 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotSmith: Generative Robotic Tool Design for Acquisition of Complex Manipulation Skills
Jun 17, 2025



Endowing robots with tool design abilities is critical for enabling them to solve complex manipulation tasks that would otherwise be intractable. While recent generative frameworks can automatically synthesize task settings, such as 3D scenes and reward functions, they have not yet addressed the challenge of tool-use scenarios. Simply retrieving human-designed tools might not be ideal since many tools (e.g., a rolling pin) are difficult for robotic manipulators to handle. Furthermore, existing tool design approaches either rely on predefined templates with limited parameter tuning or apply generic 3D generation methods that are not optimized for tool creation. To address these limitations, we propose RobotSmith, an automated pipeline that leverages the implicit physical knowledge embedded in vision-language models (VLMs) alongside the more accurate physics provided by physics simulations to design and use tools for robotic manipulation. Our system (1) iteratively proposes tool designs using collaborative VLM agents, (2) generates low-level robot trajectories for tool use, and (3) jointly optimizes tool geometry and usage for task performance. We evaluate our approach across a wide range of manipulation tasks involving rigid, deformable, and fluid objects. Experiments show that our method consistently outperforms strong baselines in terms of both task success rate and overall performance. Notably, our approach achieves a 50.0\% average success rate, significantly surpassing other baselines such as 3D generation (21.4%) and tool retrieval (11.1%). Finally, we deploy our system in real-world settings, demonstrating that the generated tools and their usage plans transfer effectively to physical execution, validating the practicality and generalization capabilities of our approach.
LuciBot: Automated Robot Policy Learning from Generated Videos
Mar 12, 2025Automatically generating training supervision for embodied tasks is crucial, as manual designing is tedious and not scalable. While prior works use large language models (LLMs) or vision-language models (VLMs) to generate rewards, these approaches are largely limited to simple tasks with well-defined rewards, such as pick-and-place. This limitation arises because LLMs struggle to interpret complex scenes compressed into text or code due to their restricted input modality, while VLM-based rewards, though better at visual perception, remain limited by their less expressive output modality. To address these challenges, we leverage the imagination capability of general-purpose video generation models. Given an initial simulation frame and a textual task description, the video generation model produces a video demonstrating task completion with correct semantics. We then extract rich supervisory signals from the generated video, including 6D object pose sequences, 2D segmentations, and estimated depth, to facilitate task learning in simulation. Our approach significantly improves supervision quality for complex embodied tasks, enabling large-scale training in simulators.
Articulate AnyMesh: Open-Vocabulary 3D Articulated Objects Modeling
Feb 04, 2025



3D articulated objects modeling has long been a challenging problem, since it requires to capture both accurate surface geometries and semantically meaningful and spatially precise structures, parts, and joints. Existing methods heavily depend on training data from a limited set of handcrafted articulated object categories (e.g., cabinets and drawers), which restricts their ability to model a wide range of articulated objects in an open-vocabulary context. To address these limitations, we propose Articulate Anymesh, an automated framework that is able to convert any rigid 3D mesh into its articulated counterpart in an open-vocabulary manner. Given a 3D mesh, our framework utilizes advanced Vision-Language Models and visual prompting techniques to extract semantic information, allowing for both the segmentation of object parts and the construction of functional joints. Our experiments show that Articulate Anymesh can generate large-scale, high-quality 3D articulated objects, including tools, toys, mechanical devices, and vehicles, significantly expanding the coverage of existing 3D articulated object datasets. Additionally, we show that these generated assets can facilitate the acquisition of new articulated object manipulation skills in simulation, which can then be transferred to a real robotic system. Our Github website is https://articulate-anymesh.github.io.
Architect: Generating Vivid and Interactive 3D Scenes with Hierarchical 2D Inpainting
Nov 14, 2024

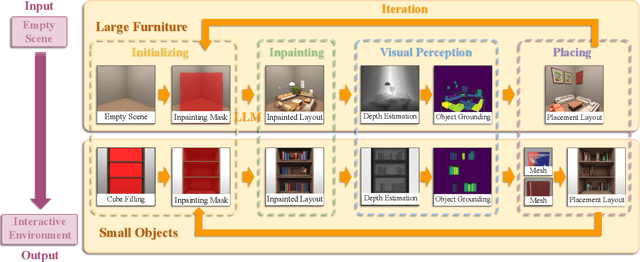
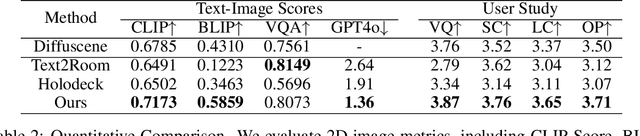
Creating large-scale interactive 3D environments is essential for the development of Robotics and Embodied AI research. Current methods, including manual design, procedural generation, diffusion-based scene generation, and large language model (LLM) guided scene design, are hindered by limitations such as excessive human effort, reliance on predefined rules or training datasets, and limited 3D spatial reasoning ability. Since pre-trained 2D image generative models better capture scene and object configuration than LLMs, we address these challenges by introducing Architect, a generative framework that creates complex and realistic 3D embodied environments leveraging diffusion-based 2D image inpainting. In detail, we utilize foundation visual perception models to obtain each generated object from the image and leverage pre-trained depth estimation models to lift the generated 2D image to 3D space. Our pipeline is further extended to a hierarchical and iterative inpainting process to continuously generate placement of large furniture and small objects to enrich the scene. This iterative structure brings the flexibility for our method to generate or refine scenes from various starting points, such as text, floor plans, or pre-arranged environments.
3D-VLA: A 3D Vision-Language-Action Generative World Model
Mar 14, 2024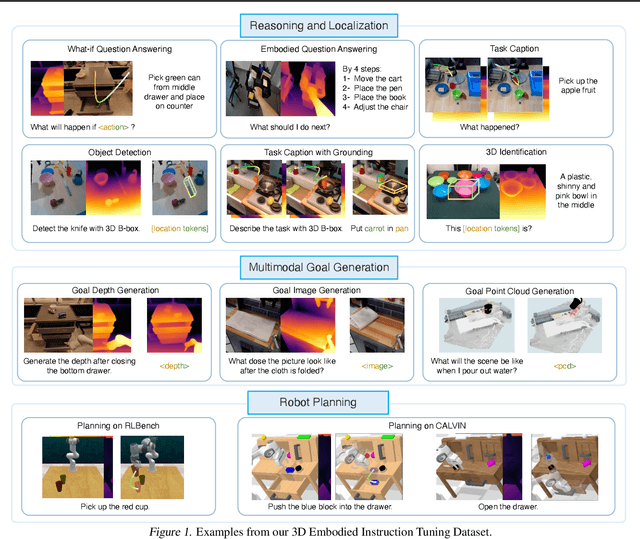
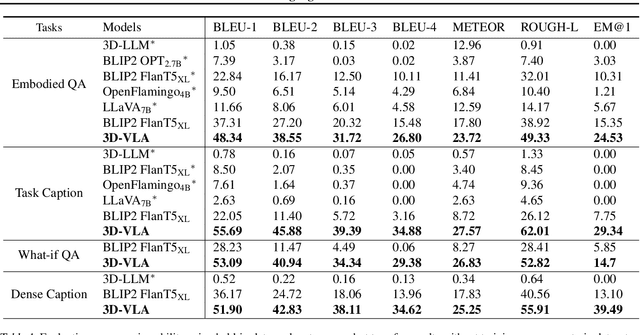
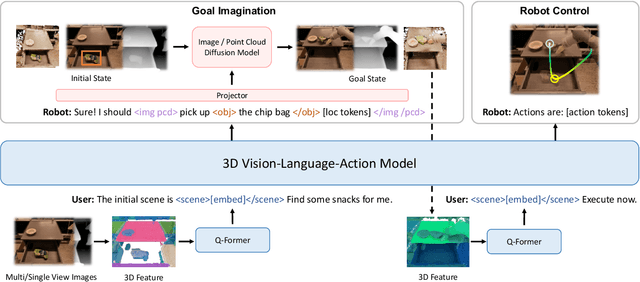
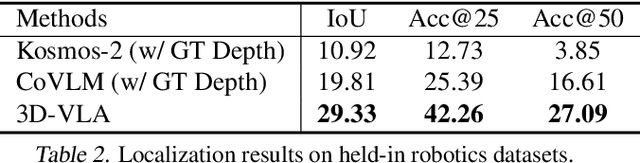
Recent vision-language-action (VLA) models rely on 2D inputs, lacking integration with the broader realm of the 3D physical world. Furthermore, they perform action prediction by learning a direct mapping from perception to action, neglecting the vast dynamics of the world and the relations between actions and dynamics. In contrast, human beings are endowed with world models that depict imagination about future scenarios to plan actions accordingly. To this end, we propose 3D-VLA by introducing a new family of embodied foundation models that seamlessly link 3D perception, reasoning, and action through a generative world model. Specifically, 3D-VLA is built on top of a 3D-based large language model (LLM), and a set of interaction tokens is introduced to engage with the embodied environment. Furthermore, to inject generation abilities into the model, we train a series of embodied diffusion models and align them into the LLM for predicting the goal images and point clouds. To train our 3D-VLA, we curate a large-scale 3D embodied instruction dataset by extracting vast 3D-related information from existing robotics datasets. Our experiments on held-in datasets demonstrate that 3D-VLA significantly improves the reasoning, multimodal generation, and planning capabilities in embodied environments, showcasing its potential in real-world applications.
ColoristaNet for Photorealistic Video Style Transfer
Dec 21, 2022



Photorealistic style transfer aims to transfer the artistic style of an image onto an input image or video while keeping photorealism. In this paper, we think it's the summary statistics matching scheme in existing algorithms that leads to unrealistic stylization. To avoid employing the popular Gram loss, we propose a self-supervised style transfer framework, which contains a style removal part and a style restoration part. The style removal network removes the original image styles, and the style restoration network recovers image styles in a supervised manner. Meanwhile, to address the problems in current feature transformation methods, we propose decoupled instance normalization to decompose feature transformation into style whitening and restylization. It works quite well in ColoristaNet and can transfer image styles efficiently while keeping photorealism. To ensure temporal coherency, we also incorporate optical flow methods and ConvLSTM to embed contextual information. Experiments demonstrates that ColoristaNet can achieve better stylization effects when compared with state-of-the-art algorithms.