 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Kernelized Contextual Bandits
Jan 13, 2025We consider the problem of contextual kernel bandits with stochastic contexts, where the underlying reward function belongs to a known Reproducing Kernel Hilbert Space (RKHS). We study this problem under the additional constraint of joint differential privacy, where the agents needs to ensure that the sequence of query points is differentially private with respect to both the sequence of contexts and rewards. We propose a novel algorithm that improves upon the state of the art and achieves an error rate of $\mathcal{O}\left(\sqrt{\frac{\gamma_T}{T}} + \frac{\gamma_T}{T \varepsilon}\right)$ after $T$ queries for a large class of kernel families, where $\gamma_T$ represents the effective dimensionality of the kernel and $\varepsilon > 0$ is the privacy parameter. Our results are based on a novel estimator for the reward function that simultaneously enjoys high utility along with a low-sensitivity to observed rewards and contexts, which is crucial to obtain an order optimal learning performance with improved dependence on the privacy parameter.
Characterizing the Accuracy-Communication-Privacy Trade-off in Distributed Stochastic Convex Optimization
Jan 06, 2025We consider the problem of differentially private stochastic convex optimization (DP-SCO) in a distributed setting with $M$ clients, where each of them has a local dataset of $N$ i.i.d. data samples from an underlying data distribution. The objective is to design an algorithm to minimize a convex population loss using a collaborative effort across $M$ clients, while ensuring the privacy of the local datasets. In this work, we investigate the accuracy-communication-privacy trade-off for this problem. We establish matching converse and achievability results using a novel lower bound and a new algorithm for distributed DP-SCO based on Vaidya's plane cutting method. Thus, our results provide a complete characterization of the accuracy-communication-privacy trade-off for DP-SCO in the distributed setting.
The Sample-Communication Complexity Trade-off in Federated Q-Learning
Aug 30, 2024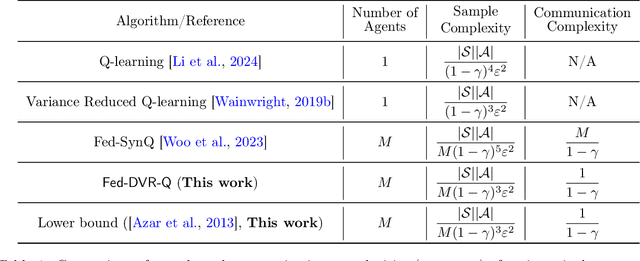


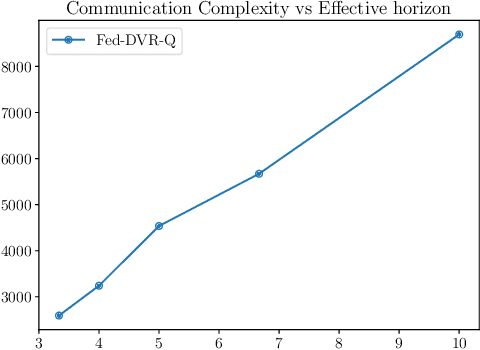
We consider the problem of federated Q-learning, where $M$ agents aim to collaboratively learn the optimal Q-function of an unknown infinite-horizon Markov decision process with finite state and action spaces. We investigate the trade-off between sample and communication complexities for the widely used class of intermittent communication algorithms. We first establish the converse result, where it is shown that a federated Q-learning algorithm that offers any speedup with respect to the number of agents in the per-agent sample complexity needs to incur a communication cost of at least an order of $\frac{1}{1-\gamma}$ up to logarithmic factors, where $\gamma$ is the discount factor. We also propose a new algorithm, called Fed-DVR-Q, which is the first federated Q-learning algorithm to simultaneously achieve order-optimal sample and communication complexities. Thus, together these results provide a complete characterization of the sample-communication complexity trade-off in federated Q-learning.
Order-Optimal Regret in Distributed Kernel Bandits using Uniform Sampling with Shared Randomness
Feb 20, 2024
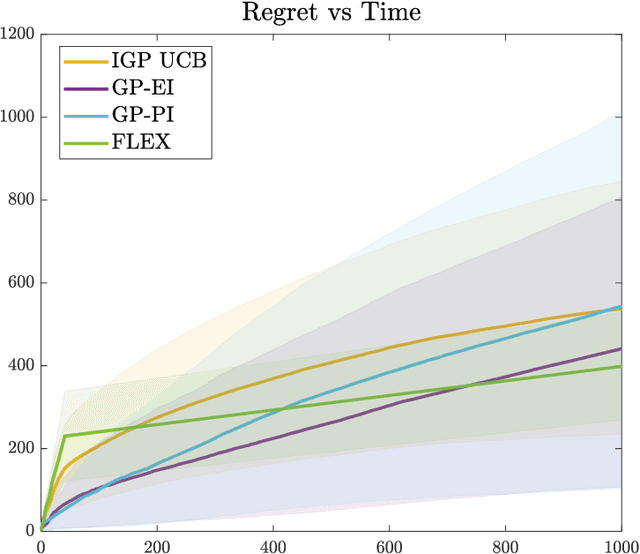
We consider distributed kernel bandits where $N$ agents aim to collaboratively maximize an unknown reward function that lies in a reproducing kernel Hilbert space. Each agent sequentially queries the function to obtain noisy observations at the query points. Agents can share information through a central server, with the objective of minimizing regret that is accumulating over time $T$ and aggregating over agents. We develop the first algorithm that achieves the optimal regret order (as defined by centralized learning) with a communication cost that is sublinear in both $N$ and $T$. The key features of the proposed algorithm are the uniform exploration at the local agents and shared randomness with the central server. Working together with the sparse approximation of the GP model, these two key components make it possible to preserve the learning rate of the centralized setting at a diminishing rate of communication.
Random Exploration in Bayesian Optimization: Order-Optimal Regret and Computational Efficiency
Oct 23, 2023

We consider Bayesian optimization using Gaussian Process models, also referred to as kernel-based bandit optimization. We study the methodology of exploring the domain using random samples drawn from a distribution. We show that this random exploration approach achieves the optimal error rates. Our analysis is based on novel concentration bounds in an infinite dimensional Hilbert space established in this work, which may be of independent interest. We further develop an algorithm based on random exploration with domain shrinking and establish its order-optimal regret guarantees under both noise-free and noisy settings. In the noise-free setting, our analysis closes the existing gap in regret performance and thereby resolves a COLT open problem. The proposed algorithm also enjoys a computational advantage over prevailing methods due to the random exploration that obviates the expensive optimization of a non-convex acquisition function for choosing the query points at each iteration.
A Communication-Efficient Adaptive Algorithm for Federated Learning under Cumulative Regret
Jan 21, 2023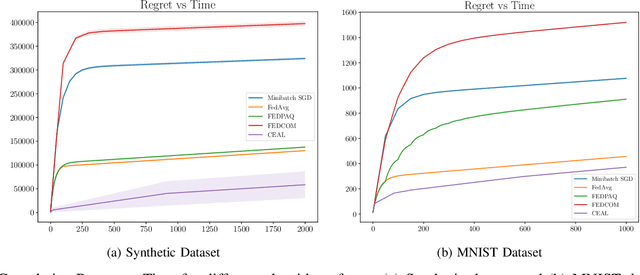
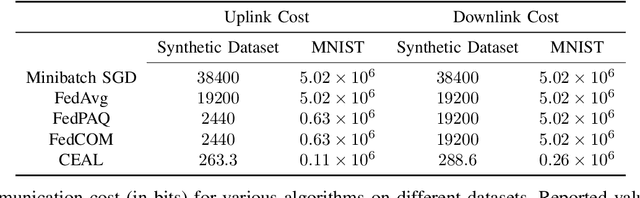
We consider the problem of online stochastic optimization in a distributed setting with $M$ clients connected through a central server. We develop a distributed online learning algorithm that achieves order-optimal cumulative regret with low communication cost measured in the total number of bits transmitted over the entire learning horizon. This is in contrast to existing studies which focus on the offline measure of simple regret for learning efficiency. The holistic measure for communication cost also departs from the prevailing approach that \emph{separately} tackles the communication frequency and the number of bits in each communication round.
Distributed Linear Bandits under Communication Constraints
Nov 04, 2022We consider distributed linear bandits where $M$ agents learn collaboratively to minimize the overall cumulative regret incurred by all agents. Information exchange is facilitated by a central server, and both the uplink and downlink communications are carried over channels with fixed capacity, which limits the amount of information that can be transmitted in each use of the channels. We investigate the regret-communication trade-off by (i) establishing information-theoretic lower bounds on the required communications (in terms of bits) for achieving a sublinear regret order; (ii) developing an efficient algorithm that achieves the minimum sublinear regret order offered by centralized learning using the minimum order of communications dictated by the information-theoretic lower bounds. For sparse linear bandits, we show a variant of the proposed algorithm offers better regret-communication trade-off by leveraging the sparsity of the problem.
Kernel-based Federated Learning with Personalization
Jul 16, 2022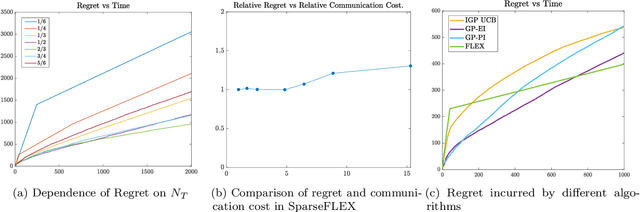
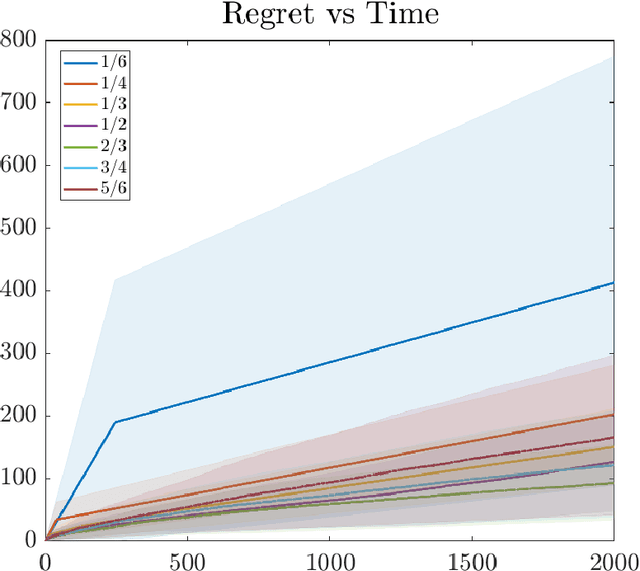
We consider federated learning with personalization, where in addition to a global objective, each client is also interested in maximizing a personalized local objective. We consider this problem under a general continuous action space setting where the objective functions belong to a reproducing kernel Hilbert space. We propose algorithms based on surrogate Gaussian process (GP) models that achieve the optimal regret order (up to polylogarithmic factors). Furthermore, we show that the sparse approximations of the GP models significantly reduce the communication cost across clients.
Provably and Practically Efficient Neural Contextual Bandits
May 31, 2022
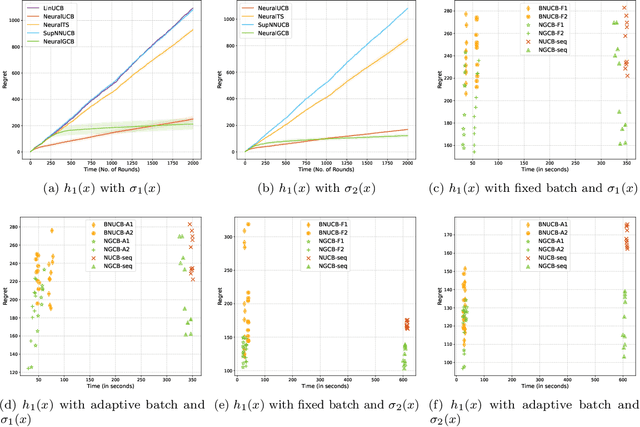


We consider the neural contextual bandit problem. In contrast to the existing work which primarily focuses on ReLU neural nets, we consider a general set of smooth activation functions. Under this more general setting, (i) we derive non-asymptotic error bounds on the difference between an overparameterized neural net and its corresponding neural tangent kernel, (ii) we propose an algorithm with a provably sublinear regret bound that is also efficient in the finite regime as demonstrated by empirical studies. The non-asymptotic error bounds may be of broader interest as a tool to establish the relation between the smoothness of the activation functions in neural contextual bandits and the smoothness of the kernels in kernel bandits.
As Easy as ABC: Adaptive Binning Coincidence Test for Uniformity Testing
Oct 12, 2021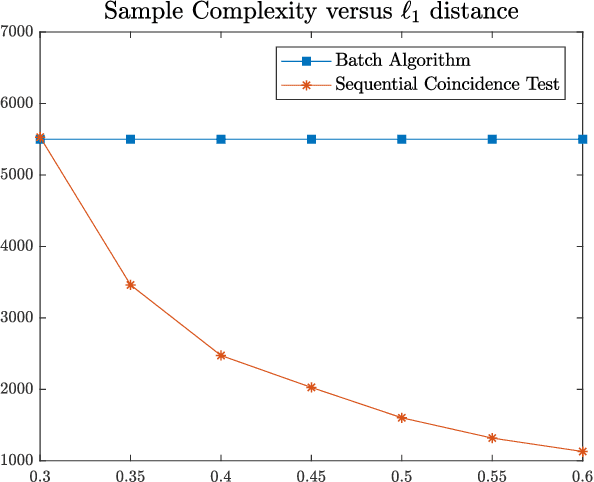
We consider the problem of uniformity testing of Lipschitz continuous distributions with bounded support. The alternative hypothesis is a composite set of Lipschitz continuous distributions that are at least $\varepsilon$ away in $\ell_1$ distance from the uniform distribution. We propose a sequential test that adapts to the unknown distribution under the alternative hypothesis. Referred to as the Adaptive Binning Coincidence (ABC) test, the proposed strategy adapts in two ways. First, it partitions the set of alternative distributions into layers based on their distances to the uniform distribution. It then sequentially eliminates the alternative distributions layer by layer in decreasing distance to the uniform, and subsequently takes advantage of favorable situations of a distant alternative by exiting early. Second, it adapts, across layers of the alternative distributions, the resolution level of the discretization for computing the coincidence statistic. The farther away the layer is from the uniform, the coarser the discretization is needed for eliminating/exiting this layer. It thus exits both early in the detection process and quickly by using a lower resolution to take advantage of favorable alternative distributions. The ABC test builds on a novel sequential coincidence test for discrete distributions, which is of independent interest. We establish the sample complexity of the proposed tests as well as a lower bound.