 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Kernel-Based MDPs from Episodic Preferential Feedback
May 25, 2026Human feedback often arrives as preferences rather than calibrated numeric rewards, motivating reinforcement learning from preferential feedback, also referred to as reinforcement learning from human feedback (RLHF). We present a rigorous theoretical study of preference-only learning in episodic kernel MDPs. In each episode, the learner deploys two policies from a common start state and receives a single binary label indicating which trajectory is preferred, modeled by a Bradley--Terry--Luce link on the difference of cumulative (unobserved) rewards. Under kernel-based assumptions on the reward and transition functions (one of the most general models amenable to theoretical analysis) we develop preference-based value estimation and confidence sets tailored to end-of-episode comparisons. We prove high-probability regret bounds that scale sublinearly in the number of episodes, implying that the value of the learned policy converges to that of the optimal policy.
PeakFocus: Bridging Peak Localization and Intensity Regression via a Unified Multi-Scale Framework for Electricity Load Forecasting
May 20, 2026Electricity load peak forecasting (ELPF), simultaneously predicting peak timing and intensity, is a prerequisite for effective grid scheduling and risk management. However, existing methods face three limitations. First, they adopt a two-stage predict-then-locate paradigm, which severs the link between temporal localization and intensity regression. Second, they still struggle with the multi-scale representation conflict, leading to peak misjudgment and timing misalignment. Third, the lack of explicit peak timing context during intensity regression causes intensity smoothing because predictions are dominated by global smoothing trends. To address these limitations, we propose PeakFocus, a unified framework for ELPF. (i) A Unified Peak-Aware Pipeline (UPAP) utilizes a triple hybrid loss to jointly supervise temporal localization and intensity regression, alongside a tolerance-based evaluation protocol. (ii) A Multi-Scale Mixing Peak Locator (MSM-PL) exploits coarse-grained features to mitigate peak misjudgment caused by local fluctuations, and injects them into fine-grained features via a cascade mechanism to resolve timing misalignment. (iii) A Location-Aware Decoder (LAD) injects peak timing context into the intensity regression process, providing explicit guidance to counteract intensity smoothing and improve peak intensity estimation. Extensive experiments on the public Electricity (ELC) dataset and our industrial-scale World Large-scale Electricity Load (WLEL) dataset show that PeakFocus outperforms baselines in both timing precision and intensity estimation.
CA-YOLO: Cross Attention Empowered YOLO for Biomimetic Localization
Feb 07, 2026In modern complex environments, achieving accurate and efficient target localization is essential in numerous fields. However, existing systems often face limitations in both accuracy and the ability to recognize small targets. In this study, we propose a bionic stabilized localization system based on CA-YOLO, designed to enhance both target localization accuracy and small target recognition capabilities. Acting as the "brain" of the system, the target detection algorithm emulates the visual focusing mechanism of animals by integrating bionic modules into the YOLO backbone network. These modules include the introduction of a small target detection head and the development of a Characteristic Fusion Attention Mechanism (CFAM). Furthermore, drawing inspiration from the human Vestibulo-Ocular Reflex (VOR), a bionic pan-tilt tracking control strategy is developed, which incorporates central positioning, stability optimization, adaptive control coefficient adjustment, and an intelligent recapture function. The experimental results show that CA-YOLO outperforms the original model on standard datasets (COCO and VisDrone), with average accuracy metrics improved by 3.94%and 4.90%, respectively.Further time-sensitive target localization experiments validate the effectiveness and practicality of this bionic stabilized localization system.
Modeling and Control for UAV with Off-center Slung Load
Jan 06, 2026Unmanned aerial vehicle (UAV) with slung load system is a classic air transportation system. In practical applications, the suspension point of the slung load does not always align with the center of mass (CoM) of the UAV due to mission requirements or mechanical interference. This offset creates coupling in the system's nonlinear dynamics which leads to a complicated motion control problem. In existing research, modeling of the system are performed about the UAV's CoM. In this work we use the point of suspension instead. Based on the new model, a cascade control strategy is developed. In the middle-loop controller, the acceleration of the suspension point is used to regulate the swing angle of the slung load without the need for considering the coupling between the slung load and the UAV. Using the off-center reference frame, an inner-loop controller is designed to track the UAV's attitude without the need of simplification on the coupling effects. We prove local exponential stability of the closed-loop using Lyapunov approach. Finally, simulations and experiments are conducted to validate the proposed control system.
ADNP-15: An Open-Source Histopathological Dataset for Neuritic Plaque Segmentation in Human Brain Whole Slide Images with Frequency Domain Image Enhancement for Stain Normalization
May 08, 2025Alzheimer's Disease (AD) is a neurodegenerative disorder characterized by amyloid-beta plaques and tau neurofibrillary tangles, which serve as key histopathological features. The identification and segmentation of these lesions are crucial for understanding AD progression but remain challenging due to the lack of large-scale annotated datasets and the impact of staining variations on automated image analysis. Deep learning has emerged as a powerful tool for pathology image segmentation; however, model performance is significantly influenced by variations in staining characteristics, necessitating effective stain normalization and enhancement techniques. In this study, we address these challenges by introducing an open-source dataset (ADNP-15) of neuritic plaques (i.e., amyloid deposits combined with a crown of dystrophic tau-positive neurites) in human brain whole slide images. We establish a comprehensive benchmark by evaluating five widely adopted deep learning models across four stain normalization techniques, providing deeper insights into their influence on neuritic plaque segmentation. Additionally, we propose a novel image enhancement method that improves segmentation accuracy, particularly in complex tissue structures, by enhancing structural details and mitigating staining inconsistencies. Our experimental results demonstrate that this enhancement strategy significantly boosts model generalization and segmentation accuracy. All datasets and code are open-source, ensuring transparency and reproducibility while enabling further advancements in the field.
Bridging Cognition and Emotion: Empathy-Driven Multimodal Misinformation Detection
Apr 24, 2025In the digital era, social media has become a major conduit for information dissemination, yet it also facilitates the rapid spread of misinformation. Traditional misinformation detection methods primarily focus on surface-level features, overlooking the crucial roles of human empathy in the propagation process. To address this gap, we propose the Dual-Aspect Empathy Framework (DAE), which integrates cognitive and emotional empathy to analyze misinformation from both the creator and reader perspectives. By examining creators' cognitive strategies and emotional appeals, as well as simulating readers' cognitive judgments and emotional responses using Large Language Models (LLMs), DAE offers a more comprehensive and human-centric approach to misinformation detection. Moreover, we further introduce an empathy-aware filtering mechanism to enhance response authenticity and diversity. Experimental results on benchmark datasets demonstrate that DAE outperforms existing methods, providing a novel paradigm for multimodal misinformation detection.
Performance Estimation for Supervised Medical Image Segmentation Models on Unlabeled Data Using UniverSeg
Apr 22, 2025The performance of medical image segmentation models is usually evaluated using metrics like the Dice score and Hausdorff distance, which compare predicted masks to ground truth annotations. However, when applying the model to unseen data, such as in clinical settings, it is often impractical to annotate all the data, making the model's performance uncertain. To address this challenge, we propose the Segmentation Performance Evaluator (SPE), a framework for estimating segmentation models' performance on unlabeled data. This framework is adaptable to various evaluation metrics and model architectures. Experiments on six publicly available datasets across six evaluation metrics including pixel-based metrics such as Dice score and distance-based metrics like HD95, demonstrated the versatility and effectiveness of our approach, achieving a high correlation (0.956$\pm$0.046) and low MAE (0.025$\pm$0.019) compare with real Dice score on the independent test set. These results highlight its ability to reliably estimate model performance without requiring annotations. The SPE framework integrates seamlessly into any model training process without adding training overhead, enabling performance estimation and facilitating the real-world application of medical image segmentation algorithms. The source code is publicly available
Component-aware Unsupervised Logical Anomaly Generation for Industrial Anomaly Detection
Feb 17, 2025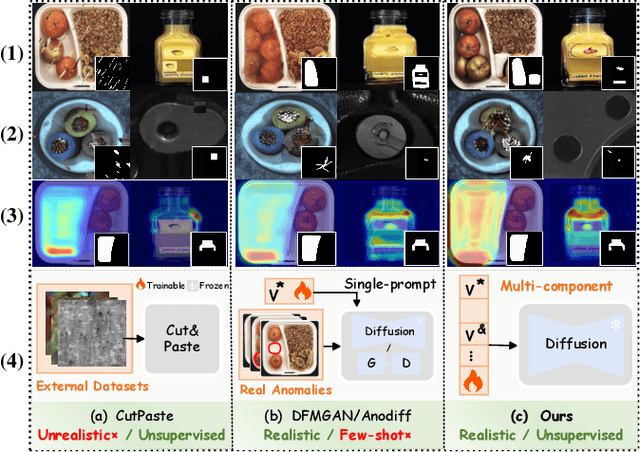
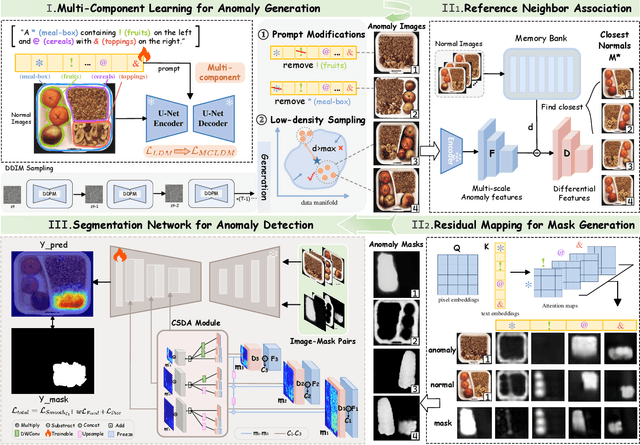
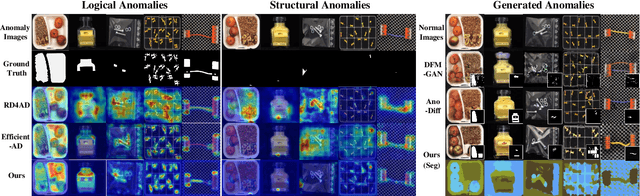

Anomaly detection is critical in industrial manufacturing for ensuring product quality and improving efficiency in automated processes. The scarcity of anomalous samples limits traditional detection methods, making anomaly generation essential for expanding the data repository. However, recent generative models often produce unrealistic anomalies increasing false positives, or require real-world anomaly samples for training. In this work, we treat anomaly generation as a compositional problem and propose ComGEN, a component-aware and unsupervised framework that addresses the gap in logical anomaly generation. Our method comprises a multi-component learning strategy to disentangle visual components, followed by subsequent generation editing procedures. Disentangled text-to-component pairs, revealing intrinsic logical constraints, conduct attention-guided residual mapping and model training with iteratively matched references across multiple scales. Experiments on the MVTecLOCO dataset confirm the efficacy of ComGEN, achieving the best AUROC score of 91.2%. Additional experiments on the real-world scenario of Diesel Engine and widely-used MVTecAD dataset demonstrate significant performance improvements when integrating simulated anomalies generated by ComGEN into automated production workflows.
Comparative Analysis of Pre-trained Deep Learning Models and DINOv2 for Cushing's Syndrome Diagnosis in Facial Analysis
Jan 21, 2025



Cushing's syndrome is a condition caused by excessive glucocorticoid secretion from the adrenal cortex, often manifesting with moon facies and plethora, making facial data crucial for diagnosis. Previous studies have used pre-trained convolutional neural networks (CNNs) for diagnosing Cushing's syndrome using frontal facial images. However, CNNs are better at capturing local features, while Cushing's syndrome often presents with global facial features. Transformer-based models like ViT and SWIN, which utilize self-attention mechanisms, can better capture long-range dependencies and global features. Recently, DINOv2, a foundation model based on visual Transformers, has gained interest. This study compares the performance of various pre-trained models, including CNNs, Transformer-based models, and DINOv2, in diagnosing Cushing's syndrome. We also analyze gender bias and the impact of freezing mechanisms on DINOv2. Our results show that Transformer-based models and DINOv2 outperformed CNNs, with ViT achieving the highest F1 score of 85.74%. Both the pre-trained model and DINOv2 had higher accuracy for female samples. DINOv2 also showed improved performance when freezing parameters. In conclusion, Transformer-based models and DINOv2 are effective for Cushing's syndrome classification.
Deep Learning-Based Feature Fusion for Emotion Analysis and Suicide Risk Differentiation in Chinese Psychological Support Hotlines
Jan 15, 2025



Mental health is a critical global public health issue, and psychological support hotlines play a pivotal role in providing mental health assistance and identifying suicide risks at an early stage. However, the emotional expressions conveyed during these calls remain underexplored in current research. This study introduces a method that combines pitch acoustic features with deep learning-based features to analyze and understand emotions expressed during hotline interactions. Using data from China's largest psychological support hotline, our method achieved an F1-score of 79.13% for negative binary emotion classification.Additionally, the proposed approach was validated on an open dataset for multi-class emotion classification,where it demonstrated better performance compared to the state-of-the-art methods. To explore its clinical relevance, we applied the model to analysis the frequency of negative emotions and the rate of emotional change in the conversation, comparing 46 subjects with suicidal behavior to those without. While the suicidal group exhibited more frequent emotional changes than the non-suicidal group, the difference was not statistically significant.Importantly, our findings suggest that emotional fluctuation intensity and frequency could serve as novel features for psychological assessment scales and suicide risk prediction.The proposed method provides valuable insights into emotional dynamics and has the potential to advance early intervention and improve suicide prevention strategies through integration with clinical tools and assessments The source code is publicly available at https://github.com/Sco-field/Speechemotionrecognition/tree/main.