 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenAgent: Scaling Text-to-Image Generation via Agentic Multimodal Reasoning
Jan 26, 2026We introduce GenAgent, unifying visual understanding and generation through an agentic multimodal model. Unlike unified models that face expensive training costs and understanding-generation trade-offs, GenAgent decouples these capabilities through an agentic framework: understanding is handled by the multimodal model itself, while generation is achieved by treating image generation models as invokable tools. Crucially, unlike existing modular systems constrained by static pipelines, this design enables autonomous multi-turn interactions where the agent generates multimodal chains-of-thought encompassing reasoning, tool invocation, judgment, and reflection to iteratively refine outputs. We employ a two-stage training strategy: first, cold-start with supervised fine-tuning on high-quality tool invocation and reflection data to bootstrap agent behaviors; second, end-to-end agentic reinforcement learning combining pointwise rewards (final image quality) and pairwise rewards (reflection accuracy), with trajectory resampling for enhanced multi-turn exploration. GenAgent significantly boosts base generator(FLUX.1-dev) performance on GenEval++ (+23.6\%) and WISE (+14\%). Beyond performance gains, our framework demonstrates three key properties: 1) cross-tool generalization to generators with varying capabilities, 2) test-time scaling with consistent improvements across interaction rounds, and 3) task-adaptive reasoning that automatically adjusts to different tasks. Our code will be available at \href{https://github.com/deep-kaixun/GenAgent}{this url}.
Adaptive Attention Distillation for Robust Few-Shot Segmentation under Environmental Perturbations
Jan 07, 2026Few-shot segmentation (FSS) aims to rapidly learn novel class concepts from limited examples to segment specific targets in unseen images, and has been widely applied in areas such as medical diagnosis and industrial inspection. However, existing studies largely overlook the complex environmental factors encountered in real world scenarios-such as illumination, background, and camera viewpoint-which can substantially increase the difficulty of test images. As a result, models trained under laboratory conditions often fall short of practical deployment requirements. To bridge this gap, in this paper, an environment-robust FSS setting is introduced that explicitly incorporates challenging test cases arising from complex environments-such as motion blur, small objects, and camouflaged targets-to enhance model's robustness under realistic, dynamic conditions. An environment robust FSS benchmark (ER-FSS) is established, covering eight datasets across multiple real world scenarios. In addition, an Adaptive Attention Distillation (AAD) method is proposed, which repeatedly contrasts and distills key shared semantics between known (support) and unknown (query) images to derive class-specific attention for novel categories. This strengthens the model's ability to focus on the correct targets in complex environments, thereby improving environmental robustness. Comparative experiments show that AAD improves mIoU by 3.3% - 8.5% across all datasets and settings, demonstrating superior performance and strong generalization. The source code and dataset are available at: https://github.com/guoqianyu-alberta/Adaptive-Attention-Distillation-for-FSS.
RSAgent: Learning to Reason and Act for Text-Guided Segmentation via Multi-Turn Tool Invocations
Dec 30, 2025Text-guided object segmentation requires both cross-modal reasoning and pixel grounding abilities. Most recent methods treat text-guided segmentation as one-shot grounding, where the model predicts pixel prompts in a single forward pass to drive an external segmentor, which limits verification, refocusing and refinement when initial localization is wrong. To address this limitation, we propose RSAgent, an agentic Multimodal Large Language Model (MLLM) which interleaves reasoning and action for segmentation via multi-turn tool invocations. RSAgent queries a segmentation toolbox, observes visual feedback, and revises its spatial hypothesis using historical observations to re-localize targets and iteratively refine masks. We further build a data pipeline to synthesize multi-turn reasoning segmentation trajectories, and train RSAgent with a two-stage framework: cold-start supervised fine-tuning followed by agentic reinforcement learning with fine-grained, task-specific rewards. Extensive experiments show that RSAgent achieves a zero-shot performance of 66.5% gIoU on ReasonSeg test, improving over Seg-Zero-7B by 9%, and reaches 81.5% cIoU on RefCOCOg, demonstrating state-of-the-art performance on both in-domain and out-of-domain benchmarks.
Collaborative Reconstruction and Repair for Multi-class Industrial Anomaly Detection
Dec 12, 2025Industrial anomaly detection is a challenging open-set task that aims to identify unknown anomalous patterns deviating from normal data distribution. To avoid the significant memory consumption and limited generalizability brought by building separate models per class, we focus on developing a unified framework for multi-class anomaly detection. However, under this challenging setting, conventional reconstruction-based networks often suffer from an identity mapping problem, where they directly replicate input features regardless of whether they are normal or anomalous, resulting in detection failures. To address this issue, this study proposes a novel framework termed Collaborative Reconstruction and Repair (CRR), which transforms the reconstruction to repairation. First, we optimize the decoder to reconstruct normal samples while repairing synthesized anomalies. Consequently, it generates distinct representations for anomalous regions and similar representations for normal areas compared to the encoder's output. Second, we implement feature-level random masking to ensure that the representations from decoder contain sufficient local information. Finally, to minimize detection errors arising from the discrepancies between feature representations from the encoder and decoder, we train a segmentation network supervised by synthetic anomaly masks, thereby enhancing localization performance. Extensive experiments on industrial datasets that CRR effectively mitigates the identity mapping issue and achieves state-of-the-art performance in multi-class industrial anomaly detection.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
Commonality in Few: Few-Shot Multimodal Anomaly Detection via Hypergraph-Enhanced Memory
Nov 16, 2025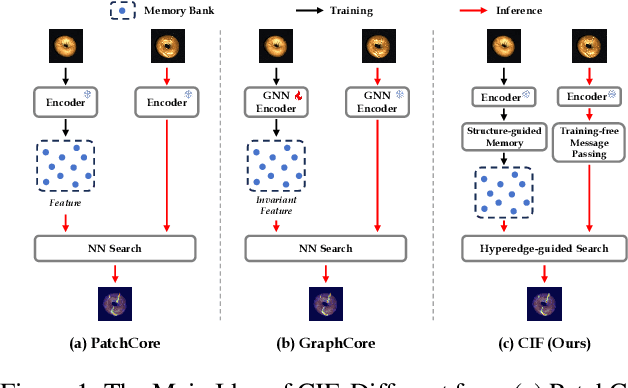
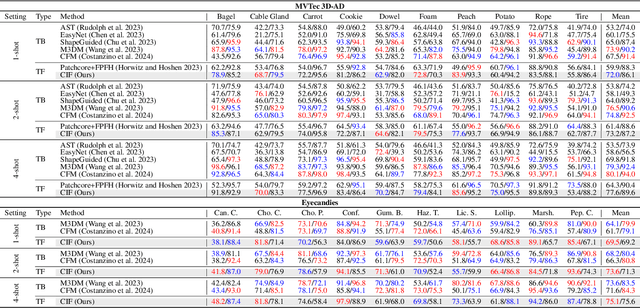
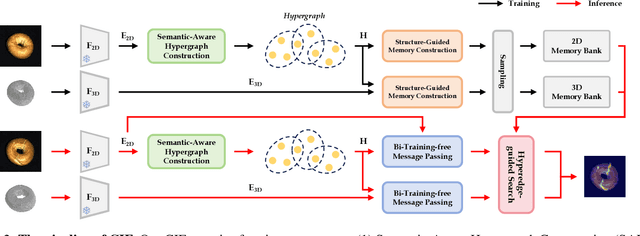

Few-shot multimodal industrial anomaly detection is a critical yet underexplored task, offering the ability to quickly adapt to complex industrial scenarios. In few-shot settings, insufficient training samples often fail to cover the diverse patterns present in test samples. This challenge can be mitigated by extracting structural commonality from a small number of training samples. In this paper, we propose a novel few-shot unsupervised multimodal industrial anomaly detection method based on structural commonality, CIF (Commonality In Few). To extract intra-class structural information, we employ hypergraphs, which are capable of modeling higher-order correlations, to capture the structural commonality within training samples, and use a memory bank to store this intra-class structural prior. Firstly, we design a semantic-aware hypergraph construction module tailored for single-semantic industrial images, from which we extract common structures to guide the construction of the memory bank. Secondly, we use a training-free hypergraph message passing module to update the visual features of test samples, reducing the distribution gap between test features and features in the memory bank. We further propose a hyperedge-guided memory search module, which utilizes structural information to assist the memory search process and reduce the false positive rate. Experimental results on the MVTec 3D-AD dataset and the Eyecandies dataset show that our method outperforms the state-of-the-art (SOTA) methods in few-shot settings. Code is available at https://github.com/Sunny5250/CIF.
Seeing is Believing: Rich-Context Hallucination Detection for MLLMs via Backward Visual Grounding
Nov 15, 2025Multimodal Large Language Models (MLLMs) have unlocked powerful cross-modal capabilities, but still significantly suffer from hallucinations. As such, accurate detection of hallucinations in MLLMs is imperative for ensuring their reliability in practical applications. To this end, guided by the principle of "Seeing is Believing", we introduce VBackChecker, a novel reference-free hallucination detection framework that verifies the consistency of MLLMgenerated responses with visual inputs, by leveraging a pixellevel Grounding LLM equipped with reasoning and referring segmentation capabilities. This reference-free framework not only effectively handles rich-context scenarios, but also offers interpretability. To facilitate this, an innovative pipeline is accordingly designed for generating instruction-tuning data (R-Instruct), featuring rich-context descriptions, grounding masks, and hard negative samples. We further establish R^2 -HalBench, a new hallucination benchmark for MLLMs, which, unlike previous benchmarks, encompasses real-world, rich-context descriptions from 18 MLLMs with high-quality annotations, spanning diverse object-, attribute, and relationship-level details. VBackChecker outperforms prior complex frameworks and achieves state-of-the-art performance on R^2 -HalBench, even rivaling GPT-4o's capabilities in hallucination detection. It also surpasses prior methods in the pixel-level grounding task, achieving over a 10% improvement. All codes, data, and models are available at https://github.com/PinxueGuo/VBackChecker.
Fast Visuomotor Policy for Robotic Manipulation
Oct 14, 2025We present a fast and effective policy framework for robotic manipulation, named Energy Policy, designed for high-frequency robotic tasks and resource-constrained systems. Unlike existing robotic policies, Energy Policy natively predicts multimodal actions in a single forward pass, enabling high-precision manipulation at high speed. The framework is built upon two core components. First, we adopt the energy score as the learning objective to facilitate multimodal action modeling. Second, we introduce an energy MLP to implement the proposed objective while keeping the architecture simple and efficient. We conduct comprehensive experiments in both simulated environments and real-world robotic tasks to evaluate the effectiveness of Energy Policy. The results show that Energy Policy matches or surpasses the performance of state-of-the-art manipulation methods while significantly reducing computational overhead. Notably, on the MimicGen benchmark, Energy Policy achieves superior performance with at a faster inference compared to existing approaches.
LingoLoop Attack: Trapping MLLMs via Linguistic Context and State Entrapment into Endless Loops
Jun 17, 2025Multimodal Large Language Models (MLLMs) have shown great promise but require substantial computational resources during inference. Attackers can exploit this by inducing excessive output, leading to resource exhaustion and service degradation. Prior energy-latency attacks aim to increase generation time by broadly shifting the output token distribution away from the EOS token, but they neglect the influence of token-level Part-of-Speech (POS) characteristics on EOS and sentence-level structural patterns on output counts, limiting their efficacy. To address this, we propose LingoLoop, an attack designed to induce MLLMs to generate excessively verbose and repetitive sequences. First, we find that the POS tag of a token strongly affects the likelihood of generating an EOS token. Based on this insight, we propose a POS-Aware Delay Mechanism to postpone EOS token generation by adjusting attention weights guided by POS information. Second, we identify that constraining output diversity to induce repetitive loops is effective for sustained generation. We introduce a Generative Path Pruning Mechanism that limits the magnitude of hidden states, encouraging the model to produce persistent loops. Extensive experiments demonstrate LingoLoop can increase generated tokens by up to 30 times and energy consumption by a comparable factor on models like Qwen2.5-VL-3B, consistently driving MLLMs towards their maximum generation limits. These findings expose significant MLLMs' vulnerabilities, posing challenges for their reliable deployment. The code will be released publicly following the paper's acceptance.
ForceVLA: Enhancing VLA Models with a Force-aware MoE for Contact-rich Manipulation
May 28, 2025Vision-Language-Action (VLA) models have advanced general-purpose robotic manipulation by leveraging pretrained visual and linguistic representations. However, they struggle with contact-rich tasks that require fine-grained control involving force, especially under visual occlusion or dynamic uncertainty. To address these limitations, we propose \textbf{ForceVLA}, a novel end-to-end manipulation framework that treats external force sensing as a first-class modality within VLA systems. ForceVLA introduces \textbf{FVLMoE}, a force-aware Mixture-of-Experts fusion module that dynamically integrates pretrained visual-language embeddings with real-time 6-axis force feedback during action decoding. This enables context-aware routing across modality-specific experts, enhancing the robot's ability to adapt to subtle contact dynamics. We also introduce \textbf{ForceVLA-Data}, a new dataset comprising synchronized vision, proprioception, and force-torque signals across five contact-rich manipulation tasks. ForceVLA improves average task success by 23.2\% over strong $\pi_0$-based baselines, achieving up to 80\% success in tasks such as plug insertion. Our approach highlights the importance of multimodal integration for dexterous manipulation and sets a new benchmark for physically intelligent robotic control. Code and data will be released at https://sites.google.com/view/forcevla2025.