 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixFlow: Mixture-Conditioned Flow Matching for Out-of-Distribution Generalization
Jan 16, 2026Achieving robust generalization under distribution shift remains a central challenge in conditional generative modeling, as existing conditional flow-based methods often struggle to extrapolate beyond the training conditions. We introduce MixFlow, a conditional flow-matching framework for descriptor-controlled generation that directly targets this limitation by jointly learning a descriptor-conditioned base distribution and a descriptor-conditioned flow field via shortest-path flow matching. By modeling the base distribution as a learnable, descriptor-dependent mixture, MixFlow enables smooth interpolation and extrapolation to unseen conditions, leading to substantially improved out-of-distribution generalization. We provide analytical insights into the behavior of the proposed framework and empirically demonstrate its effectiveness across multiple domains, including prediction of responses to unseen perturbations in single-cell transcriptomic data and high-content microscopy-based drug screening tasks. Across these diverse settings, MixFlow consistently outperforms standard conditional flow-matching baselines. Overall, MixFlow offers a simple yet powerful approach for achieving robust, generalizable, and controllable generative modeling across heterogeneous domains.
Reinforcement Learning Using known Invariances
Nov 05, 2025In many real-world reinforcement learning (RL) problems, the environment exhibits inherent symmetries that can be exploited to improve learning efficiency. This paper develops a theoretical and algorithmic framework for incorporating known group symmetries into kernel-based RL. We propose a symmetry-aware variant of optimistic least-squares value iteration (LSVI), which leverages invariant kernels to encode invariance in both rewards and transition dynamics. Our analysis establishes new bounds on the maximum information gain and covering numbers for invariant RKHSs, explicitly quantifying the sample efficiency gains from symmetry. Empirical results on a customized Frozen Lake environment and a 2D placement design problem confirm the theoretical improvements, demonstrating that symmetry-aware RL achieves significantly better performance than their standard kernel counterparts. These findings highlight the value of structural priors in designing more sample-efficient reinforcement learning algorithms.
No-Regret Thompson Sampling for Finite-Horizon Markov Decision Processes with Gaussian Processes
Oct 23, 2025Thompson sampling (TS) is a powerful and widely used strategy for sequential decision-making, with applications ranging from Bayesian optimization to reinforcement learning (RL). Despite its success, the theoretical foundations of TS remain limited, particularly in settings with complex temporal structure such as RL. We address this gap by establishing no-regret guarantees for TS using models with Gaussian marginal distributions. Specifically, we consider TS in episodic RL with joint Gaussian process (GP) priors over rewards and transitions. We prove a regret bound of $\mathcal{\tilde{O}}(\sqrt{KH\Gamma(KH)})$ over $K$ episodes of horizon $H$, where $\Gamma(\cdot)$ captures the complexity of the GP model. Our analysis addresses several challenges, including the non-Gaussian nature of value functions and the recursive structure of Bellman updates, and extends classical tools such as the elliptical potential lemma to multi-output settings. This work advances the understanding of TS in RL and highlights how structural assumptions and model uncertainty shape its performance in finite-horizon Markov Decision Processes.
Bayesian Optimization from Human Feedback: Near-Optimal Regret Bounds
May 29, 2025Bayesian optimization (BO) with preference-based feedback has recently garnered significant attention due to its emerging applications. We refer to this problem as Bayesian Optimization from Human Feedback (BOHF), which differs from conventional BO by learning the best actions from a reduced feedback model, where only the preference between two actions is revealed to the learner at each time step. The objective is to identify the best action using a limited number of preference queries, typically obtained through costly human feedback. Existing work, which adopts the Bradley-Terry-Luce (BTL) feedback model, provides regret bounds for the performance of several algorithms. In this work, within the same framework we develop tighter performance guarantees. Specifically, we derive regret bounds of $\tilde{\mathcal{O}}(\sqrt{\Gamma(T)T})$, where $\Gamma(T)$ represents the maximum information gain$\unicode{x2014}$a kernel-specific complexity term$\unicode{x2014}$and $T$ is the number of queries. Our results significantly improve upon existing bounds. Notably, for common kernels, we show that the order-optimal sample complexities of conventional BO$\unicode{x2014}$achieved with richer feedback models$\unicode{x2014}$are recovered. In other words, the same number of preferential samples as scalar-valued samples is sufficient to find a nearly optimal solution.
Towards a Foundation Model for Communication Systems
May 20, 2025
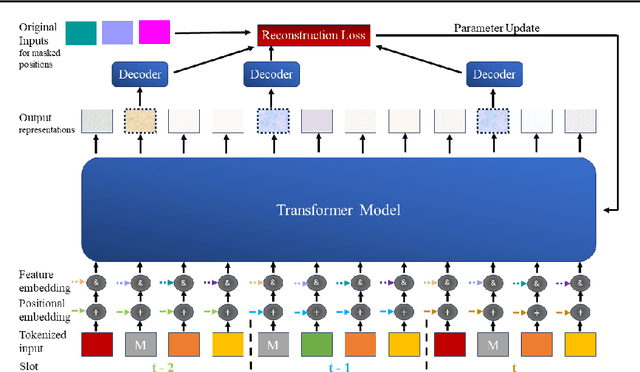
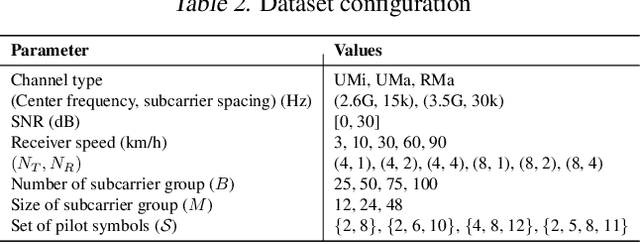
Artificial Intelligence (AI) has demonstrated unprecedented performance across various domains, and its application to communication systems is an active area of research. While current methods focus on task-specific solutions, the broader trend in AI is shifting toward large general models capable of supporting multiple applications. In this work, we take a step toward a foundation model for communication data--a transformer-based, multi-modal model designed to operate directly on communication data. We propose methodologies to address key challenges, including tokenization, positional embedding, multimodality, variable feature sizes, and normalization. Furthermore, we empirically demonstrate that such a model can successfully estimate multiple features, including transmission rank, selected precoder, Doppler spread, and delay profile.
Group Think: Multiple Concurrent Reasoning Agents Collaborating at Token Level Granularity
May 16, 2025Recent advances in large language models (LLMs) have demonstrated the power of reasoning through self-generated chains of thought. Multiple reasoning agents can collaborate to raise joint reasoning quality above individual outcomes. However, such agents typically interact in a turn-based manner, trading increased latency for improved quality. In this paper, we propose Group Think--a single LLM that acts as multiple concurrent reasoning agents, or thinkers. With shared visibility into each other's partial generation progress, Group Think introduces a new concurrent-reasoning paradigm in which multiple reasoning trajectories adapt dynamically to one another at the token level. For example, a reasoning thread may shift its generation mid-sentence upon detecting that another thread is better positioned to continue. This fine-grained, token-level collaboration enables Group Think to reduce redundant reasoning and improve quality while achieving significantly lower latency. Moreover, its concurrent nature allows for efficient utilization of idle computational resources, making it especially suitable for edge inference, where very small batch size often underutilizes local~GPUs. We give a simple and generalizable modification that enables any existing LLM to perform Group Think on a local GPU. We also present an evaluation strategy to benchmark reasoning latency and empirically demonstrate latency improvements using open-source LLMs that were not explicitly trained for Group Think. We hope this work paves the way for future LLMs to exhibit more sophisticated and more efficient collaborative behavior for higher quality generation.
Near-Optimal Sample Complexity in Reward-Free Kernel-Based Reinforcement Learning
Feb 11, 2025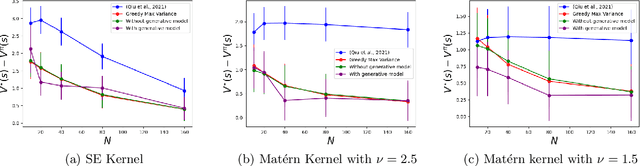

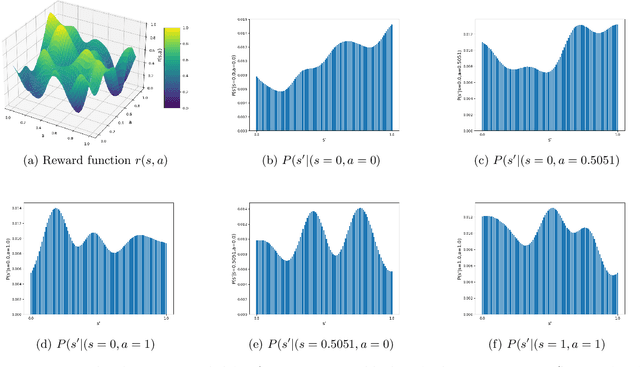
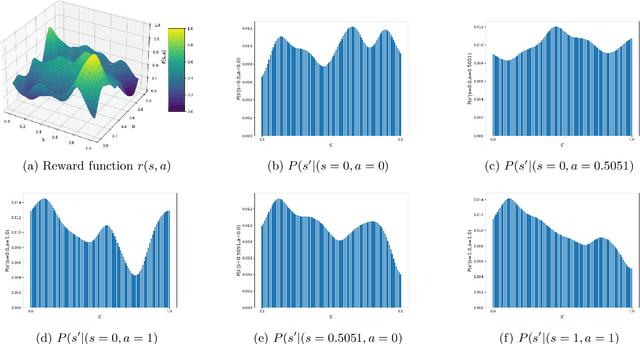
Reinforcement Learning (RL) problems are being considered under increasingly more complex structures. While tabular and linear models have been thoroughly explored, the analytical study of RL under nonlinear function approximation, especially kernel-based models, has recently gained traction for their strong representational capacity and theoretical tractability. In this context, we examine the question of statistical efficiency in kernel-based RL within the reward-free RL framework, specifically asking: how many samples are required to design a near-optimal policy? Existing work addresses this question under restrictive assumptions about the class of kernel functions. We first explore this question by assuming a generative model, then relax this assumption at the cost of increasing the sample complexity by a factor of H, the length of the episode. We tackle this fundamental problem using a broad class of kernels and a simpler algorithm compared to prior work. Our approach derives new confidence intervals for kernel ridge regression, specific to our RL setting, which may be of broader applicability. We further validate our theoretical findings through simulations.
Kernel-Based Function Approximation for Average Reward Reinforcement Learning: An Optimist No-Regret Algorithm
Oct 30, 2024
Reinforcement learning utilizing kernel ridge regression to predict the expected value function represents a powerful method with great representational capacity. This setting is a highly versatile framework amenable to analytical results. We consider kernel-based function approximation for RL in the infinite horizon average reward setting, also referred to as the undiscounted setting. We propose an optimistic algorithm, similar to acquisition function based algorithms in the special case of bandits. We establish novel no-regret performance guarantees for our algorithm, under kernel-based modelling assumptions. Additionally, we derive a novel confidence interval for the kernel-based prediction of the expected value function, applicable across various RL problems.
Open Problem: Order Optimal Regret Bounds for Kernel-Based Reinforcement Learning
Jun 21, 2024Reinforcement Learning (RL) has shown great empirical success in various application domains. The theoretical aspects of the problem have been extensively studied over past decades, particularly under tabular and linear Markov Decision Process structures. Recently, non-linear function approximation using kernel-based prediction has gained traction. This approach is particularly interesting as it naturally extends the linear structure, and helps explain the behavior of neural-network-based models at their infinite width limit. The analytical results however do not adequately address the performance guarantees for this case. We will highlight this open problem, overview existing partial results, and discuss related challenges.
Optimal Regret Bounds for Collaborative Learning in Bandits
Dec 15, 2023We consider regret minimization in a general collaborative multi-agent multi-armed bandit model, in which each agent faces a finite set of arms and may communicate with other agents through a central controller. The optimal arm for each agent in this model is the arm with the largest expected mixed reward, where the mixed reward of each arm is a weighted average of its rewards across all agents, making communication among agents crucial. While near-optimal sample complexities for best arm identification are known under this collaborative model, the question of optimal regret remains open. In this work, we address this problem and propose the first algorithm with order optimal regret bounds under this collaborative bandit model. Furthermore, we show that only a small constant number of expected communication rounds is needed.