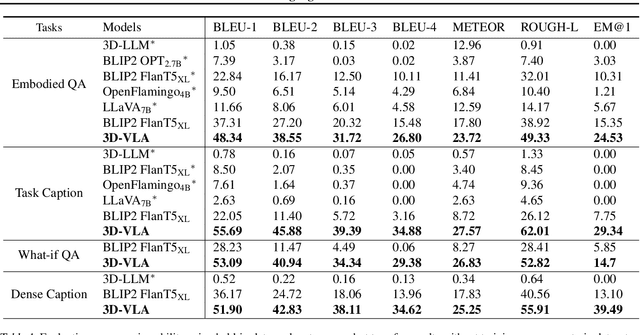
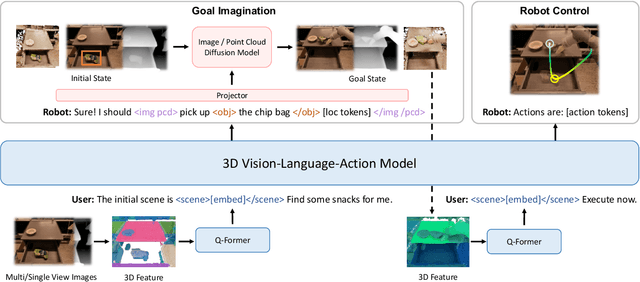
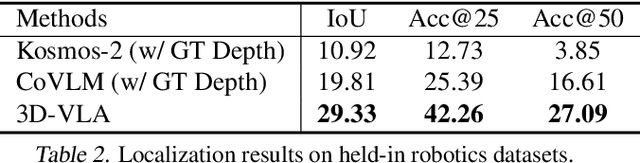
Recent vision-language-action (VLA) models rely on 2D inputs, lacking integration with the broader realm of the 3D physical world. Furthermore, they perform action prediction by learning a direct mapping from perception to action, neglecting the vast dynamics of the world and the relations between actions and dynamics. In contrast, human beings are endowed with world models that depict imagination about future scenarios to plan actions accordingly. To this end, we propose 3D-VLA by introducing a new family of embodied foundation models that seamlessly link 3D perception, reasoning, and action through a generative world model. Specifically, 3D-VLA is built on top of a 3D-based large language model (LLM), and a set of interaction tokens is introduced to engage with the embodied environment. Furthermore, to inject generation abilities into the model, we train a series of embodied diffusion models and align them into the LLM for predicting the goal images and point clouds. To train our 3D-VLA, we curate a large-scale 3D embodied instruction dataset by extracting vast 3D-related information from existing robotics datasets. Our experiments on held-in datasets demonstrate that 3D-VLA significantly improves the reasoning, multimodal generation, and planning capabilities in embodied environments, showcasing its potential in real-world applications.
CHORD: Category-level Hand-held Object Reconstruction via Shape Deformation
Aug 21, 2023



In daily life, humans utilize hands to manipulate objects. Modeling the shape of objects that are manipulated by the hand is essential for AI to comprehend daily tasks and to learn manipulation skills. However, previous approaches have encountered difficulties in reconstructing the precise shapes of hand-held objects, primarily owing to a deficiency in prior shape knowledge and inadequate data for training. As illustrated, given a particular type of tool, such as a mug, despite its infinite variations in shape and appearance, humans have a limited number of 'effective' modes and poses for its manipulation. This can be attributed to the fact that humans have mastered the shape prior of the 'mug' category, and can quickly establish the corresponding relations between different mug instances and the prior, such as where the rim and handle are located. In light of this, we propose a new method, CHORD, for Category-level Hand-held Object Reconstruction via shape Deformation. CHORD deforms a categorical shape prior for reconstructing the intra-class objects. To ensure accurate reconstruction, we empower CHORD with three types of awareness: appearance, shape, and interacting pose. In addition, we have constructed a new dataset, COMIC, of category-level hand-object interaction. COMIC contains a rich array of object instances, materials, hand interactions, and viewing directions. Extensive evaluation shows that CHORD outperforms state-of-the-art approaches in both quantitative and qualitative measures. Code, model, and datasets are available at https://kailinli.github.io/CHORD.
Color-NeuS: Reconstructing Neural Implicit Surfaces with Color
Aug 14, 2023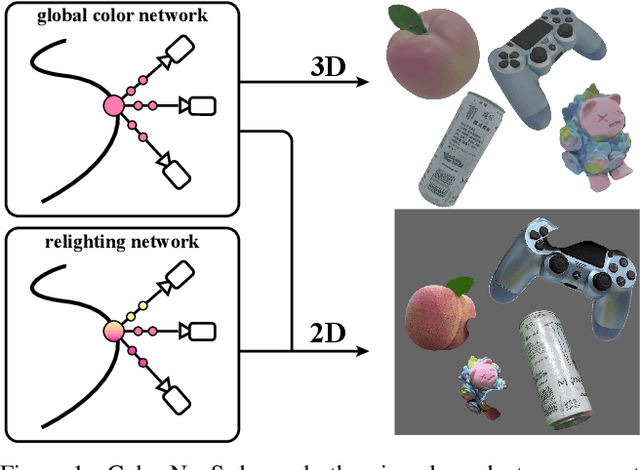

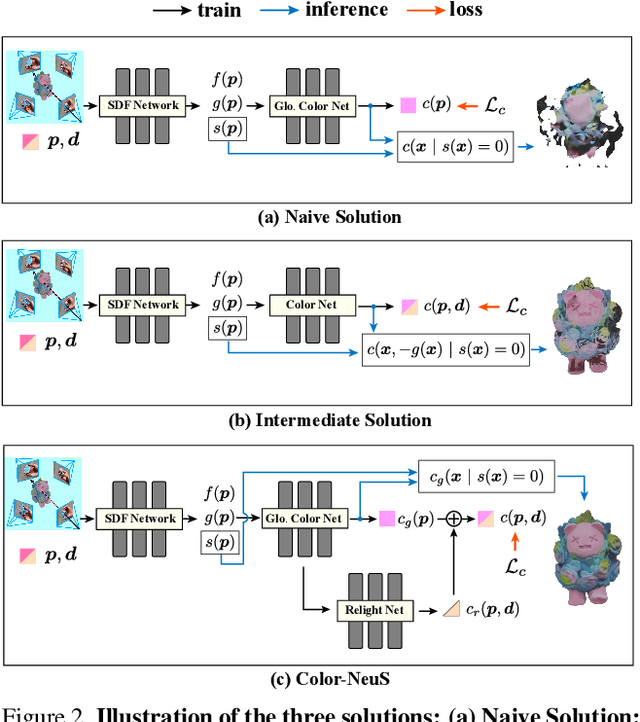

The reconstruction of object surfaces from multi-view images or monocular video is a fundamental issue in computer vision. However, much of the recent research concentrates on reconstructing geometry through implicit or explicit methods. In this paper, we shift our focus towards reconstructing mesh in conjunction with color. We remove the view-dependent color from neural volume rendering while retaining volume rendering performance through a relighting network. Mesh is extracted from the signed distance function (SDF) network for the surface, and color for each surface vertex is drawn from the global color network. To evaluate our approach, we conceived a in hand object scanning task featuring numerous occlusions and dramatic shifts in lighting conditions. We've gathered several videos for this task, and the results surpass those of any existing methods capable of reconstructing mesh alongside color. Additionally, our method's performance was assessed using public datasets, including DTU, BlendedMVS, and OmniObject3D. The results indicated that our method performs well across all these datasets. Project page: https://colmar-zlicheng.github.io/color_neus.
3D-LLM: Injecting the 3D World into Large Language Models
Jul 24, 2023Large language models (LLMs) and Vision-Language Models (VLMs) have been proven to excel at multiple tasks, such as commonsense reasoning. Powerful as these models can be, they are not grounded in the 3D physical world, which involves richer concepts such as spatial relationships, affordances, physics, layout, and so on. In this work, we propose to inject the 3D world into large language models and introduce a whole new family of 3D-LLMs. Specifically, 3D-LLMs can take 3D point clouds and their features as input and perform a diverse set of 3D-related tasks, including captioning, dense captioning, 3D question answering, task decomposition, 3D grounding, 3D-assisted dialog, navigation, and so on. Using three types of prompting mechanisms that we design, we are able to collect over 300k 3D-language data covering these tasks. To efficiently train 3D-LLMs, we first utilize a 3D feature extractor that obtains 3D features from rendered multi- view images. Then, we use 2D VLMs as our backbones to train our 3D-LLMs. By introducing a 3D localization mechanism, 3D-LLMs can better capture 3D spatial information. Experiments on ScanQA show that our model outperforms state-of-the-art baselines by a large margin (e.g., the BLEU-1 score surpasses state-of-the-art score by 9%). Furthermore, experiments on our held-in datasets for 3D captioning, task composition, and 3D-assisted dialogue show that our model outperforms 2D VLMs. Qualitative examples also show that our model could perform more tasks beyond the scope of existing LLMs and VLMs. Project Page: : https://vis-www.cs.umass.edu/3dllm/.